背景
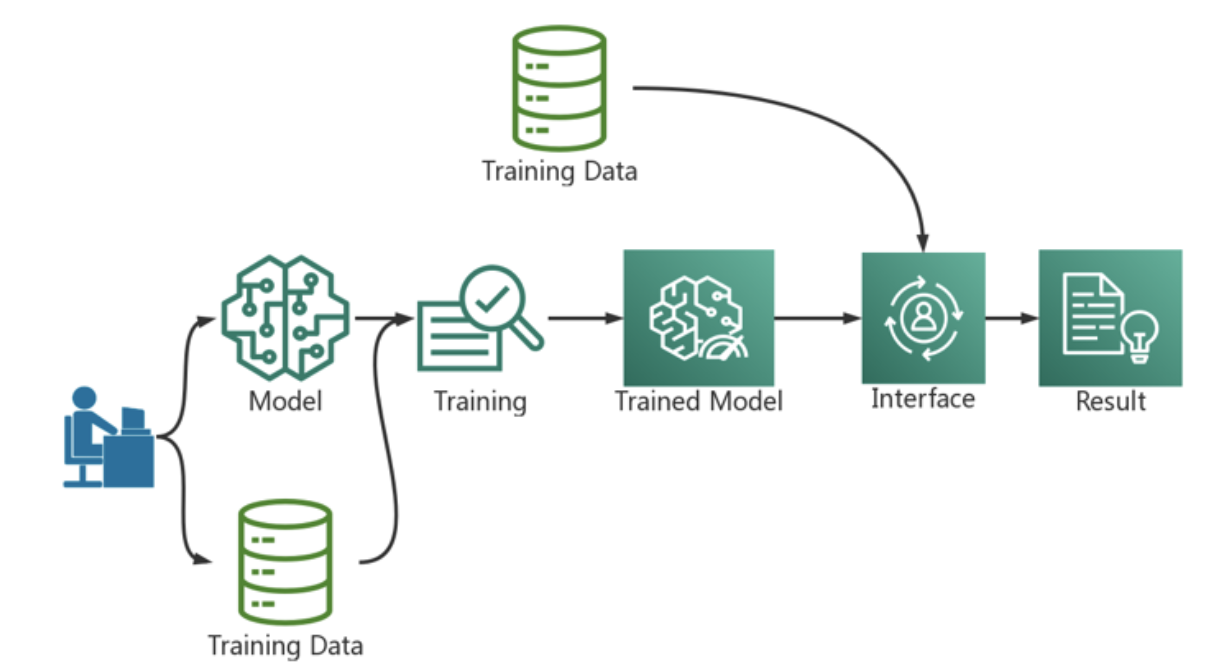
AI开发流程
深度学习大致将涉及数据获取和处理、模型训练和演进、模型部署、模型评测四个阶段[1]。一个企业开始涉猎深度学习之初,因团队缺乏深度学习的相关经验和资源,通常,团队人员选择手工逐步完成上述步骤,以期快速满足项目发展期的即时需求。然而,不管深度学习专家具有多么专业的领域内知识,没有基础设施平台的支撑,项目规模的扩大都变得异常困难。相较于作业的本地运行,生产环境的大规模运行,对产品的快速复制和迭代升级要求更高。生产环境对数据的可靠性,模型训练的可复现,训练模型的扩展性,自动化部署以及运维的可靠性有更高的要求。从而,当企业发展到一定的规模,企业将希望构建稳定的科学计算平台,从而让上层业务人员能够专注于算法优化和业务的发展。
通常,深度学习平台的搭建,将遇到诸多挑战,主要体现在以下方面:
- 数据管理自动化
- 资源的有效利用
- 屏蔽底层技术的复杂性
数据管理
在深度学习的业务场景中,从业人员会花费大量的时间获取和转换建立模型需要的数据。随着业务场景的扩张,数据转换的自动化成为模型构建的效率的瓶颈。数据处理过程中还将产生新的数据,这些数据不单单应用于本次训练,很可能用于后续推理过程。并且新 生成的数据不需要传给数据源,而是希望放置在新的存储空间。这需要基础平台提供可扩展的存储系统。灵活、可扩展且安全的数据存储系统将极大的促进数据管理能力的提升。
资源的有效利用
深度学习相关的应用是资源密集型,资源使用波动大,存在峰值和谷值。在应用开始运行的时候,快速获取计算资源;在应用结束后,回收不适用的计算资源对于资源利用率的提升相当重要。数据处理、模型训练和推理所使用的计算资源类型和资源占用时间有所不同,这就需要计算平台提供弹性的资源供应机制。深度学习任务需要占用大量的计算资源,不可能为每个用户单独构建计算资源,计算平台应该能保证资源使用的多租性,允许多个用户同时使用计算资源池,而不是被少数用户独占。
屏蔽底层技术复杂性
AI的从业人员专注于模型构建和产品研发,忽略基础设施架构对于AI的发展非常重要。机器学习/深度学习自身用户不断发展的技术栈,其中包括TensorFlow等机器学习的计算框架,Spark数据处理引擎和CUDA等底层驱动程序。手动管理这些依赖将消耗从业人员大量的资源和精力。
基于上述目标和挑战,深度学习和其他AI计算选择使用容器和kubernetes来构建和管理深度学习平台。需要实现用户隔离、排队机制、用户权限管理、资源管理、容器上限管理等诸多功能。
常见场景
- 优先级的问题:公司内部算法工程师有众多角色,例如实习生、全职员工、资深工程师,他们做的事情相同,都需要GPU资源去做实验或者训练,但是资源紧张的时候需要按照优先级排队。即便是职位相同,也存在紧急作业(如论文截稿、项目上线)的抢占。任务的优先级别需要工程师申请报备。
