本文2021年5月27日首发于容器魔方微信公众号,原文链接小红书基于Volcano的大规模离线与在线推荐模型训练实践
小红书背景介绍
小红书是国内领先的生活分享社区,在女性用户当中比较受欢迎,现在也有越来越多的潮流男生加入了小红书社区,目前月活超过1亿。小红书是一个UGC社区,每天有大概几十万篇的笔记投稿,近百次的笔记曝光量。
首页的推荐功能是小红书的核心业务场景之一。在小红书刚创建的几年当中,推荐是完全人工精选,没有机器学习模型,也不是千人千面,每个人看到的内容都是差不多的。从2016年开始,我们进行千人千面的推荐探索。2018年上线了第一个基于SparkML和GBDT的推荐机器学习模型,大概只有几万个参数。从2018年底开始,我们加速模型的迭代,到2020年下半年,模型规模已经达到了几千亿参数的级别,我们也上线了在线学习,模型可小时级别更新,在今年4月份已达到了分钟级别,用户的行为可以在一两分钟之内被我们模型所抓获,然后产生更加适合用户的推荐,捕捉到用户更短期的兴趣爱好。
小红书搜索推荐广告场景下的大数据架构
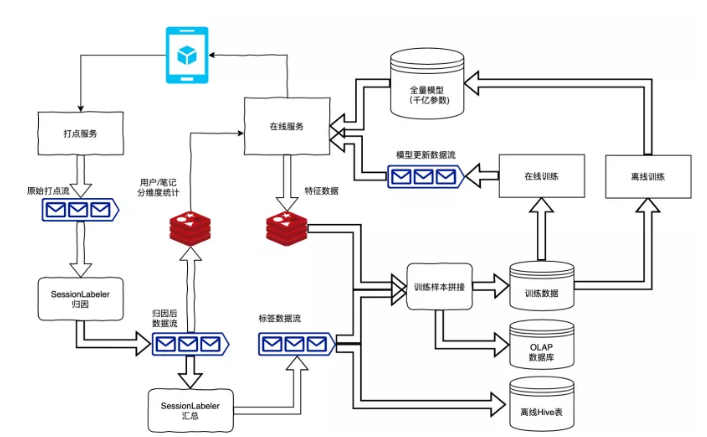
架构可以分为4个部分,左上角是客户端和在线服务与打点服务之间进行交互。用户在打开小红书APP之后,会请求一个在线服务,在线服务进行推荐,把当时推荐的笔记和请求的特征缓存,将推荐结果返回给客户端,用户在浏览推荐给他的笔记过程中,会产生一系列交互行为,交互行为会变成数据流,经过打点服务,落到原始打点数据流。
左下角主要是有两个任务归因和汇总,它们主要是实时的对用户行为做数据清洗和处理,生成标签数据流。标签数据流和测值数据流会做拼接,生成训练样本,同时也会生成我们大数据主要的三个产品,训练数据、OLAP数据库和离线Hive表。
右上角为在线和离线训练的部分,所谓在线训练会实时的对训练数据进行训练,产生模型的更新数据;离线训练会产生一个全量的模型更新到线上。
行为归因和标签
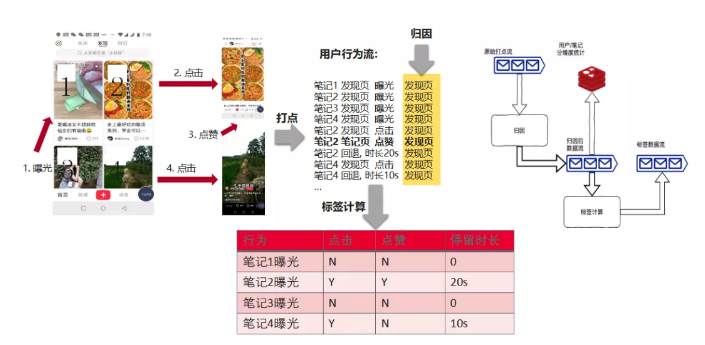
