Volcano v1.11 released: A New Era of Cloud-Native Scheduling for AI and Big Data
As the de facto standard in cloud-native batch computing, Volcano has been widely adopted across various scenarios, including AI, Big Data, and High-Performance Computing (HPC). With over 800 contributors from more than 30 countries and tens of thousands of code commits, Volcano has been deployed in production environments by over 60 enterprises worldwide. It provides the industry with excellent practical standards and solutions for cloud native batch computing.
As user scenarios grow increasingly complex, especially in the scenarios of LLMs, there is a heightened demand for performance, GPU resource utilization, and availability in both training and inference workloads. This has driven Volcano to continuously expand its capabilities and address core user needs. Over the course of 28 releases, Volcano has introduced a series of enhancements and optimizations tailored to batch computing scenarios, helping users seamlessly migrate their workloads to cloud-native platforms. These improvements have resolved numerous pain points, earning the platform widespread praise and fostering a vibrant community with over 30 approvers and reviewers, creating a win-win ecosystem.
The new release of Volcano will mark a new milestone in the New Year 2025, where the community will introduce a series of major features that will continue to deepen its focus on areas such as CNAI (Cloud Native AI) and Big Data, with key features including:
AI Scenarios:
- Network Topology-Aware Scheduling: Reduces network communication overhead between training tasks, optimizing performance for large AI model training.
- NPU Scheduling and Virtualization: Enhances NPU resource utilization.
- GPU Dynamic Partitioning: Introduces MIG and MPS dynamic partitioning to improve GPU resource utilization.
- Volcano Global Multi-Cluster AI Job Scheduling: Supports Multi-cluster AI job deployment and distribution.
- Checkpointing and Fault Recovery Optimization: Enables finer-grained job restart policies.
- Dynamic Resource Allocation (DRA): Supports flexible and efficient management of heterogeneous resources.
Big Data Scenarios:
- Elastic Hierarchical Queues: Facilitates smooth migration of Big Data workloads to cloud-native platforms.
Microservices Scenarios:
- Online and Offline Workloads colocation with Dynamic Resource Oversubscription: Boosts resource utilization while ensuring QoS for online workloads.
- Load-Aware Scheduling and Descheduling: Provides resource defragmentation and load balancing capabilities.
The official release of Volcano v1.11 marks a new chapter in cloud-native batch computing! This update focuses on the core needs of AI and Big Data, introducing network topology-aware scheduling and multi-cluster AI job scheduling, significantly enhancing the performance of AI training and inference tasks. Additionally, online and offline workloads colocation with dynamic resource oversubscription and load-aware descheduling further optimize resource utilization, ensuring high availability for online services. The introduction of elastic hierarchical queues offers more flexible scheduling strategies for Big Data scenarios.
Deep Dive into Key Features
The v1.11 version released this time provides a series of major feature updates for AI, Big data and resource utilization improvement scenarios, mainly including:
Network Topology-Aware Scheduling: Optimizing AI Large Model Training Performance
In AI large model training, model parallelism splits the model across multiple nodes, requiring frequent data exchange between nodes. Network communication often becomes a bottleneck, significantly impacting training efficiency. Data centers feature diverse network types like InfiniBand (IB), RoCE, and NVSwitch, with complex multi-layer switch topologies. The fewer switches spanned between two nodes, the lower the communication latency and the higher the throughput. Thus, users aim to schedule workloads in the optimal performance domain with the highest throughput and lowest latency.
To address this, Volcano introduces Network Topology-Aware Scheduling, leveraging a unified network topology API and intelligent scheduling strategies to tackle network communication performance issues in large-scale AI training jobs.
Unified Network Topology API: Precise Network Structure Representation
To abstract away the differences in data center network types, Volcano defines a new CRD HyperNode, to represent network topology, providing a standardized API. Compared to traditional label-based approaches, HyperNode offers several advantages:
- Semantic Consistency: HyperNode provides a standardized way to describe network topology, avoiding inconsistencies in label semantics.
- Hierarchical Structure: HyperNode supports tree-like hierarchies, accurately reflecting actual network topologies.
