iQIYI: Volcano-based Cloud Native Migration Practices
This article was firstly released at
Container Cubeon September 30th, 2020, refer to揭秘爱奇艺深度学习平台云原生迁移实践
Introduction to iQIYI Jarvis Deep Learning Platform
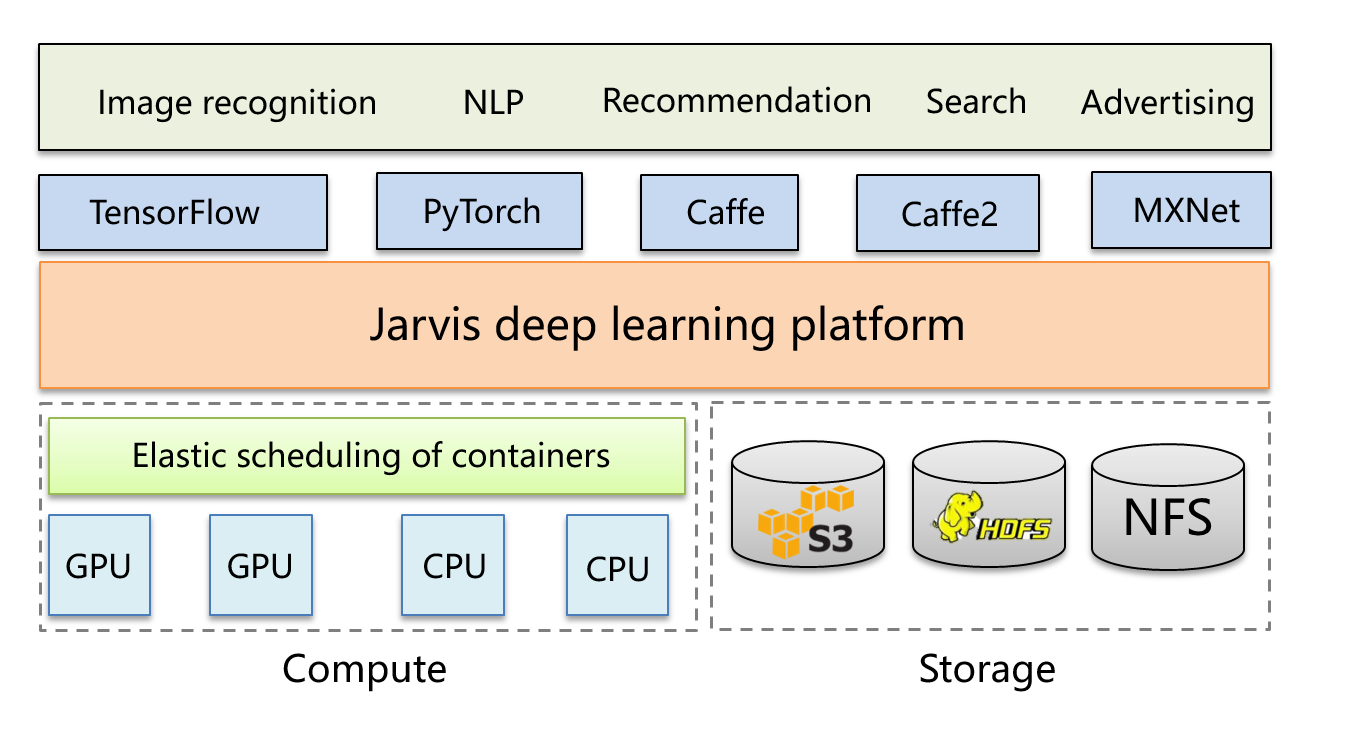
Overall Architecture of the Platform
The platform supports GPU- and CPU-based training and inference. S3, HDFS, and NFS can be used for storing training data and models. The platform supports TensorFlow, PyTorch, Caffe, Caffe2 and MXNet. It uses TensorFlow and PyTorch. TensorFlow 1.X to 2.X are supported.
The platform can be used in advertising, search, recommendation, NLP, and other services. iQIYI uses Mesos + Marathon as their elastic container platform. When iQIYI started the platform, Kubernetes was not mature enough to be considered. Therefore, our containers do not run on K8s.
One-stop Platform Service
Four small platforms are used to provide the service. The first is the data preprocessing platform. It analyzes the training data in a visualized manner, helps users adjust parameters, and detects abnormal data in a timely manner.