用户行为的归因和标签任务分为两个部分:归因和标签。归因主要是将用户在打点里每个行为和过去发生的行为关联起来。比如我小红书上看了4篇笔记,做了一个点赞,每篇笔记在打点当中其实是发生在不同的地方,比如发现页上面的曝光就会打点到发现页上面,如果用户有一个点赞,这个点赞其实是发生在笔记详情页,它并不是点击进去之后发生的,那么这个点赞其实也可以在不同的渠道发生,用户可能从发现页看到了这篇笔记,点击进去以后进行了点赞,可以是搜索了一些关键词,从搜索结果里进行了这篇笔记的点赞,同样也会进入到笔记详情页面,也可能从博主的个人页发现了这篇笔记点进去。
打点本身其实并没有告诉我们在点赞之前发生了什么,在归因的过程中,我们会根据用户数据行为流,将点赞之前的用户历史浏览记录,从而判断用户点赞行为的原因,补充归因这一列,这个就是归因。另外,用户关注了一个博主,为什么关注这个博主,在关注博主之前,他看过博主的哪些笔记,其实这些也是通过归因任务将这些标签给打上去的。
标签计算和归因相反,是用户产生某个行为之后,他进行了哪些动作,是对之后发生行为的汇总。用户在发现页浏览了4篇笔记,对于每篇笔记我们都会有几个标签,浏览之后有没有发生点击或点赞,如果点击会进入笔记详情页,在页面上停留了多长时间?这些其实都是我们后续模型训练很重要的标签数据,还有平时生成的用户日常报表,也是依赖这份标签数据的。
搜推广的实时大数据产品
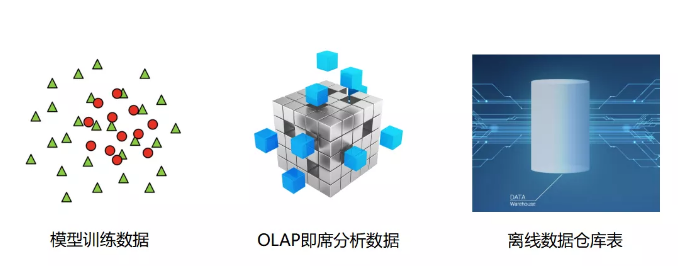
产生标签数据时,大数据其实对于业务而言,主要提供了三个重要的大数据产品:
模型训练数据:用来实时训练模型,给出更加精准与实时的用户最新的兴趣爱好
用来做即席的数据分析和离线仓库,这两个其实都是通过标签数据来做分析,差别是即时分析是有非常实时需求的,比如在系统中做了任何改动与策略上的变化,我是希望能立刻从多维度切分去观测这个变化起了什么作用。而离线数据仓库更多的是日报或者周报,或者过去半年某些指标产生了什么变化。
在线和离线模型训练
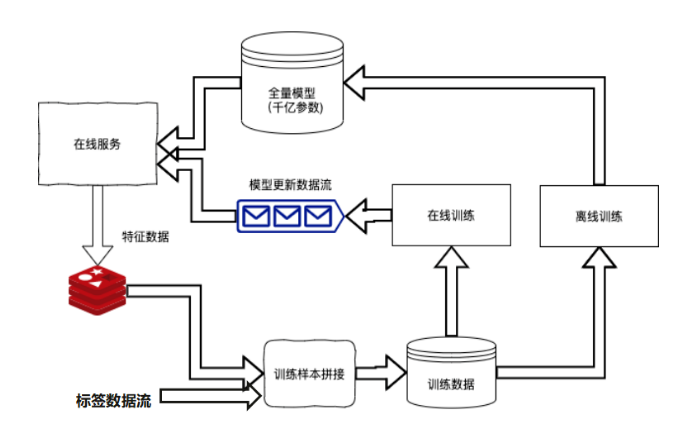
标签数据和特征数据拼接之后产生的训练数据,分别进行离线和在线训练。这里有个差别是离线训练和在线训练用的同一份数据源,拼接之后会放到kafaka,kafaka的数据提供给在线做消费,在线数据消费kafaka后,它其实输出的是一个模型的更新数据流,这里其实是最近上一批次产生的对模型造成变化被实时的发布到在线。离线其实会做批量天级别的训练,会发布一个全量的迁移参数模型,同时更回到线上。
离线批量到在线流式计算的演进?