- Ease of Management: Cluster administrators can manually create HyperNodes or use automated network topology discovery tools to maintain them.
A HyperNode represents a network topology performance domain, typically mapped to a switch. Multiple HyperNodes connect hierarchically to form a tree structure. For example:
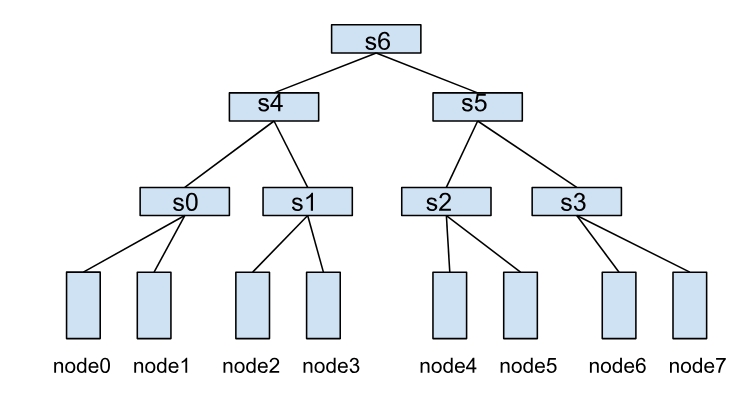
- Leaf HyperNodes (s0, s1, s2, s3): Represent actual cluster nodes.
- Non-Leaf HyperNodes (s4, s5, s6): Represent other HyperNodes.
In this structure, communication efficiency between nodes depends on the number of HyperNode layers they span. For instance:
- node0 and node1 within s0 have the highest communication efficiency.
- node1 and node2 spanning two HyperNode layers (s0→s4→s1) have lower efficiency.
- node0 and node4 spanning three HyperNode layers (s0→s4→s6) have the lowest efficiency.
HyperNode Configuration Example
Here’s an example of leaf and non-leaf HyperNode configurations:
Leaf HyperNode Example:
apiVersion: topology.volcano.sh/v1alpha1
kind: HyperNode
metadata:
name: s0
spec:
tier: 1 # Lower tiers indicate higher communication efficiency
members: # List of child nodes
- type: Node # Child node type
selector:
exactMatch: # Exact match
name: node-0
- type: Node
selector:
regexMatch: # Regex match
pattern: node-[01]
Non-Leaf HyperNode Example:
apiVersion: topology.volcano.sh/v1alpha1
kind: HyperNode
metadata:
name: s6
spec:
tier: 3 # HyperNode tier
members: # List of child nodes
- type: HyperNode # Child node type
selector:
exactMatch: # Exact match
name: s4
- type: HyperNode
selector:
exactMatch: # Exact match
name: s5
Network Topology-Aware Scheduling Strategy
Volcano Job and PodGroup can set topology constraints via the networkTopology field, supporting the following configurations:
- mode: Supports
hardandsoftmodes.hard: Enforces strict constraints, requiring tasks within a job to be deployed within the same HyperNode.soft: Prefers deploying tasks within the same HyperNode but allows flexibility.
- highestTierAllowed: Used with
hardmode to specify the maximum HyperNode tier a job can span.
For example, the following configuration restricts a job to HyperNodes of tier 2 or lower (e.g., s4 or s5), otherwise, the job remains in a Pending state:
spec:
networkTopology:
mode: hard
highestTierAllowed: 2
This scheduling strategy allows users to precisely control job topology constraints, ensuring optimal performance and significantly improving training efficiency.
Future Plans
Volcano will continue to refine network topology-aware scheduling, with future plans including:
- Automating the conversion of node labels to HyperNode CRs to simplify migration.
- Integrating network topology discovery tools to streamline HyperNode management.
- Providing CLI tools for easier HyperNode hierarchy visualization and management.
For detailed design and user guide, please refer to:
Design Document: Network Topology Aware Scheduling.
Usage Document: Network Topology Aware Scheduling | Volcano.
Sincerely thanks to community developers: @ecosysbin, @weapons97, @Xu-Wentao, @penggu, @JesseStutler, @Monokaix for their contributions!
