背景
在AI大模型训练场景中,模型并行(Model Parallelism)将模型分割到多个节点上,训练过程中这些节点需要频繁进行大量数据交互。此时,节点间的网络传输性能往往成为训练的瓶颈,显著影响训练效率。数据中心的网络类型多样(如IB、RoCE、NVSwitch等),且网络拓扑复杂,通常包含多层交换机。两个节点间跨的交换机越少,通信延迟越低,吞吐量越高。因此,用户希望将工作负载调度到具有最高吞吐量和最低延迟的最佳性能域,尽可能减少跨交换机的通信,以加速数据交换,提升训练效率。
为此,Volcano提出了网络拓扑感知调度(Network Topology Aware Scheduling)策略,通过统一的网络拓扑API和智能调度策略,解决大规模数据中心AI训练任务的网络通信性能问题。
功能
统一的网络拓扑API:精准表达网络结构
为了屏蔽数据中心网络类型的差异,Volcano定义了新的CRD HyperNode来表示网络拓扑,提供了标准化的API接口。与传统的通过节点标签(label)表示网络拓扑的方式相比,HyperNode具有以下优势:
- 语义统一:HyperNode提供了标准化的网络拓扑描述方式,避免了标签方式的语义不一致问题。
- 层级结构:HyperNode支持树状层级结构,能够更精确地表达实际的网络拓扑。
- 易于管理:集群管理员可以手动创建HyperNode,或通过网络拓扑自动发现工具维护HyperNode。
一个HyperNode表示一个网络拓扑性能域,通常映射到一个交换机或者Tor。多个HyperNode通过层级连接,形成树状结构。例如,下图展示了由多个HyperNode构成的网络拓扑:
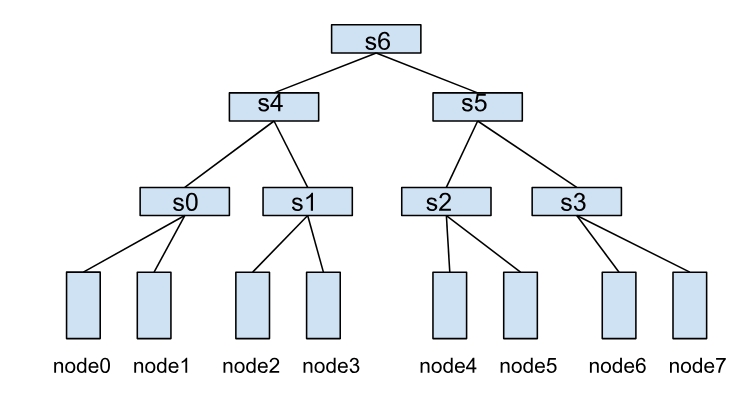
- 叶子HyperNode(s0、s1、s2、s3):子节点类型为集群中的真实节点。
- 非叶子HyperNode(s4、s5、s6):子节点类型为其他HyperNode。
在这种结构中,节点间的通信效率取决于它们之间的HyperNode层级跨度。例如:
- node0和node1同属于s0,通信效率最高。
- node1和node2需要跨两层HyperNode(s0→s4→s1),通信效率较低。
- node0和node4需要跨三层HyperNode(s0→s4→s6),通信效率最差。
关键字段
- spec.tier: 表示HyperNode的层级,层级越低,则该HyperNode内的节点通信效率越高。
- spec.members: HyperNode下面的一组子节点,可以通过selector来匹配关联的子节点。
- spec.members[i].type: 子节点的类型,支持
Node和HyperNode两种,子节点全部为Node时,代表当前HyperNode为叶子节点,子节点全部为HyperNode时,代表当前节点为非叶子HyperNode。 spec.members[i].selector: 子节点选择器,支持
exactMatch,regexMatch,和labelMatch三种selector。exactMatch表示精确匹配,子节点需要填写完整的HyperNode或者Node的name,regexMatch表示的是正则匹配,与正则表达式匹配的Node都会被当做当前HyperNode的子节点。labelMatch表示的是按标签匹配,带有对应标签的节点都会被当做当前HyperNode的子节点,配置示例如:labelMatch: matchLabels: topology-rack: rack-1
注意:regexMatch/labelMatch只能用在叶子HyperNode中,用来匹配集群中的真实节点,也就是说当spec.members[i].selector.type为HyperNode时,不支持regexMatch/labelMatch。
基于网络拓扑的感知调度策略
Volcano Job和PodGroup可以通过networkTopology字段设置作业的拓扑约束,支持以下配置:
- mode:支持
hard和soft两种模式。hard:硬约束,作业内的任务必须部署在同一个HyperNode内。soft:软约束,尽可能将作业部署在同一个HyperNode下。
- highestTierAllowed:与
hard模式配合使用,表示作业允许跨到哪层HyperNode部署,soft模式下无需配置该字段。
例如,以下配置表示作业只能部署在2层及以下的HyperNode内,如s4和s5,以及更低层的tier: s4和s5的子节点s0,s1,s2,s3,否则作业将处于Pending状态:
spec:
networkTopology:
mode: hard
highestTierAllowed: 2
通过这种调度策略,用户可以精确控制作业的网络拓扑约束,确保作业在满足条件的最佳性能域运行,从而显著提升训练效率。
HyperNode自动发现:简化网络拓扑管理
为进一步降低网络拓扑信息的管理负担,Volcano提供了HyperNode自动发现功能。该功能能够自动发现集群内的网络拓扑结构,并根据发现结果自动创建、更新或删除相应的HyperNode自定义资源(CRs)。
自动发现功能具有以下核心优势:
- 自动化管理:自动从多种数据源(如UFM、RoCE或节点标签)发现和维护HyperNode信息,无需手动维护。
- 实时同步:定期同步网络拓扑变化,确保HyperNode信息与实际网络状态保持一致。
- 可扩展架构:支持可插拔的Discoverer组件,用户可针对特定的网络管理工具开发自定义发现逻辑。
通过这一自动化发现机制,用户可以专注于作业调度配置,无需担心HyperNode创建和维护的复杂性,显著简化了网络拓扑感知调度的部署和管理。
使用指导
安装Volcano
Volcano支持以下两种安装方式:
通过Helm安装(推荐)
helm repo add volcano-sh https://volcano-sh.github.io/helm-charts
helm repo update
helm install volcano volcano-sh/volcano -n volcano-system --create-namespace --version 1.12.0
使用YAML文件安装
kubectl apply -f https://raw.githubusercontent.com/volcano-sh/volcano/refs/heads/network-topology/installer/volcano-development.yaml
配置Volcano调度器
要启用网络拓扑感知调度功能,需要修改Volcano调度器的配置文件。以下是一个配置示例,其中同时启用了 network-topology-aware 和 binpack 插件,开启binpack更有助于实现更紧凑的任务调度:
kind: ConfigMap
apiVersion: v1
metadata:
name: volcano-scheduler-configmap
namespace: volcano-system
data:
volcano-scheduler.conf: |
actions: "enqueue, allocate, backfill"
tiers:
- plugins:
- name: priority
- name: gang
- plugins:
- name: predicates
- name: proportion
- name: nodeorder
- name: binpack # 启用binpack插件,有助于任务的紧凑调度
# arguments: # 用来配置binpack插件中各项资源的权重以及binpack插件自身的权重
# binpack.weight: 10 # binpack插件的权重,影响binpack策略的整体得分
# binpack.cpu: 5 # CPU资源的权重,权重越高,CPU资源在打分时的占比越大
# binpack.memory: 1 # Memory资源的权重
# binpack.resources: nvidia.com/gpu # 指定额外资源类型,如GPU
# binpack.resources.nvidia.com/gpu: 2 # GPU的权重
- name: network-topology-aware # 开启network-topology-aware插件
# arguments:
# weight: 10 # 可以选择设置network-topology-aware的打分权重,默认weight为1
HyperNode CRs管理
HyperNode CRs可以通过自动发现或手动创建两种方式进行管理。
HyperNode自动发现(推荐)
Volcano通过集成可插拔的网络拓扑发现工具(Discoverer)实现HyperNode的自动发现与管理。Discoverer负责定期从外部网络拓扑管理系统(如UFM、RoCE、或基于节点标签等方式)收集网络拓扑信息,并将其转换为标准的HyperNode表示。 随后,Volcano内置的HyperNode Controller会根据Discoverer提供的信息,自动创建、更新或删除相应的HyperNode自定义资源(CRs)。这种机制使得Volcano调度器能够利用动态维护的HyperNode CRs进行精准的网络拓扑感知调度, 从而免除用户手动创建和维护HyperNode信息的负担,简化网络拓扑管理的复杂性。
Volcano提供了一些通用的Discoverer实现,以适应常见的网络环境。同时,Volcano也支持用户根据自身特定的网络拓扑发现工具和需求,开发自定义的Discoverer插件。
配置
HyperNode自动发现功能通过ConfigMap进行配置。ConfigMap中包含了发现源(如UFM、RoCE和label)的配置,你可以根据自己的集群环境修改配置。
Secret配置(UFM源必需)
如果你的集群底层网络采用InfiniBand (IB) 组网,并由UFM (Unified Fabric Manager) 管理,那么在配置UFM作为发现源时,需要首先创建一个Kubernetes Secret来存储UFM凭据:
kubectl create secret generic ufm-credentials \
--from-literal=username='your-ufm-username' \
--from-literal=password='your-ufm-password' \
-n volcano-system
注意:请将
your-ufm-username和your-ufm-password替换为你的实际UFM凭据,并根据需要调整命名空间。
ConfigMap示例
apiVersion: v1
kind: ConfigMap
metadata:
name: volcano-controller-configmap
namespace: volcano-system # 如果Volcano未安装在默认命名空间,请替换为实际的Volcano命名空间。
data:
volcano-controller.conf: |
networkTopologyDiscovery:
- source: ufm
enabled: true
interval: 10m
credentials:
secretRef:
name: ufm-credentials # 替换为存储UFM凭据的Secret名称。
namespace: volcano-system #替换为存储UFM凭据的Secret的命名空间。
config:
endpoint: https://ufm-server:8080
insecureSkipVerify: true
- source: roce
enabled: false
interval: 15m
config:
endpoint: https://roce-server:9090
- source: label
enabled: true
config:
networkTopologyTypes:
topologyA2:
- nodeLabel: "volcano.sh/tor" # 用于指示节点所属交换机(tor)的标签。如果不同节点上该标签对应的取值相同,则表示这些节点属于同一台交换机(tor)。
- nodeLabel: "kubernetes.io/hostname" # Kubernetes 集群中自动添加到每个节点的标准标签,用于标识节点的主机名。
topologyA3:
- nodeLabel: "volcano.sh/hypercluster" # 用于指示节点所属超集群(hypercluster)的标签。如果不同节点上该标签对应的取值相同,则表示这些节点属于同一个超集群(hypercluster)。
- nodeLabel: "volcano.sh/hypernode" # 用于指示节点所属超节点(hypernode)的标签。如果不同节点上该标签对应的取值相同,则表示这些节点属于同一个超节点(hypernode)。
- nodeLabel: "kubernetes.io/hostname" # Kubernetes 集群中自动添加到每个节点的标准标签,用于标识节点的主机名。
配置选项
source: 发现源,例如ufm。enabled: 是否启用该发现源。interval: 发现操作之间的时间间隔。如果未指定,则默认值为1小时。config: 发现源的配置。配置选项因发现源而异。credentials: 用于访问发现源的凭据配置。secretRef: 对包含凭据的Kubernetes Secret的引用。name: Secret的名称。namespace: Secret的命名空间。
UFM配置选项
endpoint: UFM API端点。insecureSkipVerify: 是否跳过TLS证书验证。这只应在开发环境中使用。
RoCE配置选项(当前不支持)
endpoint: RoCE API端点。token: RoCE API令牌。
Label配置选项
networkTopologyTypes: 支持不同类型网络拓扑的结构,包括适用于GPU、NPU等的拓扑。以下是NPU集群网络拓扑的示例。topologyA2: A2(昇腾 910B)集群的网络拓扑类型nodeLabel: 对于节点上的标签,当存在多个标签时,超节点会自下而上构建。最底层的标签是kubernetes.io/hostname,这是Kubernetes中的标准内置标签键,其上方的标签是volcano.sh/tor,用于指示节点所属的交换机。
topologyA3: A3(昇腾 910C)集群的网络拓扑类型nodeLabel: 对于节点上的标签,当存在多个标签时,超节点会自下而上构建。最底层的标签是kubernetes.io/hostname,这是Kubernetes中的标准内置标签键,其上方的标签为volcano.sh/hypernode和volcano.sh/hypercluster,volcano.sh/hypernode用于指示节点所属的超节点,volcano.sh/hypercluster用于指示节点所属的超集群。
验证
检查Volcano控制器日志,确保发现源已成功启动。
kubectl logs -n volcano-system -l app=volcano-controllers -c volcano-controllers | grep "Successfully started all network topology discoverers"检查已创建的HyperNode资源。
kubectl get hypernodes -l volcano.sh/network-topology-source=<source>
将 <source> 替换为你配置的发现源,例如 ufm。
故障排除
- 如果发现源未成功启动,请检查Volcano控制器日志以获取错误信息。
- 如果未创建HyperNode资源,请检查发现源配置,并确保发现源能够连接到网络拓扑数据源。
如果用户要实现自己的HyperNode discoverer,请参考:HyperNode Discoverer 开发指南
手动创建HyperNode
如果你的环境中没有可用的网络拓扑自动发现工具,或者你希望更精细地控制HyperNode的定义,可以选择手动创建HyperNode CRs。
仍以图1中的网络拓扑为例,分别创建叶子节点和非叶子节点HyperNode。本样例仅为使用演示,实际需要创建的HyperNode请以集群中的真实拓扑为准。
先创建叶子节点HyperNode s0,s1,s2和s3。
apiVersion: topology.volcano.sh/v1alpha1
kind: HyperNode
metadata:
name: s0
spec:
tier: 1 # s0位于tier1
members:
- type: Node
selector:
exactMatch:
name: "node-0"
- type: Node
selector:
exactMatch:
name: "node-1"
---
apiVersion: topology.volcano.sh/v1alpha1
kind: HyperNode
metadata:
name: s1 # s1位于tier1
spec:
tier: 1
members:
- type: Node
selector:
exactMatch:
name: "node-2"
- type: Node
selector:
exactMatch:
name: "node-3"
---
apiVersion: topology.volcano.sh/v1alpha1
kind: HyperNode
metadata:
name: s2 # s2位于tier1
spec:
tier: 1
members:
- type: Node
selector:
exactMatch:
name: "node-4"
- type: Node
selector:
exactMatch:
name: "node-5"
---
apiVersion: topology.volcano.sh/v1alpha1
kind: HyperNode
metadata:
name: s3
spec:
tier: 1 # s3位于tier1
members:
- type: Node
selector:
exactMatch:
name: "node-6"
- type: Node
selector:
exactMatch:
name: "node-7"
然后创建非叶子节点s4,s5和s6。
apiVersion: topology.volcano.sh/v1alpha1
kind: HyperNode
metadata:
name: s4 # s4位于tier2
spec:
tier: 2
members:
- type: HyperNode
selector:
exactMatch:
name: "s0"
- type: HyperNode
selector:
exactMatch:
name: "s1"
---
apiVersion: topology.volcano.sh/v1alpha1
kind: HyperNode
metadata:
name: s5
spec:
tier: 2 # s5位于tier2
members:
- type: HyperNode
selector:
exactMatch:
name: "s2"
- type: HyperNode
selector:
exactMatch:
name: "s3"
---
apiVersion: topology.volcano.sh/v1alpha1
kind: HyperNode
metadata:
name: s6
spec:
tier: 3 # s6位于tier3
members:
- type: HyperNode
selector:
exactMatch:
name: "s4"
- type: HyperNode
selector:
exactMatch:
name: "s5"
部署带有拓扑约束的Job
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: mindspore-cpu
spec:
minAvailable: 3
schedulerName: volcano
networkTopology: # 设置network topology约束
mode: hard
highestTierAllowed: 2
queue: default
tasks:
- replicas: 3
name: "pod"
template:
spec:
containers:
- command: ["/bin/bash", "-c", "python /tmp/lenet.py"]
image: lyd911/mindspore-cpu-example:0.2.0
imagePullPolicy: IfNotPresent
name: mindspore-cpu-job
resources:
limits:
cpu: "1"
requests:
cpu: "1"
restartPolicy: OnFailure
由于Job的spec.networkTopology.highestTierAllowed为2,因此期望结果为: 不能部署在3层HyperNode s6内,也就是只能部署到node0-node3,或者node4-node7内,而不能部署在node0-node7内。
注意事项
- 非叶子节点HyperNode的member selector不支持regexMatch/labelMatch。
- regexMatch/exactMatch/labelMatch selector不能同时配置,只能配置一种selector。
- HyperNode的member是Node类型,即HypeNode为叶子节点时,不允许再设置类型为HyperNode的member。
- 叶子节点HyperNode包含了集群中的真实节点,因此使用该特性时必须要创建出叶子HyperNode节点。
- HyperNode之间不能有环依赖,否则Job无法正常调度。
- 一个HyperNode可以有多个子节点,但一个HyperNode最多只能有一个parent HyperNode,否则Job无法正常调度。
最佳实践
Hard模式、Soft模式选择及调度简述
hard模式:- 作业中的所有任务必须被调度到
spec.networkTopology.highestTierAllowed定义的单个HyperNode层级(或更低层级)内。如果找不到满足此约束的HyperNode,作业将保持Pending状态。此模式适用于对网络拓扑有严格要求的场景。
- 作业中的所有任务必须被调度到
soft模式:- 调度器会尽最大努力将作业中的所有任务调度到同一个HyperNode内,以优化网络性能。但如果无法在单个HyperNode内满足所有任务的资源需求,也允许任务被调度到不同的HyperNode上,以确保作业能够尽快运行。此模式适用于希望优化网络性能,但又能接受一定调度灵活性的场景。
- 调度插件与基本打分逻辑:
- 网络拓扑感知调度依赖于
network-topology-aware插件。该插件打分时:- HyperNode的层级越低,得分越高。
- 如果多个HyperNode层级相同,则作业在该HyperNode内已成功调度的Pod数量越多,该HyperNode得分越高。
- 网络拓扑感知调度依赖于
HyperNode自动发现相关实践
- Volcano使用 Kubernetes 标准的 Secret 来存储敏感的凭证信息(用户名/密码或令牌)。对于更严格的密钥加密要求,用户应考虑额外的机制,如静态加密Secret数据。
- 凭证 Secret 可以放置在指定的命名空间中,以实现更好的隔离。
- 对于UFM发现器,控制器仅需要对包含凭证的特定 Secret 的读取权限。
- 在生产环境中部署时,应配置适当的RBAC策略以限制对 Secret 的访问。
- 应在生产环境中启用TLS证书验证以防止中间人攻击。
- 监控Volcano控制器日志以获取错误信息。
- 设置合理的发现间隔以避免网络拓扑数据源过载。