Offline batch only
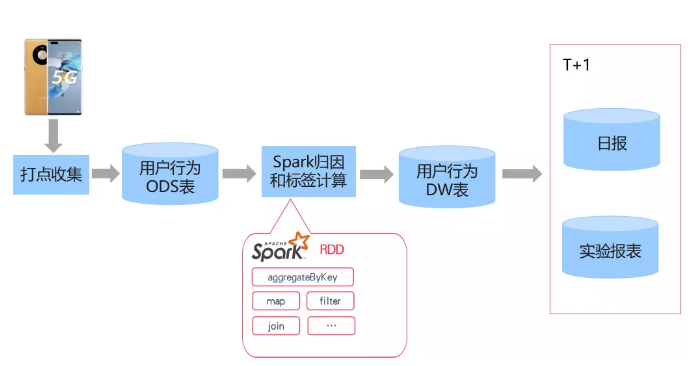
上图为最早的离线批量标签计算流程图,用户发现了点击行为后被收集下来,会落到ODS表,ODS表是原始日志的表,我们是通过Spark任务进行归因和标签计算,这完全是一个离线的批示任务。加工好之后的数据,会形成DW数仓的表,基于DW表我们产生了日报和实验报表的大数据产品。在批量环境下,这个其实是T+1生成的,每次实验的改动,一般到第二天或者第三天才能看完整的报表。
Offline Batch + Online Streaming
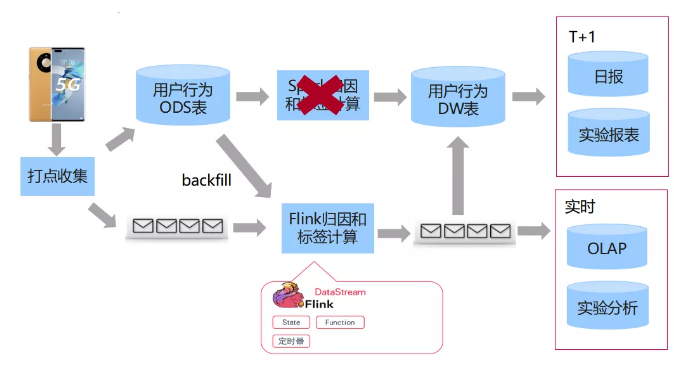
随着开发人员不断变多,对业务的实施性要求也逐渐变高,我们就发现了实时的链路,实时的链路是完全基于Flink框架做的。在实时链路中,它是通过流式kafaka输入,将数据输出到kafaka,同时会落到OLAP数据库和实时实验分析。这里我们有遇到一个挑战,同样的Spark框架和Flink框架,它是两个不同的编程框架。比如要判断某一个广告用户的点击是否是有效点击,这个有效点击的逻辑会稍微复杂一点,因为在点击进去之后,要产生互动行为或至少停留三秒以上,才算有效点击。
如果有两条数据流,往往会在离线实现一个逻辑,同时也会在Flink框架里也实现这样一个逻辑,实际上是同一个逻辑实现两遍会产生很多问题,一是有两份工作量,又要在Spark里开发,又要在Flink里开发。还有一个更大的问题是两边开发之后,逻辑可能会不一样。
对于一些比较复杂的场景会存在差别,最终造成报表和申请不一致。还有一些场景,比如数仓离线提出需求,只在Spark任务里实现了这个逻辑,但在离线没有实现,如果需要查看还要再重新实现,这都会造成额外的工作量。因为我们进行升级更新,所有新的标签不在spark上做计算了,完全在实时这条线进行计算。但实时有可能会出中断的问题,在中断之后,可能会从最新的开始,老的数据可能会产生变动。但离线遇到这种问题就比较简单,将每小时数据重新运行,就会产生一份完整的数据。
我们其实要解决一个技术问题:如何让同样实时的Flink训练任务从离线的数仓表里,转成实时的流表,用同样的计算逻辑生成一份新的数据重回再写回这个表,就保证实时和离线的核心逻辑只在实时实现一份即可,解决了两次开发和我数据逻辑不一致的问题。
Offline Training