Elastic Hierarchical Queues: Flexible Multi-Tenant Resource Management
In multi-tenant environments, fair resource allocation, isolation, and job prioritization are critical. Different departments or teams often share cluster resources while ensuring their jobs receive resources on demand, avoiding contention or waste. Volcano v1.11 introduces Elastic Hierarchical Queues, significantly enhancing queue resource management. Hierarchical queues enable finer-grained resource quota management, cross-level resource sharing and reclamation, and flexible preemption policies, creating an efficient and fair unified scheduling platform. For users migrating from YARN, Volcano seamlessly transitions Big Data workloads to Kubernetes clusters.
Core Capabilities of Elastic Hierarchical Queues
Volcano’s elastic hierarchical queues offer the following key features to meet complex multi-tenant demands:
- Configurable Queue Hierarchies: Users can create multi-level queues in a tree structure, each with independent resource quotas and priorities.
- Cross-Level Resource Sharing and Reclamation: Idle resources in child queues can be shared with sibling queues and reclaimed when needed.
- Fine-Grained Resource Quota Management: Each queue can set parameters like:
capability: Maximum resource capacity.deserved: Fair share of resources; excess can be reclaimed.guarantee: Reserved resources, ensuring minimum guarantees.
- Flexible Preemption Policies: Supports priority-based preemption to ensure high-priority tasks receive resources promptly.
Hierarchical Queue Example
A simple hierarchical queue structure might look like this:
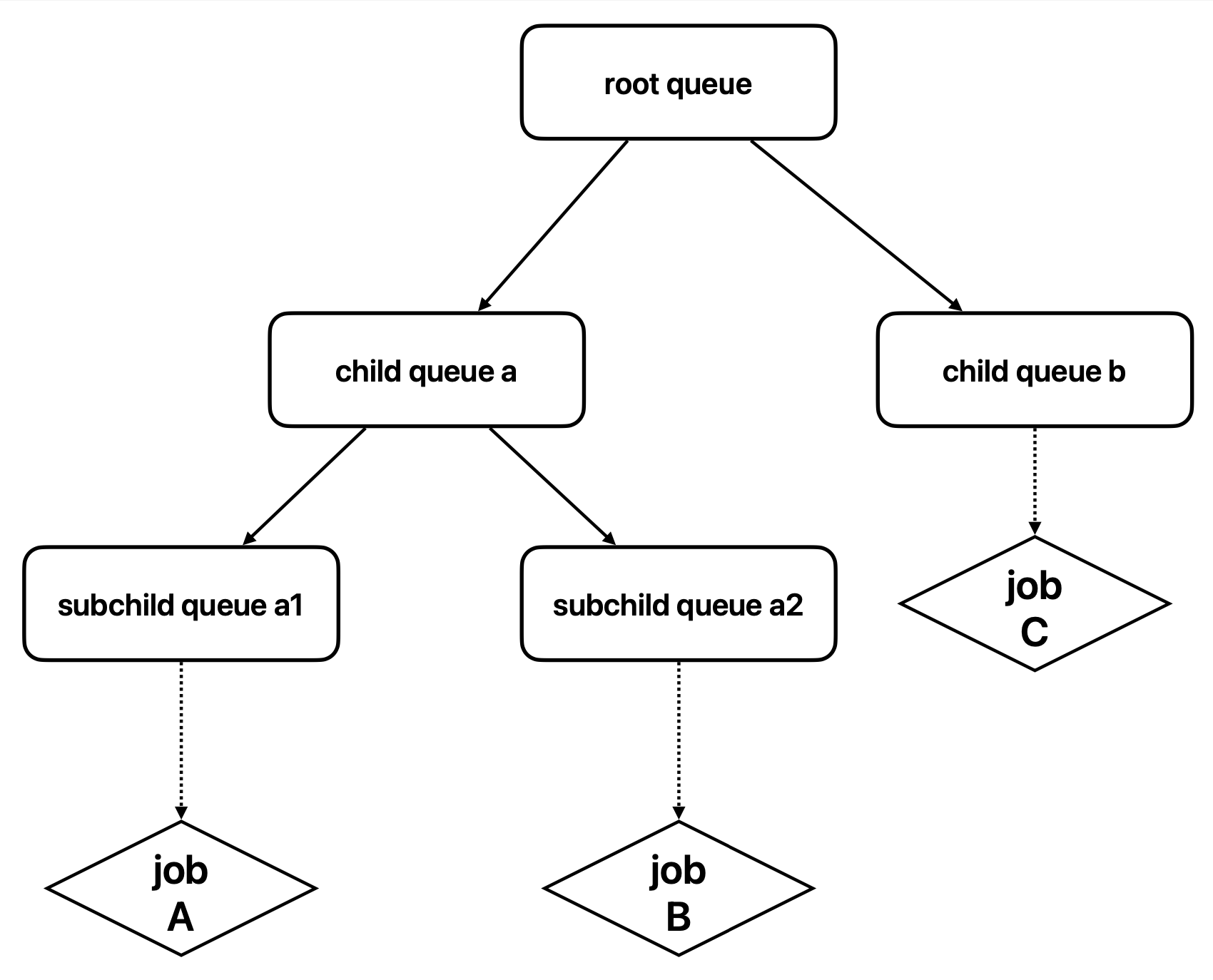
- Root Queue: Manages global resource allocation.
- Department Queues: Represent resource pools for different departments or teams.
- Child Queues: Represent specific projects or tasks, where users submit jobs.
Use Cases
- Multi-Department Resource Sharing: Large enterprises can use hierarchical queues to fairly allocate and isolate resources across departments.
- Big Data Task Scheduling: Users migrating from YARN to Kubernetes can leverage hierarchical queues for seamless Big Data workload migration.
- AI Training and Inference: Hierarchical queues enable dynamic resource allocation and reclamation for AI tasks.
For detailed design and user guide, please refer to:
Design Document: hierarchical-queue-on-capacity-plugin.
Usage Document: Hierarchical Queue | Volcano.
Sincerely thanks to community developer: @Rui-Gan for this contribution!
Multi-Cluster AI Job Scheduling: Unified Management and Efficient Scheduling Across Clusters
As enterprise workloads grow, single Kubernetes clusters often fall short of meeting the demands of large-scale AI training and inference jobs. Users typically manage multiple Kubernetes clusters to achieve unified workload distribution, deployment, and management. Many users already deploy Volcano across multiple clusters, managed by Karmada. To better support AI jobs in multi-cluster environments, Volcano has incubated the Volcano Global sub-project, extending Volcano’s powerful scheduling capabilities to multi-cluster scenarios. This project provides a unified scheduling platform for multi-cluster AI jobs, supporting cross-cluster job distribution, resource management, and priority control.
Core Capabilities
Volcano Global enhances Karmada with the following features to meet the complex demands of multi-cluster AI job scheduling:
- Cross-Cluster Volcano Job Scheduling: Users can deploy and schedule Volcano Jobs across multiple clusters, maximizing resource utilization.
- Queue Priority Scheduling: Supports cross-cluster queue priority management, ensuring high-priority queues receive resources first.
- Job Priority Scheduling and Queuing: Enables job-level priority scheduling and queuing across clusters, ensuring critical tasks are executed promptly.
- Multi-Tenant Fair Scheduling: Provides fair resource allocation across tenants, preventing resource contention.

For detailed deployment and user guide, please refer to: Multi-Cluster AI Job Scheduling | Volcano.
Sincerely thanks to community developers: @Vacant2333, @MondayCha, @lowang-bh, @Monokaix for their contributions!
Online and Offline Workloads colocation with Dynamic Resource Oversubscription: Maximizing Resource Utilization While Ensuring SLO
Background: The Challenge of Resource Utilization
As cloud-native technologies advance, Kubernetes has become the “operating system” of the cloud-native era, with more workloads migrating to Kubernetes platforms. However, despite the flexibility and scalability of cloud-native technologies, data center resource utilization remains low. Online workloads (e.g., microservices) often exhibit peak-and-trough patterns, leaving resources idle during troughs and insufficient during peaks. To improve resource utilization while ensuring high-priority workload SLOs (Service Level Objectives), Volcano introduces a cloud-native colocation solution, combining online and offline workloads with dynamic resource oversubscription to maximize cluster resource utilization while ensuring online workload stability.
Cloud-native colocation involves deploying online workloads (e.g., real-time services) and offline workloads (e.g., batch jobs) on the same cluster. During online workload troughs, offline workloads utilize idle resources; during peaks, offline workloads are throttled to ensure online workload resource needs. This dynamic resource allocation mechanism not only improves resource utilization but also ensures online workload quality of service.
Industry Practices: Volcano’s Unique Advantages
While many companies have explored colocation technologies, existing solutions often fall short, such as being tightly coupled with Kubernetes, using rough oversubscription calculations, or offering inconsistent user experiences. Volcano addresses these issues with the following unique advantages:
- Native Support for Offline Job Scheduling: Volcano Scheduler natively supports offline job scheduling without additional adaptation.
- Non-Invasive Design: No modifications to Kubernetes are required, allowing users to adopt Volcano without altering existing cluster architectures.
- Dynamic Resource Oversubscription: Real-time calculation of resources can be oversold ensures a balance between resource utilization and QoS.
- OS-Level Isolation and Guarantees: Kernel-level resource isolation ensures online workload priority and stability.
Volcano Cloud-Native Colocation Solution: End-to-End Resource Optimization
Volcano’s cloud-native colocation solution provides end-to-end resource isolation and sharing mechanisms, including the following core components:
Volcano Scheduler: Manages unified scheduling of online and offline workloads, offering abstractions like queues, groups, job priorities, fair scheduling, and resource reservations to meet the needs of microservices, Big Data, and AI workloads.
Volcano SLO Agent: A daemonset running on each node, the SLO Agent monitors node resource usage, dynamically calculates resources that can be oversold, and allocates them to offline workloads. It also detects CPU/memory pressure and evicts offline workloads when necessary to ensure online workload priority.
Enhanced OS: Volcano implements fine-grained QoS guarantees at the kernel level, using cgroups to set resource limits for online and offline workloads, ensuring online workloads receive sufficient resources even under high load.
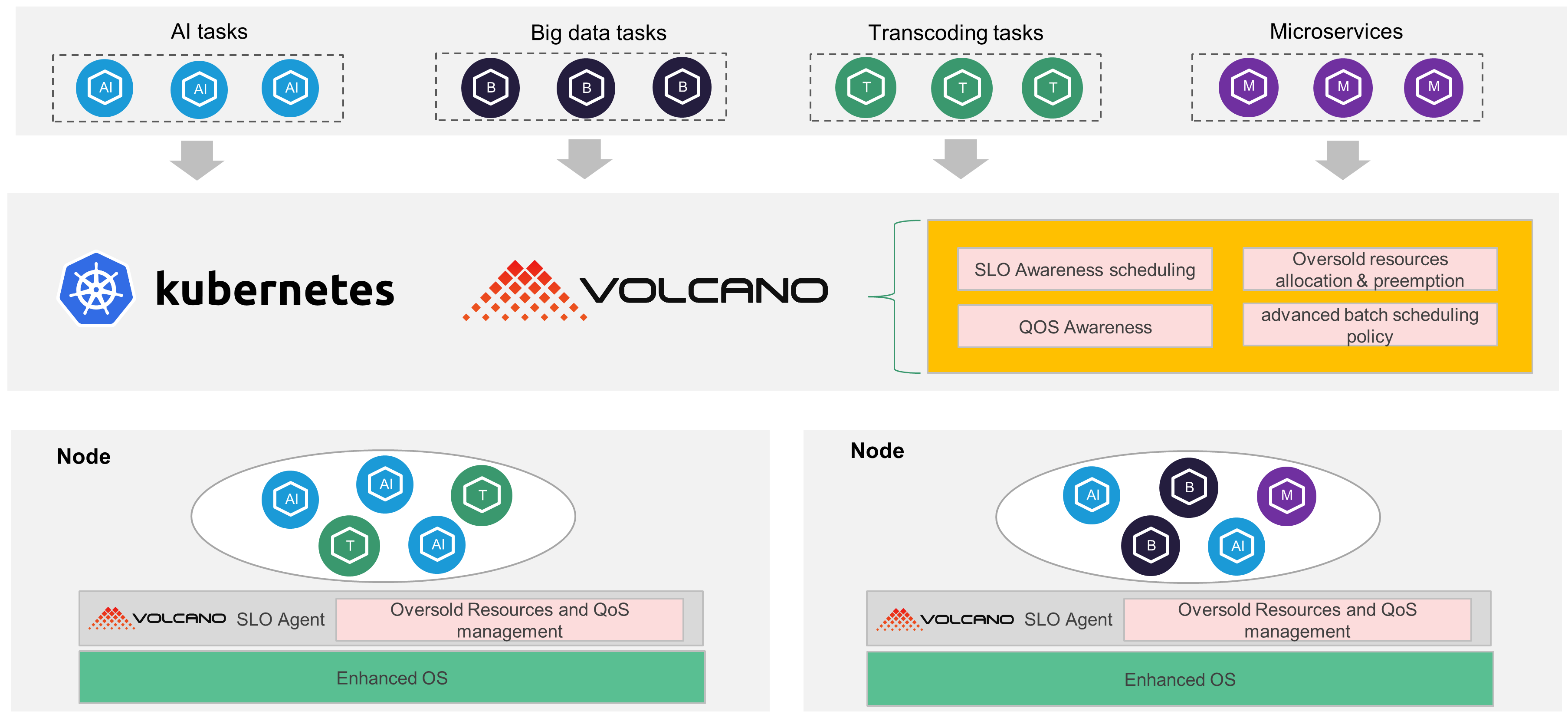
Core Capabilities: Balancing Resource Utilization and Stability
