DRF
Overview
The full name of the DRF scheduling algorithm is Dominant Resource Fairness, which is a scheduling algorithm based on the container group's Dominant Resource. The Dominant Resource is the largest percentage of all required resources for a container group relative to the total cluster resources.
The DRF algorithm selects the container group with the smallest Dominant Resource share for priority scheduling. This approach can accommodate more jobs without allowing a single resource-heavy job to starve a large number of smaller jobs. The DRF scheduling algorithm ensures that in an environment where many types of resources coexist, the fair allocation principle is satisfied as much as possible.
How It Works
The DRF plugin:
- Observes Dominant Resource: For each job, it identifies which resource (CPU, Memory, GPU, etc.) represents the largest share of cluster resources
- Calculates Share Value: Computes each job's share value based on its dominant resource usage
- Prioritizes Lower Share: Jobs with lower share values (using less of their dominant resource) get higher scheduling priority
Key functions implemented:
- JobOrderFn: Orders jobs based on their dominant resource share, giving priority to jobs with smaller shares
- PreemptableFn: Determines if a job can be preempted based on resource fairness calculations
The plugin attempts to calculate the total amount of resources allocated to the preemptor and preempted tasks, triggering preemption when the preemptor task has fewer resources.
Scenario
The DRF scheduling algorithm gives priority to the throughput of businesses in the cluster and is suitable for batch processing scenarios:
AI Training
Single AI training jobs benefit from DRF as it ensures fair resource allocation across multiple training workloads.
Big Data Processing
Single big data calculation and query jobs can share resources fairly with other workloads in the cluster.
Mixed Resource Workloads
In environments with diverse resource requirements (CPU-intensive, Memory-intensive, GPU-intensive jobs), DRF ensures fair allocation across all resource dimensions.
Configuration
The DRF plugin is configured in the scheduler ConfigMap:
tiers:
- plugins:
- name: priority
- name: gang
- plugins:
- name: drf
- name: predicates
- name: proportion
Example
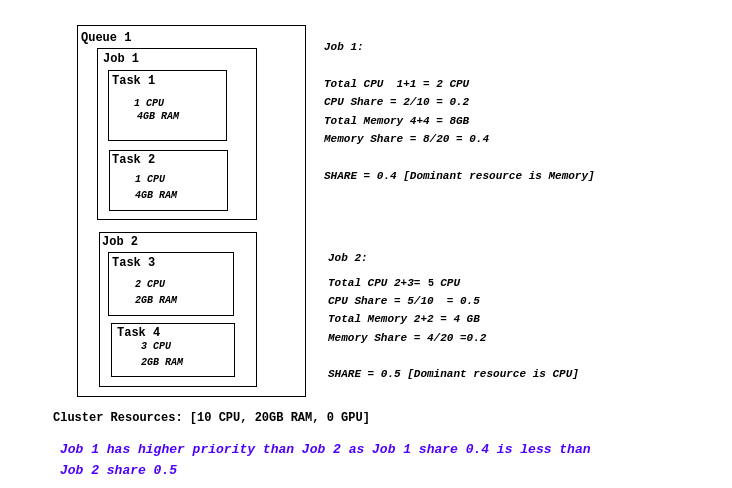
Consider a cluster with the following resources:
- 100 CPUs
- 400 GB Memory
And two jobs:
- Job A: Each task requires 2 CPUs and 8 GB Memory
- Job B: Each task requires 1 CPU and 32 GB Memory
For Job A:
- CPU share per task: 2/100 = 2%
- Memory share per task: 8/400 = 2%
- Dominant resource: CPU and Memory are equal (2%)
For Job B:
- CPU share per task: 1/100 = 1%
- Memory share per task: 32/400 = 8%
- Dominant resource: Memory (8%)
With DRF, Job A would be scheduled first because its dominant resource share (2%) is smaller than Job B's (8%). This ensures that neither job can monopolize the cluster by requesting large amounts of a single resource.
VolcanoJob Example
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: drf-example-job
spec:
schedulerName: volcano
minAvailable: 2
tasks:
- replicas: 2
name: worker
template:
spec:
containers:
- name: worker
image: busybox
resources:
requests:
cpu: "2"
memory: "8Gi"
limits:
cpu: "2"
memory: "8Gi"