Gang
Gang plugin
简介
Gang调度策略是volcano-scheduler的核心调度算法之一,它满足了调度过程中的“All or nothing”的调度需求,避免Pod的任意调度导致集群资源的浪费。具体算法是,观察Job下的Pod已调度数量是否满足了最小运行数量,当Job的最小运行数量得到满足时,为Job下的所有Pod执行调度动作,否则,不执行。
场景
基于容器组概念的Gang调度算法十分适合需要多进程协作的场景。AI场景往往包含复杂的流程,Data Ingestion、Data Analysts、Data Splitting、Trainer、Serving、Logging等,需要一组容器进行协同工作,就很适合基于容器组的Gang调度策略。MPI计算框架下的多线程并行计算通信场景,由于需要主从进程协同工作,也非常适合使用Gang调度策略。容器组下的容器高度相关也可能存在资源争抢,整体调度分配,能够有效解决死锁。
在集群资源不足的场景下,gang的调度策略对于集群资源的利用率的提升是非常明显的。
Binpack
简介
binpack调度算法的目标是尽量把已有的节点填满(尽量不往空白节点分配)。具体实现上,binpack调度算法是给可以投递的节点打分,分数越高表示节点的资源利用率越高。binpack算法能够尽可能填满节点,将应用负载靠拢在部分节点,这非常有利于K8S集群节点的自动扩缩容功能。
Binpack算法以插件的形式,注入到volcano-scheduler调度过程中,将会应用在Pod优选节点的阶段。Volcano-scheduler在计算binpack算法时,会考虑Pod请求的各种资源,并根据各种资源所配置的权重做平均。每种资源在节点分值计算过程中的权重并不一样,这取决于管理员为每种资源配置的权重值。同时不同的插件在计算节点分数时,也需要分配不同的权重,scheduler也为binpack插件设置了分数权重。
场景
binpack算法对能够尽可能填满节点的小作业有利。例如大数据场景下的单次查询作业、电商秒杀场景订单生成、AI场景的单次识别作业以及互联网高并发的服务场景等。这种调度算法能够尽可能减小节点内的碎片,在空闲的机器上为申请了更大资源请求的Pod预留足够的资源空间,使集群下空闲资源得到最大化的利用。
Priority
fair-share调度
简介
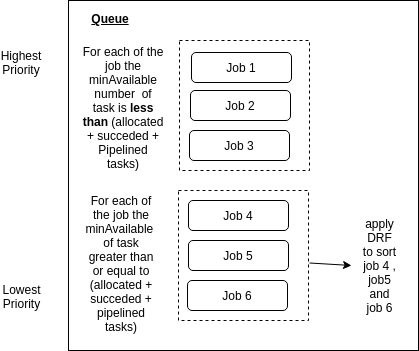
Priority plugin提供了job、task排序的实现,以及计算牺牲作业的函数preemptableFn。job的排序根据priorityClassName,task的排序依次根据priorityClassName、createTime、id。
场景
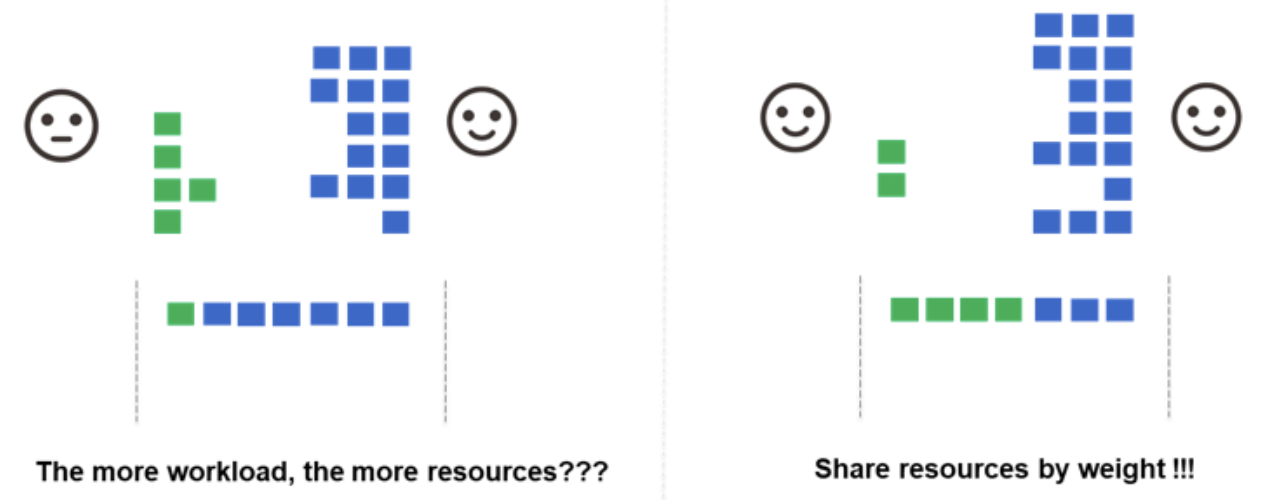
当集群运行了多个Job,但资源不足,并且每个Job下有不等数量的Pod等待被调度的时候,如果使用Kubernetes默认调度器,那么最终,具有更多Pod数量的Job将分得更多的集群资源。在这种情况下,volcano-scheduler提供算法支持不同的Job以fair-share的形式共享集群资源。