Volcano’s cloud-native colocation solution offers the following key capabilities to achieve both resource utilization and workload stability:
- Unified Scheduling: Supports unified scheduling of microservices, batch and AI jobs.
- QoS-Based Resource Model: Provides QoS-based resource management for online and offline workloads, ensuring high-priority workload stability.
- Dynamic Resource Oversubscription: Dynamically calculates oversellable resources based on real-time CPU/memory usage, maximizing resource utilization.
- CPU Burst: Allows containers to temporarily exceed CPU limits, avoiding throttling during critical moments and improving responsiveness.
- Network Bandwidth Isolation: Supports node-level network bandwidth limits, ensuring online workload network requirements.
For detailed design and user guide, please refer to: Cloud Native Colocation | Volcano.
Sincerely thanks to community developer: @william-wang for this contribution!
Load-Aware Descheduling: Intelligent Cluster Resource Balancing
In Kubernetes clusters, dynamic workload changes often lead to uneven node resource utilization, causing hotspots that impact cluster stability and efficiency. To address this, Volcano v1.11 introduces Load-Aware Descheduling, dynamically adjusting Pod distribution based on real node load to ensure balanced resource utilization and avoid hotspots, improving overall cluster performance and reliability. Load-aware descheduling is incubated in the sub-project: https://github.com/volcano-sh/descheduler.
Core Capabilities:
- Load-Aware Scheduling: Monitors real CPU and memory load metrics to dynamically adjust Pod distribution, avoiding reliance on Pod Request-based scheduling.
- Timed and Dynamic Triggers: Supports CronTab-based or fixed-interval descheduling to adapt to different scenarios.
Use Cases:
- Uneven Node Resource Utilization: Balances node load when some nodes are overutilized while others are underutilized.
- Hotspot Node Management: Migrates Pods from overloaded nodes to ensure stability.

Technical Highlights:
- Descheduling Based on Actual Load:
Unlike traditional scheduling strategies based on Pod Requests, Volcano’s load-aware descheduling is more precise, accurately reflecting the actual resource usage of nodes.
- Seamless Integration with Kubernetes Ecosystem:
Compatible with the native Kubernetes scheduler, enabling load-aware descheduling without requiring additional configurations.
- Flexible Policy Configuration:
Users can customize descheduling intervals or trigger conditions based on business requirements , ensuring flexibility and controllability in scheduling.
For detailed user guide, please refer to: Load-aware Descheduling | Volcano.
Sincerely thanks to community developer: @Monokaix for this contribution!
Fine-Grained Job Fault Recovery: Efficient Task Interruption Handling
In AI, Big Data, and HPC scenarios, job stability and fault recovery are critical. Traditional fault recovery strategies often restart entire Jobs when a single Pod fails, wasting resources and potentially restarting training from scratch. With the rise of checkpointing and resume-from-checkpoint techniques, single Pod failures no longer require full Job restarts. Volcano v1.11 introduces Fine-Grained Job Fault Recovery feature, offering flexible fault handling mechanisms to efficiently manage task interruptions and improve training efficiency.
Core Capabilities:
Supporting Pod-Granular Restart Policies
Users can configure policies to restart only failed Pods or their associated Tasks, avoiding unnecessary Job restarts and reducing resource waste.
Restarting a Single Pod:
When a specific Pod fails, only that Pod is restarted, leaving other running tasks unaffected.policies: - event: PodFailed action: RestartPodRestarting an Entire Task:
When a Pod fails, the entire Task (a group of Pods) to which it belongs is restarted. This is suitable for scenarios requiring consistency within a task group.policies: - event: PodFailed action: RestartTask
Support for Setting Timeouts for Actions
Pod failures may be caused by transient issues (e.g., network fluctuations or hardware problems). Volcano allows users to set timeout periods for failure recovery actions. If the Pod recovers within the timeout period, no restart is performed, avoiding unnecessary intervention.
Example Configuration: If a Pod fails and is restarted but does not recover within 10 minutes, the entire Job is restarted.
policies: - event: PodFailed action: RestartPod - event: PodEvicted action: RestartJob timeout: 10m
New PodPending Event Handling
When a Pod remains in the Pending state for an extended period due to insufficient resources or topological constraints, users can set a timeout for the Pending event. If the Pod does not start running after the timeout, the entire Job can be terminated to avoid resource waste.
Example Configuration:
If a Pod remains in the Pending state for more than 10 minutes, the Job will be terminated.policies: - event: PodPending action: TerminateJob timeout: 10m
Applicable Scenarios:
AI Large Model Training:
In distributed training, the failure of a single Pod does not affect the overall training progress. Fine-grained failure recovery strategies enable quick task recovery, avoiding the need to restart training from scratch.Big Data Processing:
In batch processing tasks, failures of individual tasks can be resolved by restarting a single Pod or Task, eliminating the need to restart the entire Job and improving processing efficiency.High-Performance Computing (HPC):
In HPC scenarios, task stability and efficient recovery are critical. Fine-grained failure recovery strategies minimize task interruption time.
Technical Highlights:
Flexible Policy Configuration:
Users can customize failure recovery policies based on business requirements, supporting Pod, Task, and Job-level restart operations.Timeout Mechanism:
By setting timeout periods, unnecessary restarts due to transient issues are avoided, enhancing Job stability.Seamless Compatibility with Checkpointing:
Perfectly integrates with checkpointing and resumption technologies in AI scenarios, ensuring efficient recovery of training tasks.
For detailed design and user guide, please refer to: How to use job policy.
Sincerely thanks to community developer: @bibibox for this contribution!
Volcano Dashboard: A Resource Visualization Component
The Volcano Dashboard is an official resource visualization component for Volcano. After deploying Volcano, users can deploy the dashboard to view and manage cluster resources through a graphical interface. The project is available at: https://github.com/volcano-sh/dashboard.
Current features include:
- Cluster overview, including Job counts, statuses, completion rates, Queue counts, and resource utilization.
- Job and Queue lists with filtering, sorting, and search capabilities.
- Pod lists with filtering, sorting, and search capabilities.
Sincerely thanks to community developers: @WY-Dev0, @Monokaix for their contributions!
Volcano Supports Kubernetes v1.31
Volcano closely follows Kubernetes releases, with full support for Kubernetes v1.31, including comprehensive UT and E2E testing to ensure functionality and reliability.