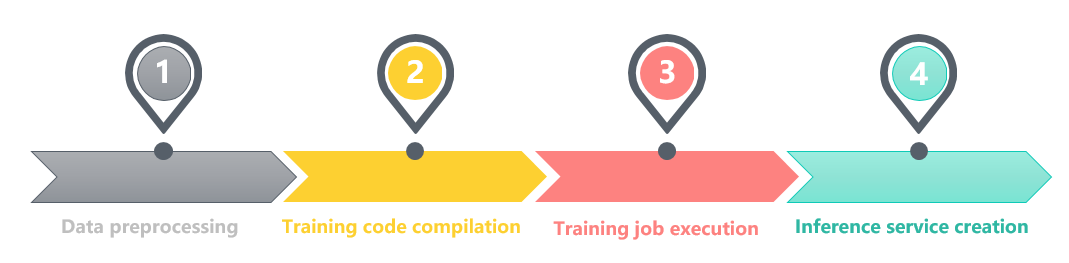
The second is the training code compilation platform. You can use the RunOnce or notebook training to obtain an environment that is the same as the training environment. You then can compile the training code, and commit the code to GitLab.
The third is the training job execution platform. You can run a training job by using the Jarvis training platform, and then the training code will be executed. An algorithm model will be output.
The last is the Jarvis inference platform. You can create an inference service using the platform and provide the inference service for external systems.
Platform Development
iQIYI started from the inference platform. iQIYI first enables the models to provide services for external systems, and then gradually extends the platform functions to support training, development, and data preprocessing. Currently, iQIYI is migrating the elastic container platform from Mesos + Marathon to K8s + Volcano.
Training Platform Architecture Before Volcano Is Used
The following figure shows the training platform architecture before Volcano is used.
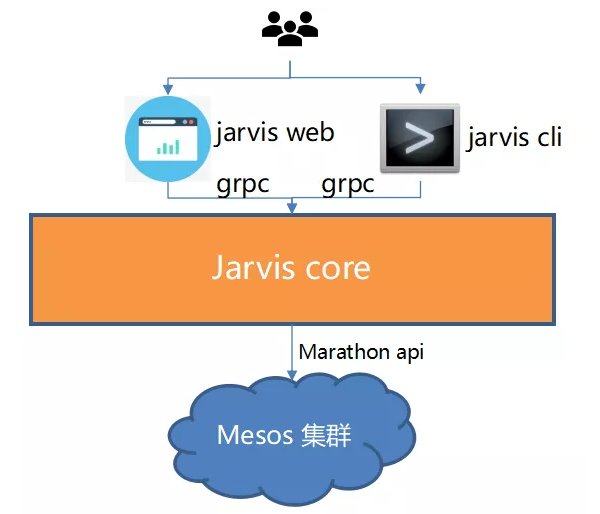
The process is as follows:
A.Compile training code and commit it to GitLab.
B.You can create a training job on the web page or using the command line tool. To create a training job, you need to enter the following information:
-
Required resources
-
Images. Each version of each framework is supported by an image. Selecting an image means selecting an algorithm framework.
-
There may be multiple clusters. You need to specify the cluster where the job is expected to run.
-
The URL of the GitLab project. The project contains the training code you compiled.
C.The Jarvis cli/web converts the request into gRPC and sends it to the Jarvis core.
D.The core converts the request and calls the Marathon API to create a container.
E.The container is started in the specified cluster and executes the training job.
Challenges of Migrating the Training Platform to Kubernetes
The challenges are as follows:
-
Native pods, Deployments, and jobs cannot meet the requirements of distributed training.
-
Queue and quota management are not supported.
-
Lack of scheduling capabilities, such as Gang Scheduling.
Introducing Volcano
The three most important concepts of Volcano are VolcanoJob, queue, and PodGroup. VolcanoJob, referred to as vcjob, is an extension of Kubernetes jobs or an encapsulation of pods.
Queues can be used to manage quotas.
PodGroup is a group of pods and can be used for advanced upper-layer scheduling.
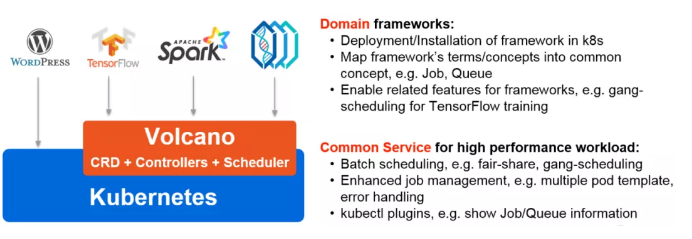
So far:
-
Volcano is the native batch system of Kubernetes and is highly suitable for AI training.
-
It does not intrude Kubernetes source code and complies with the Kubernetes development specifications, facilitating secondary development.
-
It has been accepted by Cloud Native Computing Foundation (CNCF) and is mature.
Power of Volcano
How Does Volcano Solve Problems of Migrating to Kubernetes?
Gang Scheduling
1.1 Gang Scheduling
Gang scheduled pods run simultaneously or none of them run. This is important for AI training, especially distributed training in most scenarios. The feature of distributed training is that a large number of pods, for example, 40 or 50 pods, are started at a time. If some pods of a task are scheduled and some pods are not scheduled, the task cannot run properly. This will also cause resource waste, or even deadlocks.
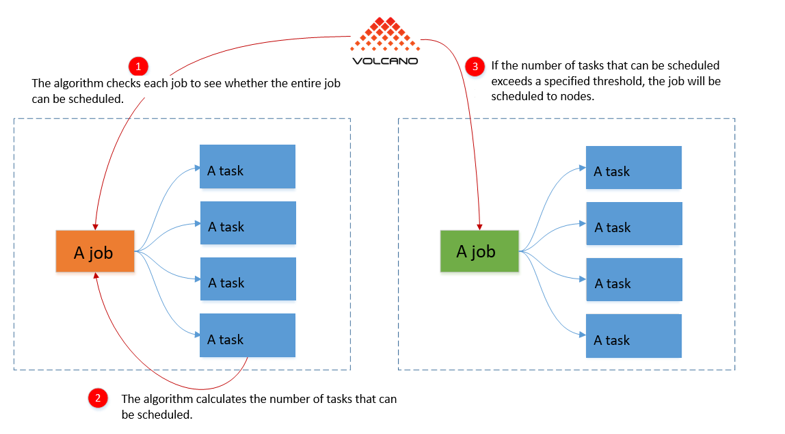
For example, there are only four GPUs in a resource pool and tasks A and B. Each task has four pods, and each pod requires one GPU. When tasks A and B are created at the same time, without gang scheduling, each task may obtain only two GPUs. In this case, neither of the tasks can be completed, resulting in a deadlock. Unless resources are added to the pool, the deadlock cannot be resolved.
Volcano schedules jobs in the unit of PodGroup to implement gang scheduling, avoiding the preceding problem.
1.2 Native Support for Distributed Tasks
Take TensorFlow distributed training as an example. It has the following roles: Parameter Server (PS), master, and worker. PS is used to store parameters. Master and worker are used to calculate gradients. In each iteration, master and worker obtain parameters from PS and update the calculated gradients to PS. PS aggregates the gradients returned from master and worker, updates the parameters, and broadcasts the updated parameters to master and worker.
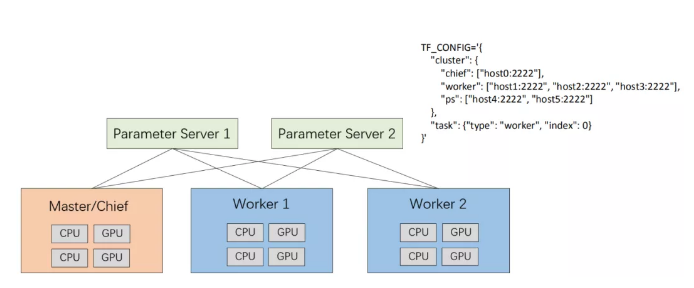
Let's focus on one of its network structures. If master or worker needs to communicate with PS, problems will occur. When creating a pod, a user may not know the IP address of the pod. Multiple pods created in a deployment may not know the IP address or domain name of each other. Without Volcano, solutions to these problems are complicated.
Each role must know the IP address or domain name of the other roles, the role it plays, and the number of indexes. A TF_CONFIG configuration file is required to include the IP addresses or domain names of master, worker, and PS. These are difficult to implement in Kubernetes. However, with Volcano, the solutions become simple.
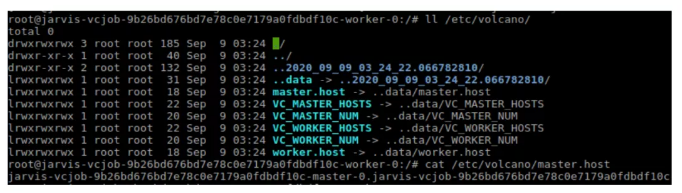
Volcano can easily build TF_CONFIG through file injection to support TensorFlow distributed training. Volcano injects a folder (etc/volcano) to multiple pods under a vcjob. The folder includes all domain names of master, volcano, and PS. In this way, each pod knows the peers in the entire cluster, and the TensorFlow distributed training can be performed.
Currently, TensorFlow provides some high-level APIs, such as TF estimator. The single-node code and distributed code in the estimator are the same, but the configuration of TF_CONFIG is different. If the environment variables or configuration files in such a format are passed, distributed training can be performed. If platforms can build the TF_CONFIG file, users can directly run the file.
1.3 Horovod/MPI
Volcano supports Horovod, which is similar to TensorFlow. They are both used for distributed training but differ in the way of updating parameters.
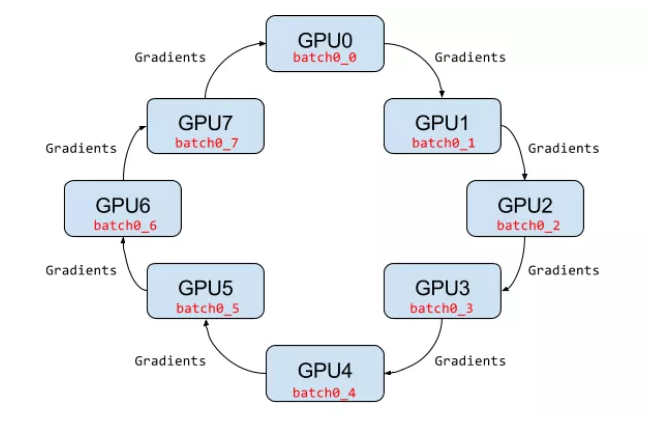
Horovod uses the ring allreduce method to update parameters, and what does that mean for us when we want to build a basic environment for upper-layer applications to use? What does the ring allreduce architecture require?
First, we need to ensure that each node knows the domain name of each other, as mentioned earlier. Second, we need to enable a node to SSH log in to another through port 22 without a password. This passwordless SSH can be automatically implemented with Volcano's SSH plugin, saving a lot of trouble.
1.4 Quotas and Queues
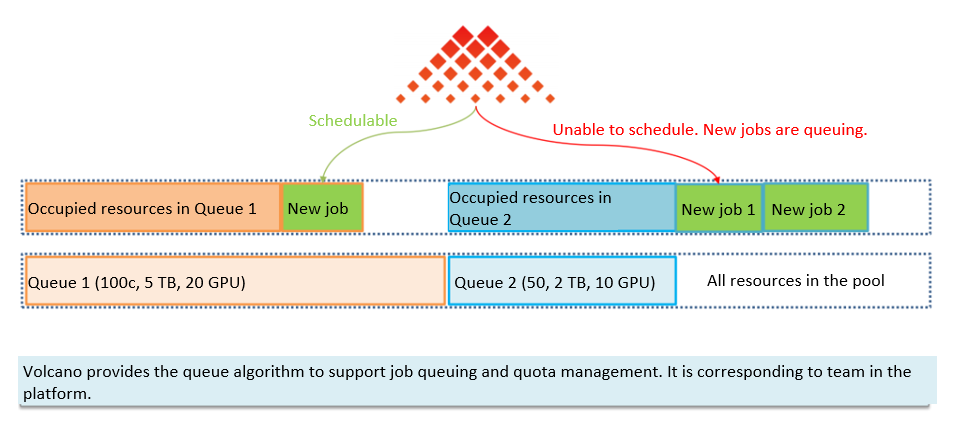
Volcano uses queues (CRD objects) to schedule jobs. Let's assume that we have two queues, as shown in the following figure. Queue1 has a quota of 20 GPUs and queue2 has a quota of 10 GPUs. The resources of queue1 are abundant so new jobs in queue 1 can be scheduled. However, all resources in queue2 have been used, and new jobs in queue2 cannot be scheduled and have to wait in queue. As a result, the PodGroups changes to the pending state.
The teams in our platform are similar to the Volcano queues. How? Each team has a quota, and quotas are independent between teams. When the resource usage reaches the quota of a team, the jobs in the team have to wait in queue. When resources are available, the queued jobs will be executed based on the priority, which means the jobs with a higher priority will be run first. Considering this similarity, the interconnection between Volcano and iQIYI’s platform can be fairly easy.
1.5 Integration with Volcano
iQIYI has added the volcano_plugin, which encapsulates the RESTful APIs of vcjob, queue, and PodGroup. It converts the gRPC requests into YAML configurations that comply with the Kubernetes API specifications, and calls the Kubernetes API to create containers.
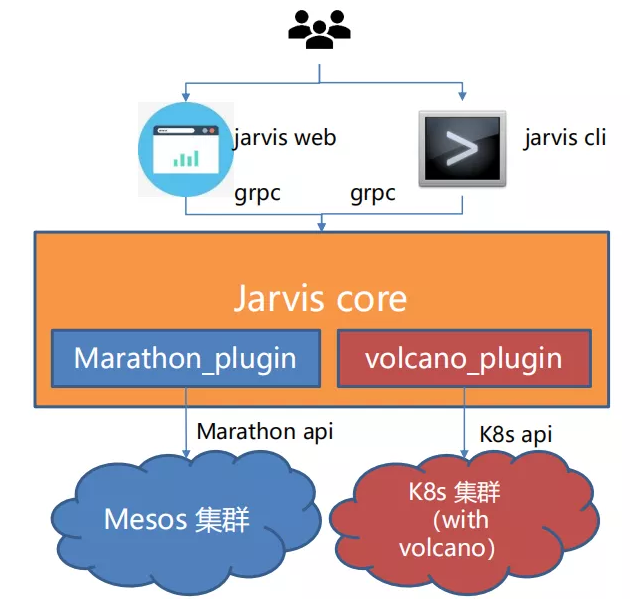
Jarvis Core determines which backend to use based on the passed cluster information.
Encountered Issues
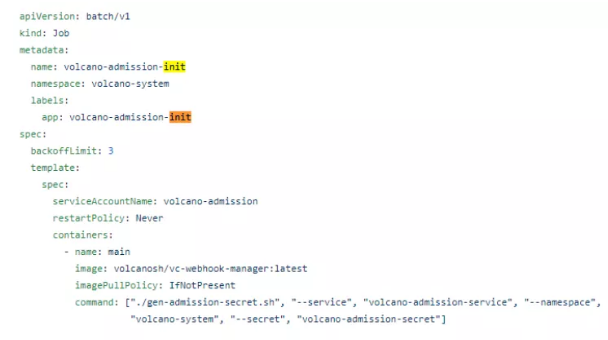
Issue 1
Symptom:During Volcano upgrade, the image in https://github.com/volcano_x0002_sh/volcano/blob/master/installer/volcano-development.yaml was directly modified, and kubectl apply -f <yaml file> was executed. The existing queues and vcjobs all disappeared.
Cause:volcano-admission-init in the YAML file was executed repeatedly. As a result, Volcano was reset.
Solution: Upgrade only the necessary components.
Issue 2
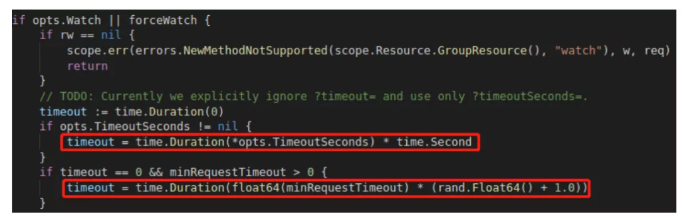
Symptom: When list_and_watch was used to monitor vcjob status, the watch connection broke every 80 to 90 seconds when there were no new events, and the disconnection duration varied. Such issue did not occur when the same code was used to monitor pods.
Cause: The default http timeout for CRD objects in Kubernetes is time.Duration(float64(minRequestTimeout) * (rand.Float64() + 1.0)), where miniRequestTimeout is set to 1 minute. You can specify timeoutSecond on the client to avoid this issue.
Issue 3
Symptom: The container entry address in Jarvis is a bash script. When the script was run in Kubernetes, a container did not exit until 30 seconds after the stop command was delivered.
Cause:Bash did not pass the signal to child processes. When graceful stop timeout was reached, the daemon process detected that the container had not exited and sent a SIGKILL signal to kill the bash script and exit the container. However, other processes in the container had no chance to clean up.
Solution:Use dum-init to run a script such as the following entry script:
#!/usr/bin/dumb-init /bin/bash
my-web-server & # launch a process in the background
my-other-server # launch another process in the foreground
1.6Modifications on Volcano
-
The SVC plugin now supports the input parameter nodeport. It means when we create a vcjob and pass the SVC parameter, a nodeport will be created, so our TensorBoard and other services can be accessed externally.
-
We have fixed the bug that creation fails when the name of the SSH plugin exceeds 63 bytes.
-
Volcano has fixed the bug in the queue capability that resources can be used over the capability. For details, see https://github.com/volcano-sh/volcano/issues/921.
-
After a vcjob is annotated, if a pod fails, the vcjob deletion is not triggered. For details, see https://github.com/volcano_x0002_sh/volcano/issues/805.
Summary
Volcano makes up for the lack of basic deep learning capabilities in Kubernetes.
-
Gang Scheduler
-
Queue management
Volcano code complies with the Kubernetes standards and is non-intrusive.
-
Lower development and interconnection costs
-
Easy for secondary development
Volcano-based Jarvis has been released and is running properly.