Priority plugin能够让用户自定义job、task优先级,根据自己的需求在不同层次来定制调度策略。根据job的priorityClassName在应用层面进行优先级排序,例如集群中有金融场景、物联网监控场景等需要较高实时性的应用,Priority plugin能够保证其优先得到调度。
DRF
drf plugin
简介
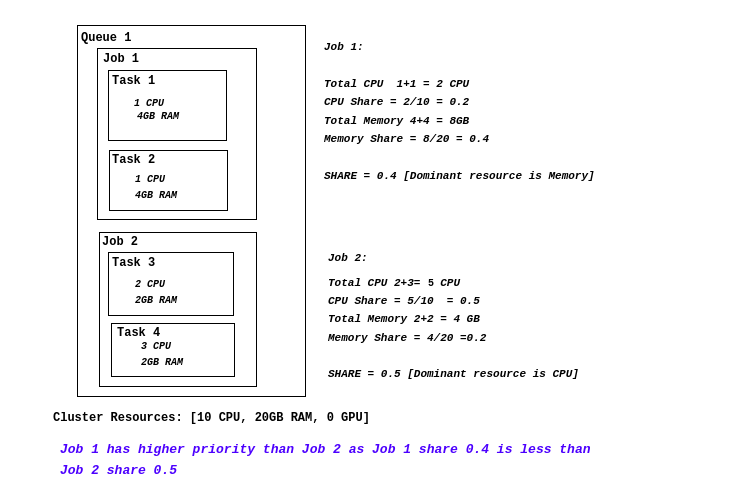
DRF调度算法的全称是Dominant Resource Fairness,是基于容器组Dominant Resource的调度算法。volcano-scheduler观察每个Job请求的主导资源,并将其作为对集群资源使用的一种度量,根据Job的主导资源,计算Job的share值,在调度的过程中,具有较低share值的Job将具有更高的调度优先级。这样能够满足更多的作业,不会因为一个胖业务,饿死大批小业务。DRF调度算法能够确保在多种类型资源共存的环境下,尽可能满足分配的公平原则。
场景
DRF调度算法优先考虑集群中业务的吞吐量,适用单次AI训练、单次大数据计算以及查询等批处理小业务场景。
Proportion
简介
Proportion调度算法是使用queue的概念,用来控制集群总资源的分配比例。每一个queue分配到的集群资源比例是一定的。举例来说,有3个团队,共享一个集群上的资源池:A团队最多使用总集群的40%,B团队最多使用30%,C团队最多使用30%。如果投递的作业量超过团队最大可用资源,就需要排队。
场景
Proportion调度算法为集群的调度带来了弹性、灵活性上面的提升。最典型的场景就是在一个公司的多个开发团队,共用一个集群的时候,这种调度算法能够很好的处理不同部门之间的共享资源配比和隔离的需求。在多业务混合场景,如计算密集型的AI业务,网络IO密集型的MPI、HPC业务,存储密集型的大数据业务,Proportion调度算法通过配比,能很好的按需分配共享资源。
Task-topology
简介
Task-topology算法是一种根据Job内task之间亲和性和反亲和性配置计算task优先级和Node优先级的算法。通过在Job内配置task之间的亲和性和反亲和性策略,并使用task-topology算法,可优先将具有亲和性配置的task调度到同一个节点上,将具有反亲和性配置的Pod调度到不同的节点上。
场景
node affinity:
- Task-topology对于提升深度学习计算场景下的计算效率非常重要。以TensorFlow计算为例,配置“ps”和“worker”之间的亲和性。Task-topology算法,可使“ps”和“worker”尽量调度到同一台节点上,从而提升“ps”和“worker”之间进行网络和数据交互的效率,进而提升计算效率。
- HPC、MPI场景下task之间具有高度同步性,需要高速的网络IO。
Anti-affinity:
- 以TensorFlow计算为例,“ps”与“ps”之间的反亲和性。
- 电商服务场景的主从备份,数据容灾,保证一个作业挂掉之后有备用作业继续提供服务。
Predicates
简介
Predicate plugin通过pod、nodeInfo作为参数,调用predicateGPU,根据计算结果对作业进行评估预选。
场景
在AI的应用场景下,GPU资源是必需,Predicate plugin可以快速筛选出来需要GPU的进行集中调度。
Nodeorder