To contribute to Volcano’s Kubernetes version adaptation, please refer to: adapt-k8s-todo.
Sincerely thanks to community developers: @vie-serendipity, @dongjiang1989 for their contributions!
Volcano Job Supports Preemption Policy
Volcano Jobs now support PreemptionPolicy, allowing users to configure whether Jobs can preempt other Pods. Jobs with PreemptionPolicy: Never will not preempt resources, ensuring stability.
For configuration examples, please refer to: how to configure priorityclass for job.
Sincerely thanks to community developer: @JesseStut for this contribution!
Performance Optimization: Efficient Scheduling at Scale
In Volcano, Queue is one of the most fundamental and critical resources. The status field of a Queue records the states of PodGroups, such as Unknown, Pending, Running, Inqueue, and Completed. However, in large-scale scenarios, frequent changes in PodGroups within a Queue (e.g., when a large number of short-lived tasks are repeatedly submitted) can cause many PodGroups to transition from Running to Completed. In such cases, the Volcano Controller needs to frequently refresh the status field of the Queue, placing significant pressure on the APIServer. Additionally, the Volcano Scheduler updates the status.allocated field of the Queue after Job scheduling, which can lead to Queue update conflicts in large-scale environments, further impacting system performance.
To completely resolve the issues of frequent Queue refreshes and update conflicts in large-scale scenarios, Volcano v1.11 has optimized the Queue management mechanism by migrating PodGroup statistics to Metrics, eliminating the need for persistent storage. This optimization significantly reduces the pressure on the APIServer while improving the overall performance and stability of the system.
Key Improvements After Optimization
Migration of PodGroup Statistics to Metrics
PodGroup state data (e.g., Unknown, Pending, Running) is no longer stored in the status field of the Queue. Instead, it is recorded and displayed through the metrics system. Users can view the statistics of PodGroups in a Queue using the following commands:
View statistics for a specific Queue:
vcctl queue get -n [name]View statistics for all Queues:
vcctl queue list
Reduced APIServer Pressure
By migrating PodGroup statistics to Metrics, frequent updates to the status field of the Queue are avoided, significantly reducing the load on the APIServer and improving system throughput.
Resolved Queue Update Conflicts
In large-scale scenarios, Queue update conflicts have been effectively mitigated, ensuring the efficient operation of the scheduler.
For detailed design and metric names related to the migration of PodGroup state statistics to Metrics, please refer to: Queue podgroup statistics.
Sincerely thanks to community developer: @JesseStutler for this contribution!
Conclusion: Volcano v1.11, A New Era of Cloud-Native Batch Computing
Volcano v1.11 is not just a technological leap but a new chapter in cloud-native batch computing. Whether for AI large model training, Big Data scheduling, or resource optimization, Volcano v1.11 delivers powerful features and flexible solutions. We believe Volcano v1.11 will help users achieve greater heights in cloud-native batch computing, ushering in a new era of AI and Big Data scheduling!
Experience Volcano v1.11.0 now and step into a new era of efficient computing!
v1.11.0 release: https://github.com/volcano-sh/volcano/releases/tag/v1.11.0
Acknowledgments
Volcano v1.11.0 includes contributions from 39 community members. Sincerely thanks to all contributors:
| @QingyaFan | @JesseStutler | @bogo-y |
|---|---|---|
| @bibibox | @zedongh | @archlitchi |
| @dongjiang1989 | @william-wang | @fengruotj |
| @SataQiu | @lowang-bh | @Rui-Gan |
| @xovoxy | @wangyang0616 | @PigNatovsky |
| @Yanping-io | @lishangyuzi | @hwdef |
| @bood | @kerthcet | @WY-Dev0 |
| @raravena80 | @SherlockShemol | @zhifanggao |
| @conghuhu | @MondayCha | @vie-serendipity |
| @Prepmachine4 | @Monokaix | @lengrongfu |
| @jasondrogba | @sceneryback | @TymonLee |
| @liuyuanchun11 | @Vacant2333 | @matbme |
| @lekaf974 | @kursataktas | @lut777 |