- 数据的存储问题:深度学习场景数据集非常大,针对这一需求需要在存储层面进行优化设计。计算的时候,如果是一个人训练一个模型,那么其实简单的存储就 OK 了,但如果有一百个人而且每个人训练的模型、用的数据集都不一样,还需要跑多机任务,这个时候什么样的存储才能帮你解决这个问题?这是摆在我们眼前比较现实的一个问题。针对用户不断扩展的计算需求,存储怎么做适配,这是架构师关注的问题。
- 并行计算:基于k8s的深度学习平台一个通用的需求是支持多机调度,通过多机并行训练让模型训练越快越好。
- 用户隔离问题:对于较大的公司,业务部门众多,需要多用户管理,多租户隔离。
- 深度学习场景下对pod的批量调度需求。
- 资源抢占:对稀缺资源(GPU)占用数量的上限以及使用时间上限。
- 资源预留:屏蔽底层申请资源细节,只关心可用的GPU总量,不关心GPU分布情况。
- 定制化问题:深度学习平台定制化的需求:kubeflow集成了很多组件,但缺点是囊括太多东西,学习成本高,有些场景可能只需要训练不需要Serving,一些公司自己的管理组建和kubeflow对接定制化的组合,会是一个很麻烦的点。每家公司都有不一样的地方,都会根据自己的业务结合基础架构做定制化的东西。其实上面说的1-8条需求都是一种定制化的需求。这个模块也是为了帮助开发者来定制化使用volcano。
推介配置
优先级问题:定制优先级层次。关注job自身的
priorityClassName,该字段表示作业的优先级,在抢占调度和优先级排序中生效。数据存储:在数据库等性能极致的业务中,推介块存储服务。在HPC、大数据、ai的业务场景,推介使用对象存储服务。
高性能计算、模型训练并行性:WRF、kubegene、MPI高性能计算场景、多机并行训练。
1.job plugin:ssh提供免密登陆,svc提供作业运行所需要的网络信息如host文件、headless service等,来提供计算集群参数的自动化配置。
2.policies字段:一旦有pod被杀死,那么重启整个作业RestartJob/CompeletedJob。因为这种HPC场景、基于Gang的训练作业,如果一个worker运行失败,通常来说整个作业运行下去是没什么意义的。
3.这种场景一般会定义多个task,1 master + 多个worker。
多租户、隔离问题:TensorFlow中没有租户的概念。volcano引入的新的资源分割工具
Queue,这在配置中就各种围绕Queue来进行配置。保证集群资源使用的多租性,集群资源有剩余,保证租户使用集群资源的弹性。当集群资源重新划分,通过reclaim 可以保障租户资源配额可用。在volcano-scheduler-configmap的action中配置配置preempt、reclaim,plugins中配置Proportion。批量调度:
Gang plugin满足深度学习场景对pod批量调度的需求。spec字段下minAvailable,Gang调度算法的主要指标。plugins字段需要使用env、svc。policies字段推介RestartJob/CompeletedJob,一个pod驱逐就重启作业。
参考资料: