背景
随着云原生技术的快速发展,越来越多的业务已逐渐迁移到Kubernetes,使用云原生化的方式进行开发维护,极大地简化了应用程序的部署、编排和运维,Kubernetes已逐渐成为云原生时代的“操作系统”。但在另一方面,应用云原生技术之后,数据中心的资源使用率仍然较低,为了提升资源利用率同时保障高优先级业务的SLO,Volcano推出了云原生混部解决方案,从应用层到内核提供端到端的资源隔离与共享机制,最大化提升资源利用率。
云原生混部是指通过云原生的方式将在线业务和离线业务部署在同一个集群。由于在线业务运行具有明显的波峰波谷特征,因此当在线业务运行在波谷时,离线业务可以利用这部分空闲的资源,当在线业务到达波峰时,通过在线作业优先级控制等手段压制离线作业的运行,保障在线作业的资源使用,从而提升集群的整体资源利用率,同时保障在线业务SLO。
典型的在线、离线业务具有如下特征:
| 在线业务 | 离线业务 | |
|---|---|---|
| 典型应用 | 微服务、搜索、推荐、广告等 | 大数据批处理、AI训练、视频转码等 |
| 时延 | 敏感 | 不敏感 |
| SLO | 高 | 低 |
| 负载模型 | 分时性 | 持续占用资源 |
| 错误容忍 | 容忍度低,对可用性要求高 | 允许失败重试 |
| 运行时间 | 稳定持续运行 | 任务型、运行时间短 |
优势
业界有较多的公司和用户对在离线混部技术进行了不同程度的探索与实践,为在离线混部提供了积极有益的设计与实践,但也存在一些不足之处,比如不能做到和Kubernetes完全解耦,超卖资源计算方式粗糙,在离线作业使用方式不一致、用户体验不友好等问题。
基于以上考虑,Volcano针对在离线混部技术进行了进一步的增强与优化,对比业界的在离线混部我们具有如下的优势:
- Volcano Scheduler天然支持离线作业调度与管理。
- 对Kubernetes无侵入式修改。
- 超卖资源实时动态计算,更好地平衡资源利用与与业务QoS需求。
- OS层面的隔离与QoS保障。
架构
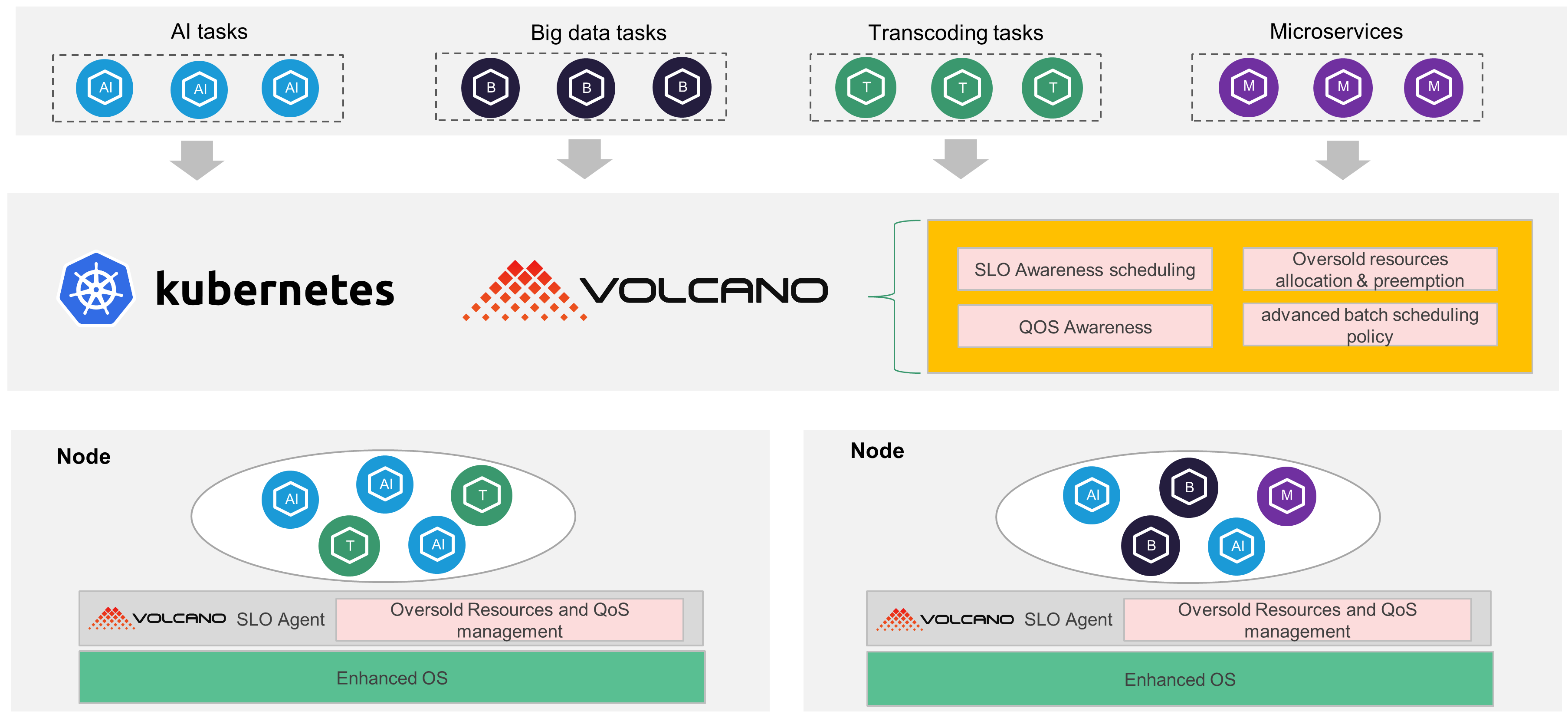
整个云原生混部架构主要包括Volcano Scheduler、Volcano SLO Agent、Enhanced OS几部分。
- Volcano Scheduler:负责在离线作业的统一调度,提供队列、组、作业优先级、公平调度、资源预留等多种抽象,统一满足微服务、大数据、AI等业务调度需求。
- Volcano SLO Agent:集群内的每个节点都会部署一个Volcano SLO Agent,动态实时计算每个节点已经分配但未使用的资源,将这部分资源进行超卖,供离线作业进行使用。同时对节点QoS进行保障,在检测到节点出现CPU/Memory压力时,对离线作业进行驱逐,保障在线业务的优先级。
- Enhanced OS:Volcano SLO Agent在应用层进行节点级别的QoS保证,为了进行更加精细化和强制性的隔离,内核层面也需要区分QoS类型,在CPU/Memory/Network/L3 cache等层面进行隔离,内核暴露了一系列的cgroup接口,Volcano SLO Agent可以为在线和离线业务设置不同的cgroup,做到内核层面的精细隔离,实现在线作业对离线作业的压制。
功能
基于QoS的混部模型
将在线和离线作业混合部署在一个集群之后,由于离线作业通常是CPU或者IO密集型任务,因此会对在线作业造成干扰,导致在线业务QoS受损,为了尽可能降低离线业务对在线业务的干扰,需要对在线和离线业务进行QoS分级管控,通过对在线和离线作业进行标识来定义QoS模型,进而在运行态优先保障在线业务QoS,降低离线作业对在线的干扰。
根据在线和离线作业的分类和运行特点,Volcano对在线和离线作业做了模型抽象,定义了不同的QoS等级,不同类型的业务可以设置不同的QoS等级,同时在内核层面映射到CPU和Memory等级,更高的等级将会获得更高的资源使用权和抢占优先级。在调度时会区分不同QoS等级对应的作业类型,执行丰富的调度策略,同时通过Volcano SLO Agent调用内核接口为在离线作业设置不同的QoS优先级。QoS模型定义如下:
| Qos等级 | 典型应用场景 | CPU优先级 | Memory优先级 |
|---|---|---|---|
| LC(Latency Critical) | 时延敏感极高的核心在线业务,独占CPU | 独占 | 0 |
| HLS(Highly Latency Sensitive) | 时延敏感极高的在线业务 | 2 | 0 |
| LS(Latency Sensitive) | 时延敏感型的近线业务 | 1 | 0 |
| BE(Best Effort) | 离线的AI、大数据业务,可容忍驱逐 | -1 | -1 |
用户可以通过设置作业对应Pod的annotation来表示不同的作业类型,比如设置volcano.sh/qos-level=“LS”,表示Pod为时延敏感型的近线作业,设置volcano.sh/qos-level=“BE”,表示Pod为离线作业。
在离线作业统一调度
将在线和离线作业同时部署在一个集群时,使用多个调度器分别调度不同类型的作业时,每个调度器都可以看到全局的资源视图,多个调度器在进行节点资源计算和绑定时,就极有可能存在并发资源更新冲突,为了避免这一问题,需要用统一的调度器调度在线和离线作业。
Volcano作为业界首个云原生批量计算项目,天然支持AI、Big Data等作业的调度和管理,并且支持多租户的队列管理和公平调度,统一支持几乎所有主流的计算框架,包括Ray 、Kubeflow、Spark、Flink、Pytorch、Tensorflow、MPI、Horovod、MindSpore、PaddlePaddle、MXNet、Argo等。并且集成了K8s默认的调度算法,支持批处理作业和微服务的统一调度,根据作业的QoS模型进行优先级调度。因此支持在线和离线作业的统一调度。
动态资源超卖
Kubernetes现有的资源调度模型基于Pod的requests进行计算,而用户在设置资源requests时往往具有盲目性,requests值设置较大而实际使用量很少,导致资源浪费。同时对于在线作业而言,其运行规律具有明显的波峰波谷特征,因此在业务运行低谷时期,非常适合将未充分使用的资源进行二次超卖,给离线作业使用,从而提升集群的资源利用率。
Volcano SLO Agent实时计算Pod已经申请但未使用的资源,将这部分资源动态超卖给离线作业使用,提高Pod部署密度,提升资源利用率。
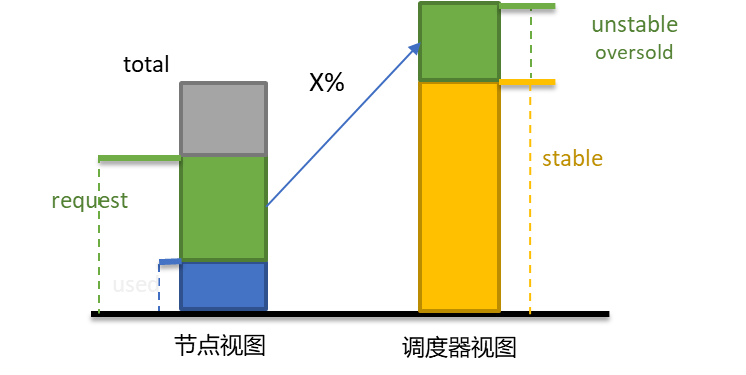
由于超卖资源的增加,改变了节点原有的资源可用量,且超卖资源单独给离线作业使用,因此对于超卖资源的计算、上报方式和使用方式会有不同的方案选择。为了更好地与Kubernetes解耦,以及支持用户自定义设置超卖资源的表现形式,Volcano提供了native、extend等超卖资源计算和上报模式,native的模式会上报超卖资源至节点的allocatable字段,这样一来在线和离线作业的使用方式是一致的,提升了用户体验 ,而extend模式支持将超卖资源以扩展方式上报至节点,做到和Kubernetes的解耦,用户可以根据实际需求灵活选择超卖资源的上报和使用方式。
QoS保障
将在线和离线作业混合部署后,由于离线作业和在线作业会发生资源争用,离线作业会对在线业务造成干扰,因此在资源利用率提升的同时还需要保障在线作业的QoS,避免离线业务对在线业务的干扰。
在离线作业通常会使用多种不同维度的资源,因此需要对各个维度的资源设置资源隔离措施,Volcano会通过内核态接口设置CPU、Memory、Network等维度的资源隔离,当在离线作业发生资源争用时,压制离线作业的资源使用,优先保障在线作业QoS。
CPU: OS层面提供了5级CPU QoS等级,数值从-2到2,QoS等级越高则代表可以获得更多的CPU时间片并有更高的抢占优先级。通过设置cpu子系统的cgroup cpu.qos_level可以为不同业务设置不用的CPU QoS。
Memory: Memory隔离体现在系统发生OOM时离线作业会被有限OOM Kill掉,通过设置memory子系统的cgroup memory.qos_level可以为不同业务设置不同的Memory QoS。
Network: 网络隔离实现了对在线作业的出口网络带宽保障,它基于整机的带宽大小,并通过cgroup + tc + ebpf技术,实现在线作业对离线作业的出口网络带宽压制。
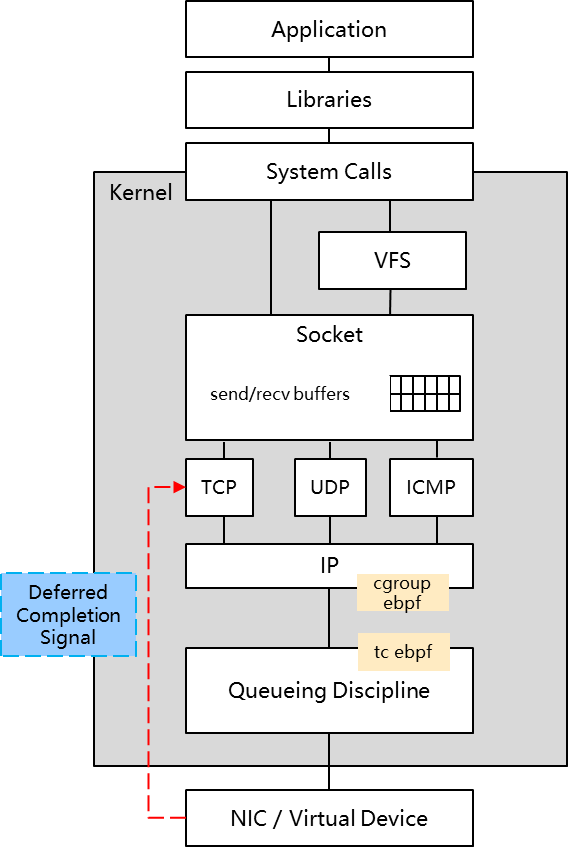
上图为网络隔离的技术方案,通过ebpf将限速程序注入到kernel,实现对报文转发的控制,从而达到限速的目的。cgroup ebpf可以为在离线业务的的报文设置不同的标签以区分在线和离线业务流量,tc ebpf可以设置三个水位线:在线业务水位线,离线业务高水位线和离线业务低水位线。当在线业务流量超过水位线时,限制离线作水位带宽,离线业务带宽使用上限为离线业务低水位线,避让在线流量;当在线业务流量低于水位线时,放开对离线作业的带宽限制,离线业务带宽使用上限为离线业务高水位线,提高资源利用率,同时可以根据离线流量带宽计算报文的发送时间(EDT),实现离线作业流量限速。
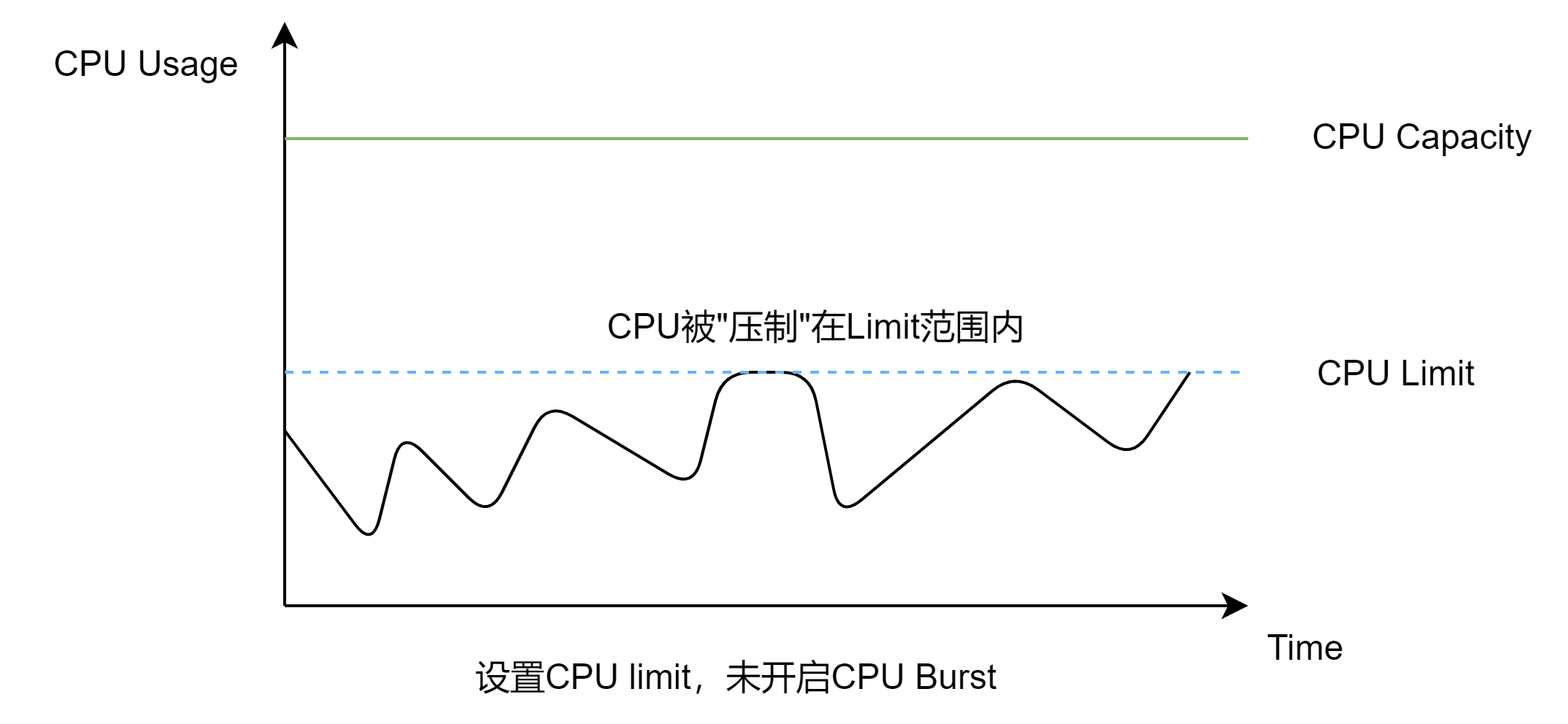
CPU Burst
若Pod中容器设置了CPU Limit值,则该容器CPU使用将会被限制在Limit值以内,形成对CPU的限流。频繁的CPU限流会影响业务性能,增大业务长尾响应时延,对于时延敏感型业务的影响尤为明显。
Volcano agent的CPU Burst能力提供了一种可以短暂突破CPU Limit值的弹性限流机制,以降低业务长尾响应时间。其原理是业务在每个CPU调度周期内使用的CPU配额有剩余时,系统对这些CPU配额进行累计,在后续的调度周期内如果需要突破CPU Limit时,使用之前累计的CPU配额,以达到突破CPU Limit的效果。
当未开启CPU Burst时,容器可以使用的CPU配额会被限制在Limit以内,无法实现Burst。如下图所示:
开启CPU Burst后,容器使用的CPU配额可以突破Limit限制,实现Burst。如下图所示:
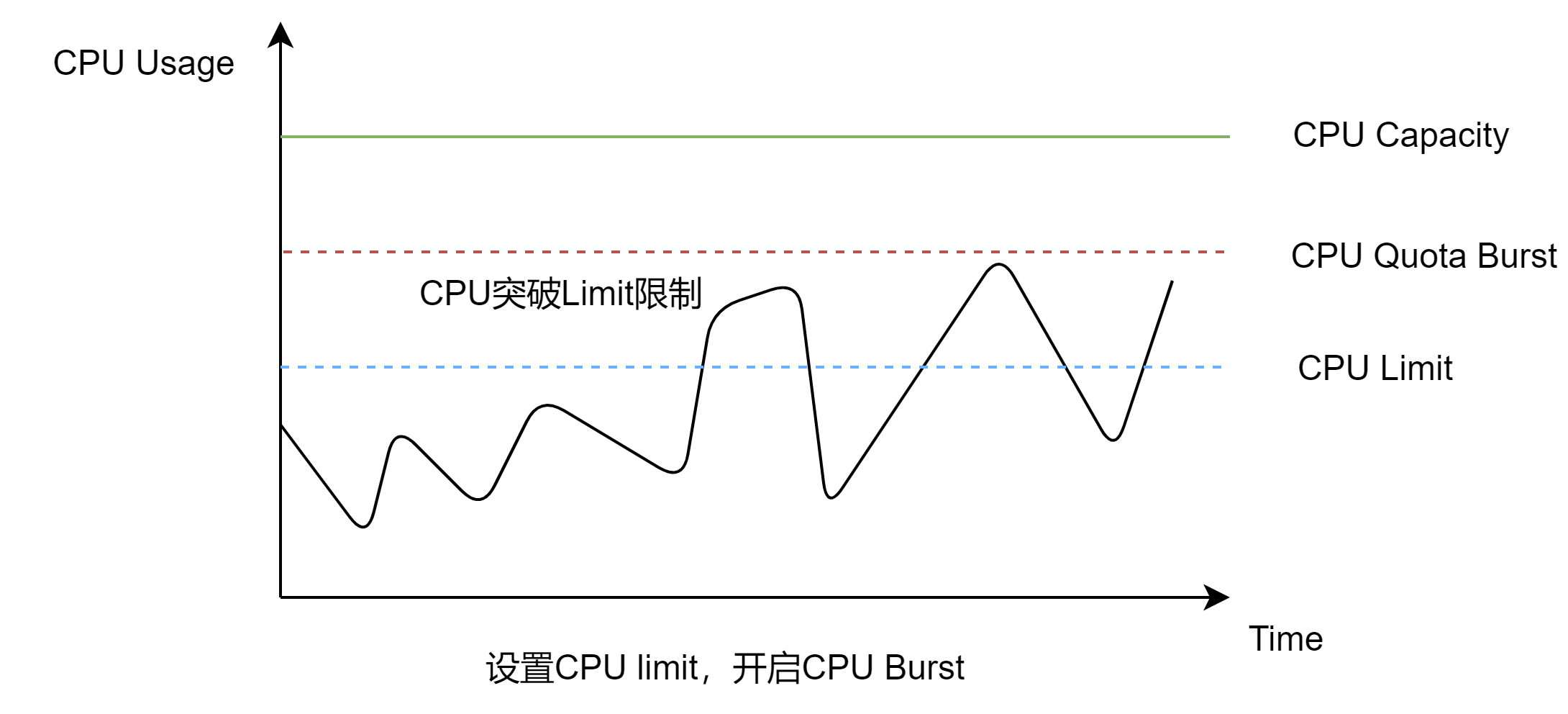
通过Volcano agent提供的CPU Burst能力,可以避免高优业务在关键时刻被限流,保障时延敏感型业务的稳定性。
使用指导
安装Volcano agent
通过 Helm 安装
helm repo add volcano-sh https://volcano-sh.github.io/helm-charts
helm repo update
helm install volcano volcano-sh/volcano -n volcano-system --create-namespace --set custom.colocation_enable=true
通过 Yaml 安装
请按照该文档安装Volcano,然后通过以下命令安装Volcano agent。
kubectl apply -f https://raw.githubusercontent.com/volcano-sh/volcano/master/installer/volcano-agent-development.yaml
并检查Volcano所有组件已成功运行。
kubectl get po -n volcano-system
NAME READY STATUS RESTARTS AGE
volcano-admission-76bd985b56-fnpjg 1/1 Running 0 3d
volcano-admission-init-wmxc7 0/1 Completed 0 3d
volcano-agent-q85jn 1/1 Running 0 3d
volcano-controllers-7655bb499f-gpg9l 1/1 Running 0 3d
volcano-scheduler-6bf4759c45-c666z 1/1 Running 0 3d
通过设置标签的方式,在节点级别打开混部和超卖开关。
kubectl label node $node volcano.sh/oversubscription=true # replace $node with real node name in your kubernetes cluster.
kubectl label node $node volcano.sh/colocation=true # replace $node with real node name in your kubernetes cluster.
CPU Burst示例
该示例将演示如何使用 CPU Burst 及它带来的收益。
开启CPU Burst
部署一个Deploment并暴露类型为 Cluster IP 的service,Pod 的注解 volcano.sh/enable-quota-burst: "true" 表示为 Pod 开启CPU Burst功能。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
annotations:
volcano.sh/enable-quota-burst: "true" # pod enabled cpu burst
spec:
containers:
- name: container-1
image: nginx:latest
resources:
limits:
cpu: "2"
requests:
cpu: "1"
---
apiVersion: v1
kind: Service
metadata:
name: nginx
namespace: default
labels:
app: nginx
spec:
selector:
app: nginx
ports:
- name: http
targetPort: 80
port: 80
protocol: TCP
type: ClusterIP
进行压力测试
使用stress工具为nginx Pod加压。
wrk -H "Accept-Encoding: deflate, gzip" -t 2 -c 8 -d 120 --latency --timeout 2s http://$(kubectl get svc nginx -o jsonpath='{.spec.clusterIP}')
检查CPU限流情况
检查 Pod 容器的 CPU 限流状态,我们可以看到 nr_bursts 和 burst_time 不为 0,而 nr_throttled 和 throttled_time 是一个较小的值,这表明 Pod 已经使用了突发的 CPU 配额。
cat /sys/fs/cgroup/cpu/kubepods/burstable/podd2988e14-83bc-4d3d-931a-59f8a3174396/cpu.stat # replace nginx pod uid in your kubernetes cluster.
nr_periods 1210
nr_throttled 9
throttled_time 193613865
nr_bursts 448
burst_time 6543701690
如果我们设置 Pod 的注解 volcano.sh/enable-quota-burst=false(禁用 Pod 的 CPU Burst)并进行另一次压力测试,nr_throttled 和 throttled_time 将会是一个相对较大的值,这表明 Pod 的 CPU 被严格限制;而 nr_bursts 和 burst_time 为 0,表明 Pod 的 CPU Burst 没有发生。
cat /sys/fs/cgroup/cpu/kubepods/burstable/podeeb542c6-b667-4da4-9ac9-86ced4e93fbb/cpu.stat #replace nginx pod uid in your kubernetes cluster.
nr_periods 1210
nr_throttled 488
throttled_time 10125826283
nr_bursts 0
burst_time 0
说明
CPU Burst 依赖于 Linux 内核提供的功能,该特性仅在主机使用的 Linux 内核版本 >= 5.14 以及某些 Linux 发行版(如 OpenEuler 22.03 SP2 或更高版本)上生效。
动态资源超卖示例
本示例将演示节点上的动态资源能力,并展示节点在面临资源压力时的压制和驱逐机制。节点的配置为 8 核 CPU 和 16GB 内存。
检查节点超卖资源
节点的超卖资源是通过节点的可分配资源(Allocatable)减去实际资源使用量得到的。超卖资源包括 CPU 和内存,分别由 kubernetes.io/batch-cpu 和 kubernetes.io/batch-memory 表示,并作为扩展资源上报到节点的 Allocatable 字段中。在线任务使用原生资源(cpu 和 memory),而离线任务使用超卖资源(kubernetes.io/batch-cpu 和 kubernetes.io/batch-memory),这样可以提高 Pod 的部署密度和资源利用率。
kubectl describe node $node # 将$node替换为群集中的真实节点
Allocatable:
cpu: 8
ephemeral-storage: 33042054704
hugepages-1Gi: 0
hugepages-2Mi: 0
kubernetes.io/batch-cpu: 7937 # CPU超卖资源,单位为毫核cpu(1核CPU=1000毫核CPU)
kubernetes.io/batch-memory: 14327175770 # emory超卖资源, 单位为字节
memory: 15754924Ki
pods: 110
部署在线和离线作业
在线作业通过设置注解 volcano.sh/qos-level: "LC"、volcano.sh/qos-level: "HLS" 或 volcano.sh/qos-level: "LS" 来标识。离线作业通过设置注解 volcano.sh/qos-level: "BE" 来标识,它只能使用超分配资源(kubernetes.io/batch-cpu 和 kubernetes.io/batch-memory)。我们使用一个包含 stress 工具的镜像来模拟在线作业的业务压力上升。如果你无法访问该镜像,也可以替换为其他包含 stress 工具的镜像。
# 在线作业
apiVersion: apps/v1
kind: Deployment
metadata:
name: online-demo
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: online-demo
template:
metadata:
labels:
app: online-demo
annotations:
volcano.sh/qos-level: "HLS" # 标识在线作业
spec:
containers:
- name: container-1
image: polinux/stress
imagePullPolicy: IfNotPresent
command: ["stress", "--cpu", "7"] # 执行stress压测
resources:
requests:
cpu: 2
---
# 离线作业
apiVersion: apps/v1
kind: Deployment
metadata:
name: offline-demo
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: offline-demo
template:
metadata:
labels:
app: offline-demo
annotations:
volcano.sh/qos-level: "BE" # 标识离线作业
spec:
containers:
- name: container-1
image: nginx:latest
resources:
requests:
kubernetes.io/batch-cpu: 4000 # 4核CPU
kubernetes.io/batch-memory: 10737418240 # 10Gi内存
确保在线作业和离线作业成功运行
kubectl get po
NAME READY STATUS RESTARTS AGE
offline-demo-f59758bb-vlbp7 1/1 Running 0 6s
online-demo-9f9bbdb58-fljzs 1/1 Running 0 6s
节点压力下的驱逐机制
当节点出现压力,资源资源利用率达到设定的阈值时,会触发驱逐机制。在线作业的 QoS(服务质量)由 Volcano Agent 和 主机操作系统 共同保障。Volcano Agent 会实时检测节点的资源利用率,当节点资源利用率超过阈值时,会驱逐离线作业。对于 CPU 资源,默认阈值是 80%。我们通过为在线作业施加 7 核 CPU 压力 来模拟资源压力,大约 1 分钟后,可以通过事件日志观察到离线作业被驱逐。
kubectl get event | grep Evicted
69s Warning Evicted pod/offline-demo-785cff7f58-gwqwc Evict offline pod due to cpu resource pressure
当节点资源压力上升时,我们可以观察到超卖资源(kubernetes.io/batch-cpu 和 kubernetes.io/batch-memory)会减少。这是因为超卖资源是通过节点的可分配资源减去实际资源使用量计算得出的。当在线或者离线作业的资源使用量增加时,节点的可用资源减少,从而导致超卖资源也随之减少。
kubectl describe node $node # 将$node替换为群集中的真实节点
Allocatable:
cpu: 8
ephemeral-storage: 33042054704
hugepages-1Gi: 0
hugepages-2Mi: 0
kubernetes.io/batch-cpu: 978 # CPU超卖资源减少
kubernetes.io/batch-memory: 14310391443
memory: 15754924Ki
pods: 110
当驱逐发生时,Volcano Agent 会为当前节点添加一个驱逐污点(Eviction Taint),以避免新的工作负载继续调度到该节点,从而避免给已经处于压力下的节点增加额外的负担。我们可以观察到,新创建的离线作业 Pod 会因为该驱逐污点而处于 Pending 状态。
kubectl get po
NAME READY STATUS RESTARTS AGE
offline-demo-f59758bb-kwb54 0/1 Pending 0 58s
online-demo-9f9bbdb58-54fnx 1/1 Running 0 2m1s
kubectl describe po offline-demo-f59758bb-kwb54
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 69s default-scheduler 0/1 nodes are available: 1 node(s) had taint {volcano.sh/offline-job-evicting: }, that the pod didn't tolerate.
如果停止在线作业以释放节点的资源压力,Volcano Agent 会检测到节点资源利用率下降,并自动移除驱逐污点(Eviction Taint)。一旦污点被移除,新的 Pod 就可以正常调度到该节点上。
说明
Volcano Agent 为在线作业和离线作业定义了一个 QoS(服务质量)资源模型,并为在线作业提供了应用级别的保障机制(例如在节点资源压力下驱逐离线作业)。同时,CPU 和内存的隔离与抑制由主机内核(Host Kernel)在操作系统级别提供保障。需要注意的是,目前 Volcano Agent 仅适配 openEuler 22.03 SP2 及更高版本,因此使用该功能时请确保使用正确的操作系统类型和版本。
出口网络带宽保障示例
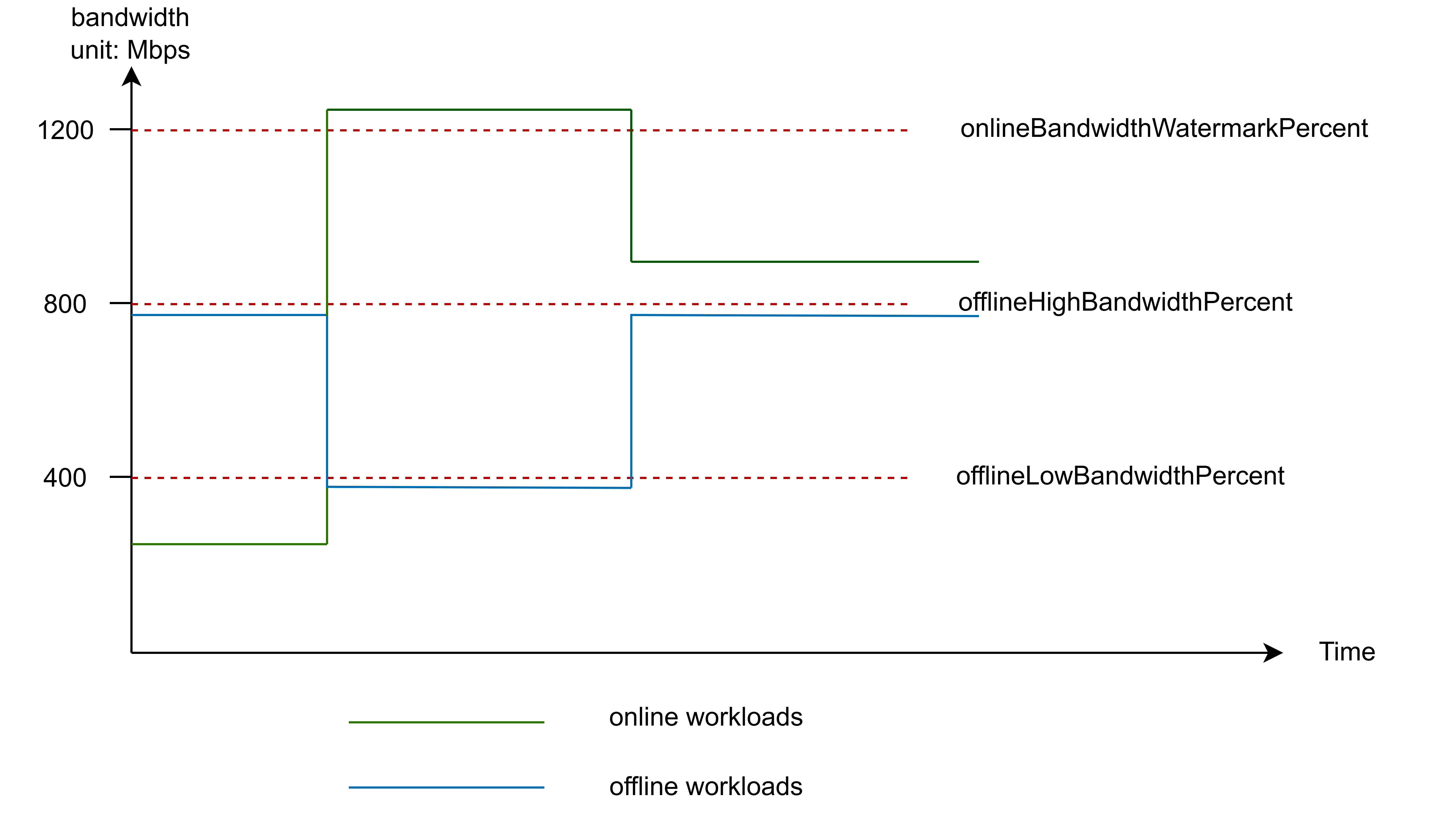