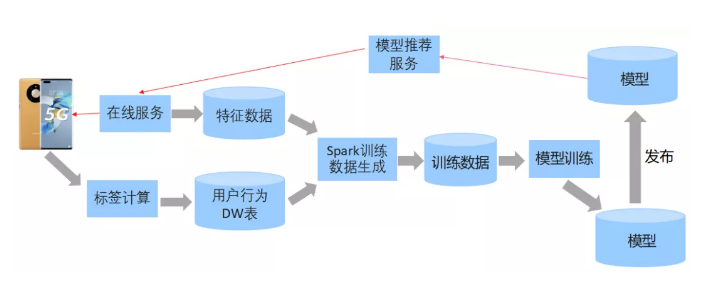
上图为机器学习模型的训练流程。最早也是只有一个批量的数据计算,数据计算是特征数据和用户行为数据都放在离线的表里面,通过Spark任务去做拼接,拼接完之后形成训练任务,然后学习模型发布上线,整个过程可能每天进行一次。
Online + Offline Training
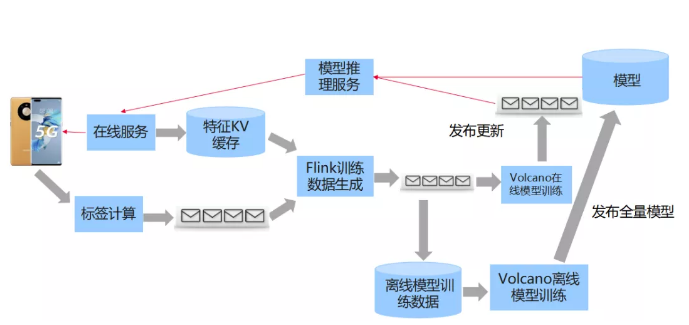
因为要更加快速的捕捉到用户实时兴趣点,同时对于有些新发布的笔记,要更快启动笔记做出判断,因此我们的模型需要做更加实时更新的需求。所以将其改造成通过Flink来做实时的模型训练,Flink生成数据之后,使用Volcano的调度系统进行实时模型和批量模型更新。
离线训练的优化和多云管理
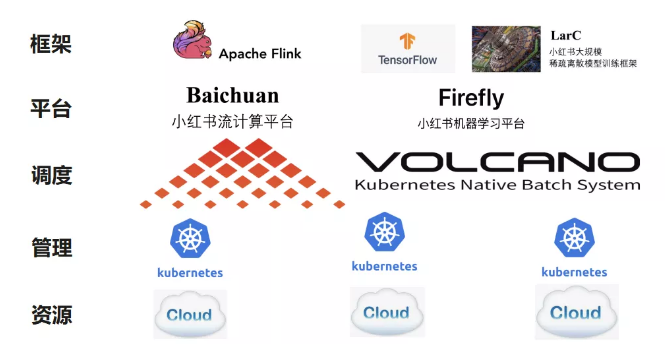
上图为小红书在机器学习和大数据的技术栈。小红书因为是一个比较新的公司,我们没有自建的机房,所有的服务器是买的云厂商的云服务,我们大多数业务都通过Kubernetes来管理的。
我们有两个很重要的平台:一个是内部称为Baichuan的流计算平台,主要用来管理上文提到的实时标签计算与在线学习的Flink任务。还有一个是机器学习的任务管理平台,内部称Firefly。我们是基于TensorFlow开发的一些模型训练,会运行在机器学习平台上,同时针对推荐搜索广告的大规模稀疏离散模型训练场景,也基于TensorFlow研究了自己的训练框架LarC,TensorFlow和LarC的框架模型是通过Firefly运行在机器学习平台上。
中间有非常关键的一层,如何将我们的任务调度到Kubernetes集群上,其实原生的Kubernetes对于这种场景存在一个比较大的问题,它是基于单pod来做调度的。但流计算和机器学习的任务,其实并不是单pod任务,是一组pod的job。因此我们开始有一个比较大的痛点,如果有两个job,每个job都有多个pod需要被调度,如果用原生的Kubernetes调度器,比如有10个资源,但是有两个任务,每个任务都需一个pod,但现在只有15个空闲核,每个任务比如说是10个核,加起来是不够的,但调度单个任务其实是可以。
如果用原生的 k8s去做调度,比如一个任务调度上去7个核,另外1个任务调度上去8个核,一共用了15个核,但每个任务其实不能调度完,所以每个任务都没有办法完成整个调度过程。因为它是基于单pod的,调度上去的时候不会把它撤下来,所以这个集群就会卡死。