简介
Nodeorder plugin是一种调度优选策略:通过模拟分配从各个维度为node打分,找到最适合当前作业的node。打分参数由用户来配置。参数包含了Affinity、reqResource,、LeastReqResource、MostReqResource、balanceReqResouce。
场景
Nodeorder plugin给调度提供了多个维度的打分标准,不同维度的组合,能够让用户根据自身需求灵活的配置合适的调度策略。
SLA
简介
SLA的全称是Service Level agreement。用户向volcano提交job的时候,可能会给job增加特殊的约束,例如最长等待时间(JobWaitingTime)。这些约束条件可以视为用户与volcano之间的服务协议。SLA plugin可以为单个作业/整个集群接收或者发送SLA参数。
场景
根据业务的需要用户可以在自己的集群定制SLA相关参数。例如实时性服务要求较高的集群,JobWaitingTime可以设置的尽量小。批量计算作业为主的集群,JobWaitingTime可以设置较大。具体SLA的参数以及参数的优化需要结合具体的业务以及相关的性能测评结果。
Tdm
简介
Tdm的全称是Time Division Multiplexing。在一些场景中,一些节点既属于Kubernetes集群也属于Yarn集群。Tdm plugin 需要管理员为这些节点标记为revocable node。Tdm plugin会在该类节点可被撤销的时间段内尝试把preemptable task调度给revocable node,并在该时间段之外清除revocable node上的preemptable task。Tdm plugin提高了volcano在调度过程中节点资源的分时复用能力。
场景
适用于ToB业务中,云厂商为商家提供云化资源,不同的商家采取不同的容器编排框架(Kubernetes/Yarn等),Tdm plugin提高公共节点资源的分时使用效率,进一步提升资源的利用率。
Numa-aware
简介
当节点运行多个cpu密集的pod。基于pod是否可以迁移cpu已经调度周期cpu资源状况,工作负载可以迁移到不同的cpu核心下。许多工作负载对cpu资源迁移并不敏感。然而,有一些cpu的缓存亲和度以及调度延迟显著影响性能的工作负载,kubelet允许可选的cpu编排策略(cpu management)来确定节点上cpu资源的绑定分配。
cpu manager以及topology manager都是kubelet的组件,它存在如下局限:
- 基于kubelet的调度组件不支持topology-aware。所以可能由于Topology manager,导致整个node上的调度失败。这对Tensorflow job是难以接受的,因为一旦有任何worker task挂掉,整个作业都将调度失败。
- 这些manager是节点级这导致无法在整个集群中匹配numa topology的最佳节点。
Numa-aware plugin致力于解决如上局限。
- 支持cpu资源的拓扑调度。
- 支持pod级别的拓扑协议。
场景
Numa-aware的常见场景是那些对cpu参数敏感\调度延迟敏感的计算密集型作业。如科学计算、视频解码、动漫动画渲染、大数据离线处理等具体场景。