在出口网络带宽隔离机制中,离线作业的带宽使用会受到限制,尤其是在在线作业需要更多带宽时。为了实现更精细的带宽控制,通常会定义三个水位线参数(Watermark Parameters),用于动态调整离线作业的带宽分配。
| 水位线 | 说明 | 默认值 |
|---|---|---|
onlineBandwidthWatermarkPercent |
在线带宽水位线值与节点基础带宽的比值:onlineBandwidthWatermark 值 = 节点基础带宽 * onlineBandwidthWatermarkPercent / 100 |
80 |
offlineHighBandwidthPercent |
离线高带宽水位线值与节点基础带宽的比值:offlineHighBandwidth 值 = 节点基础带宽 * offlineHighBandwidthPercent / 100它表示当在线工作负载的带宽使用比例低于 onlineBandwidthWatermarkPercent 时,离线工作负载可使用的带宽上限。例如:节点基础带宽 = 100Mbps, onlineBandwidthWatermarkPercent = 80,offlineHighBandwidthPercent = 40,当在线工作负载使用的带宽小于 100Mbps * 0.8 = 80Mbps 时,离线工作负载最多可以使用 100Mbps * 0.4 = 40Mbps 的带宽。 |
40 |
offlineLowBandwidthPercent |
离线低带宽水位线值与节点基础带宽的比值:offlineLowBandwidth 值 = 节点基础带宽 * offlineLowBandwidthPercent / 100它表示当在线工作负载的带宽使用比例高于 onlineBandwidthWatermarkPercent 时,离线工作负载可使用的带宽上限。例如:节点带宽 = 100Mbps, onlineBandwidthWatermarkPercent = 80,offlineLowBandwidthPercent = 10,当在线工作负载使用的带宽大于 100Mbps * 0.8 = 80Mbps 时,离线工作负载最多可以使用 100Mbps * 0.1 = 10Mbps 的带宽。 |
10 |
设置节点网络带宽
本示例将演示在线作业如何抑制离线作业的整个网络带宽。我们将使用 iperf 工具来模拟在线作业和离线作业的网络入口带宽流量。
在所有节点上添加注解 volcano.sh/network-bandwidth-rate,以指定网络带宽速率。示例中设置的值为 1000Mbps,请根据实际环境设置合适的值,并替换 $node 为实际节点名称。
kubectl annotate node $node_name volcano.sh/network-bandwidth-rate=1000
部署在线和离线作业
部署一个在线作业和离线作业deployment,请将 $node_ip 替换为在你的环境中Pod可以访问到的节点 IP。同时,请在 $node_ip 节点上使用命令 iperf -s 启动 iperf 服务器,以确保 Pod 可以访问 iperf 服务器。
# 在线作业
apiVersion: apps/v1
kind: Deployment
metadata:
name: online-iperf
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: online-iperf
template:
metadata:
labels:
app: online-iperf
annotations:
volcano.sh/qos-level: "HLS" # 标识在线作业
spec:
containers:
- name: container-1
image: volcanosh/iperf
command:
- /bin/sh
- -c
- |
iperf -c $node_ip -i 1 -t 30 -f mb # 模拟消耗带宽
echo finished...
sleep 1000000
---
# 离线作业
apiVersion: apps/v1
kind: Deployment
metadata:
name: offline-iperf
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: offline-iperf
template:
metadata:
labels:
app: offline-iperf
annotations:
volcano.sh/qos-level: "BE" # 标识离线作业
spec:
containers:
- name: container-1
image: volcanosh/iperf
command:
- /bin/sh
- -c
- |
iperf -c $node_ip -i 1 -t 30 -f mb # 模拟消耗带宽
echo finished...
sleep 1000000
查看日志
查看在线和离线作业日志:
在线作业日志:
Connecting to host 192.168.2.30, port 5201
[ 5] local 192.168.2.115 port 58492 connected to 192.168.2.30 port 5201
[ ID] Interval Transfer Bandwidth
[ 5] 0.00-1.00 sec 118 MBytes 990 Mbits/sec
[ 5] 1.00-2.00 sec 106 MBytes 889 Mbits/sec
[ 5] 2.00-3.00 sec 107 MBytes 897 Mbits/sec
[ 5] 3.00-4.00 sec 107 MBytes 903 Mbits/sec
[ 5] 4.00-5.00 sec 107 MBytes 899 Mbits/sec
[ 5] 5.00-6.00 sec 107 MBytes 902 Mbits/sec
[ 5] 6.00-7.00 sec 705 MBytes 884 Mbits/sec
...