基于这些痛点我们去做了一些调研,发现Volcano的前身是Kubernetes batch,可以完全解决我们的痛点。因此,我们也参与到Kubernetes batch社区当中,成为了Volcano的忠实用户。
增强型Volcano调度:binpack->task-topology
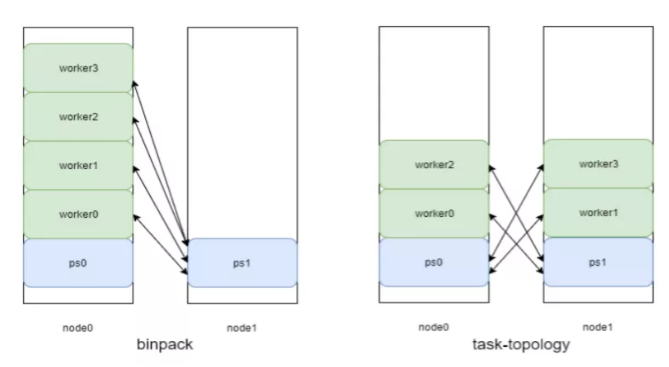
原生的Volcano支持的调度是binpack的算法。在机器学习训练时,训练任务分两类:一类是worker,主要是做前向和反向的计算,是一个计算型的任务。ps主要的任务是存储参数,是一个内存型的服务。如果用原生开源版的 Volcano,它默认支持的调度算法会优化要减少碎片,所以要把尽量多的任务调到同一个node上,然后会把这个任务调成所有work和ps放在一个node上,这个ps放不下,所以只能放在另外一个node上。
这种场景下,会发生worker和某ps0在一台机器上,他们之间 io没有跨机器,就会比较快,存储量也比较大。但是它运行的速度比较慢,因为被一个慢的 ps拖累了。我们发现把任务变成一个平衡的状态,速度均衡之后,它的整体存储是有比较大提升的。从binpack到task-topology的优化,总共能提升大概10%-20%的任务训练的吞吐。
多云之间的数据流转
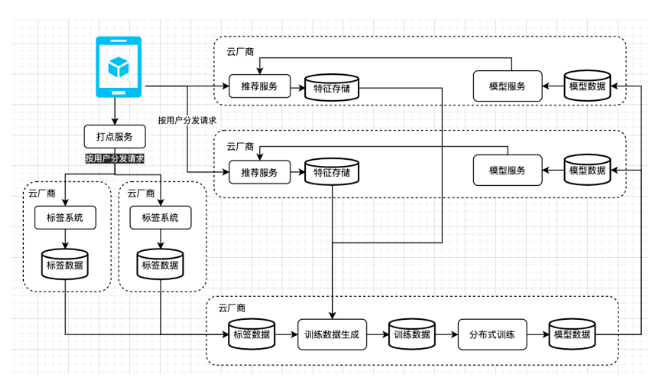
在线上的话,我们会把用户分发到不同的AZ上,推荐服务它的特征缓存会存在本地AZ,在用户打点之后,会根据用户请求将用户分发到不同的集群上,分别对不同的用户做标签系统的计算,最终我们会把所有标签系统计算又流转到为我们提供离线训练和服务的云厂商,去进行数据训练的拼接和生成,同时做分布式的模型训练,训练好的模型再被分发到不同的AZ做线上服务。
怎么在这个架构下面做迁移学习?小红书的用户会在首页做流量,这是产生沉淀大量数据的一个场景。它会训练出来一个千亿级别的模型,那如何让推荐生产出来的大模型让搜索广告都能使用?将推荐的模型训练完之后,会把我们训练的推荐的模型,同步到搜索训练的集群上,在搜索集群训练上用搜索的数据,去发现推荐的模型,最终产生搜索的模型同时被发布到线上。如此在小规模的数据训练场景下,能够拿到训练推荐大模型的特点,使得推荐的大模型能够赋能搜索这个场景。