离线作业日志:
Connecting to host 192.168.2.30, port 5201
[ 5] local 192.168.2.115 port 44362 connected to 192.168.2.30 port 5201
[ ID] Interval Transfer Bandwidth
[ 5] 0.00-1.00 sec 8 MBytes 70 Mbits/sec
[ 5] 1.00-2.00 sec 12 MBytes 102 Mbits/sec
[ 5] 2.00-3.00 sec 11 MBytes 98 Mbits/sec
[ 5] 3.00-4.00 sec 11 MBytes 99 Mbits/sec
[ 5] 4.00-5.00 sec 11 MBytes 99 Mbits/sec
[ 5] 5.00-6.00 sec 11 MBytes 97 Mbits/sec
[ 5] 6.00-7.00 sec 11 MBytes 98 Mbits/sec
...
可以看到,当在线作业使用的带宽资源超过整个节点的 onlineBandwidthWatermarkPercent即默认值80时,离线作业只能使用大约 10% 的带宽,表明在线作业使用超过水位线的网络带宽时,离线作业的网络带宽使用被压制在较低值。
高级设置
功能开关
混部(Colocation)功能在节点上有一个统一的开关。如果节点具有标签 volcano.sh/oversubscription=true 或 volcano.sh/colocation=true,则表示混部功能已启用。你可以移除这两个标签以禁用所有混部功能。当节点具有这些标签时,所有混部功能才会生效。
- 如果你只想使用在线作业和离线作业的混部功能,而不启用资源超卖(Resource Oversubscription),只需设置节点标签
volcano.sh/colocation="true"。 - 如果你想同时使用混部功能和资源超卖功能,则应设置节点标签
volcano.sh/oversubscription=true。
默认情况下,volcano-system 命名空间中的 volcano-agent-configuration ConfigMap 保存了 Volcano Agent 的所有配置。
每个混部功能(CPU Burst / 动态资源超卖 / 出口网络带宽保障)都有一个独立的开关。你可以通过修改 volcano-system 命名空间中的 volcano-agent-configuration ConfigMap 来启用或禁用每个功能。
enable字段的值为true表示启用 CPU Burst 功能,false表示禁用该功能。"cpuBurstConfig":{ "enable": true }enable字段的值为true表示启用动态资源超卖功能,false表示禁用该功能。"overSubscriptionConfig":{ "enable": true, }enable字段的值为true表示启用出口网络带宽保障功能,false表示禁用该功能。"networkQosConfig":{ "enable": true, }
CPU Burst
启用了 CPU Burst 功能的 Pod 中的容器,其 CPU 使用量最多可以突增到容器的 CPU 限制值(cpu limit)。如果多个 Pod 同时使用突增的 CPU 资源,可能会发生 CPU 争用,从而影响 CPU 的 CFS(完全公平调度器)调度。
你可以通过设置 Pod 的注解 volcano.sh/quota-burst-time 来指定自定义的突增配额。例如:
如果一个容器的 CPU 限制为 4 核,Volcano Agent 默认会将容器的 CGroup cpu.cfs_quota_us 值设置为 400000(CFS 的基本周期为 100000,因此 4 核 CPU 对应 4 * 100000 = 400000)。这意味着容器在某一时刻最多可以额外使用 4 核 CPU。如果你设置 volcano.sh/quota-burst-time=200000,则表示容器在某一时刻最多只能额外使用 2 核 CPU。
动态资源超卖
默认情况下,超卖资源的计算和离线工作负载的驱逐仅考虑节点上 Pod 的资源使用情况。如果您希望考虑节点本身的资源利用率,应设置 volcano agent 的 --include-system-usage=true 标志。
为了避免对节点造成过大压力,volcano agent 设置了一个超卖比例来确定空闲资源的超卖比例。您可以通过设置 --oversubscription-ratio 标志来更改此参数,默认值为 60,表示 60% 的空闲资源将被超卖。如果您设置 --oversubscription-ratio=100,则表示所有空闲资源都将被超卖。
当节点有压力时,volcano agent 会驱逐离线工作负载。驱逐阈值可以通过 configMap volcano-agent-configuration 进行配置。"evictingCPUHighWatermark":80 表示当节点的 CPU 利用率在一段时间内超过 80% 时,将触发离线作业驱逐,并且在驱逐期间当前节点无法调度新的 Pod。"evictingCPULowWatermark":30 表示当节点的 CPU 利用率低于 30% 时,节点将恢复调度。evictingMemoryHighWatermark 和 evictingMemoryLowWatermark 的含义相同,但针对内存资源。
"evictingConfig":{
"evictingCPUHighWatermark": 80,
"evictingMemoryHighWatermark": 60,
"evictingCPULowWatermark": 30,
"evictingMemoryLowWatermark": 30
}
出口网络带宽保障
你可以通过修改 configMap volcano-agent-configuration 来调整在线和离线带宽的水位线(watermark)。qosCheckInterval 表示 volcano agent 监控带宽水位线的时间间隔,请谨慎修改此值。
"networkQosConfig":{
"enable": true,
"onlineBandwidthWatermarkPercent": 80,
"offlineHighBandwidthPercent":40,
"offlineLowBandwidthPercent": 10,
"qosCheckInterval": 10000000
}
自定义开发超卖策略
Volcano agent默认使用extend的方式上报和使用超卖资源,也就是将超卖资源作为一种扩展资源类型上报到节点,如果想自定义超卖资源的上报和使用,如上报为原生的cpu和memory资源,以及暂停和恢复调度的行为,请实现policy Interface实现自定义的超卖策略开发,并设置Volcano agent的启动参数oversubscription-policy为相应的策略。