本文2021年6月1日首发于容器魔方微信公众号,原文链接鹏城实验室启智章鱼教你彻底摆脱Kubernetes集群资源抢占难题
启智章鱼平台介绍
启智章鱼(OPENI-OCTOPUS)是一个集群管理和资源调度系统,由鹏城实验室、北京大学 、中国科学技术大学进行开发和维护。
完全开源:遵守Open-Intelligence许可
利用Kubernetes部署、管理和调度
支持在集群运行AI任务作业,支持GPU,NPU,FPGA,华为升腾芯片,寒武纪MLU等硬件
适用于AI的高性能网络,支持IB网络
提供监控分析工具,包括网络,平台和AI作业的监控分析
支持主流的深度学习框架
采用微服务结构
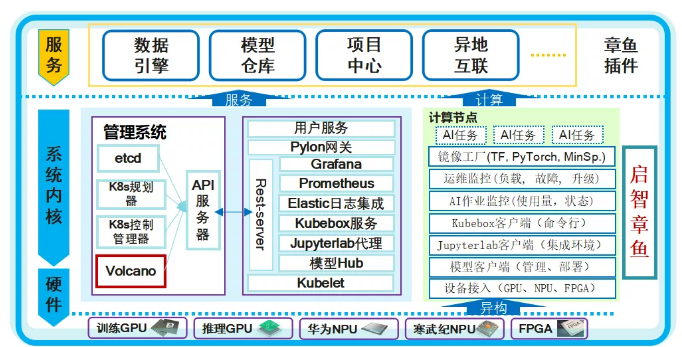
最底层为硬件层,可接入多种不同类型的异构硬件,包括CPU、GPU、NPU、FPGA等。这需要对不同的硬件进行适配,以便于上一层的Kubernetes服务识别和统一管理。
往上一层为平台的中间层,左边是管理节点的功能,一个是kubernetes本身的功能,包括编排规划,控制管理,调度方面我们使用的是Volcano。然后通过api-server和我们开发集成的服务通信。
我们开发的rest-server模块负责系统的核心功能,并集成了Grafana,普罗米修斯等监控工具,ES日志工具,Jupyterlab代理,模型仓库等功能。
右边是计算节点的能力,计算节点上有镜像工厂、运维监控、作业监控、kubebox客户端、用户登进容器的Jupyterlab客户端。
最上层是系统所提供的服务,对用户而言它拥有数据引擎,模型仓库,项目中心的能力,还能通过异地互联的方式,为异地用户提供集群服务。
业务场景与挑战
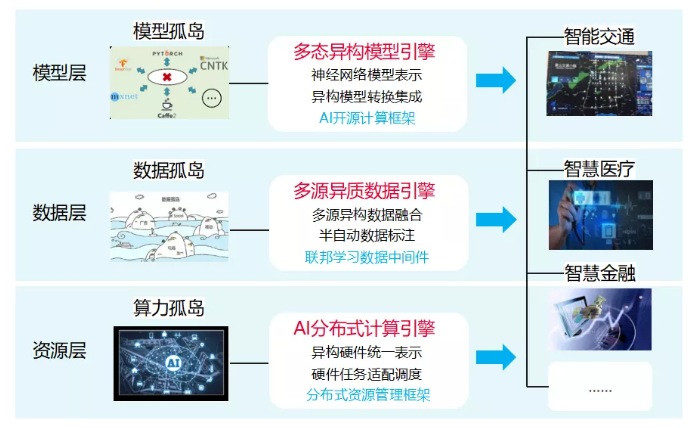
启智章鱼平台在设立之初直到目前主要是为实验室内外的科研团队服务。它们包含交通、医疗、金融等方面的模型开发,模型训练或者模型推理方面的需求。如一些车辆追踪算法,医疗影像识别,辅助诊断算法,金融领域的量化算法。这些各个领域的算法会用到一些深度学习的算法,对计算资源的要求比较高。
平台要解决传统平台的模型孤岛、数据孤岛、算力孤岛问题。
在模型层面,提供多态异构的模型引擎,支持常见的开源计算框架,并提供各种常见计算框架的模型转换的能力。
在数据层,提供多源异质数据引擎,支持异构数据融合,并且提供半自动数据标注的能力。
在资源层,提供AI分布式计算引擎,一方面是对异构硬件的统一表示,另外的重点是对作业的调度。
业务场景
业务以面向实验室内外的科研AI任务为主,包括智慧交通、医疗、金融等领域的算法训练与推理
高端异构硬件资源优势,150P+级算力集群和10PB级高速存储
支持快速和灵活部署,系统运行可靠稳定,方便外部团队使用
挑战
缺少一个高性能计算平台,满足复杂场景的业务诉求
高效利用异构硬件资源,支持灵活调度策略,需解决资源抢占难题,避免关键任务资源饿死现象
系统架构需可扩展,服务高可用
Why Volcano?
针对这些挑战,我们在选型时主要考虑有以下几个方面:
1)首先自研还是开源。在调研了目前社区已有的开源项目之后,发现它们能够满足我们的基本诉求和对复杂业务场景的需求。
2)基于减少开发量的考虑,选择拿来主义。我们对比了常见的开源资源调度器。首先是K8S默认调度器,该调度器对批量调度并不友好,不能满足我们的要求。Yarn调度器是基于Hadoop的,而我们现在的架构已经转型为基于k8s,也不符合我们的要求。另外是kube-batch和volcano,kube-batch是volcano的前身,且volcano对深度学习支持比较友好,对各种常见计算框架的任务类型都有支持,另外它有一套插件化的调度策略实现机制,方便实现新的插件来开发我们的特定调度策略。
因此我们选择集成volcano,使用volcano的能力来应对启智章鱼面对的业务场景挑战。具体来说,volcano对我们有以下价值:
完善的架构和生态,社区反馈很及时,开发者比较多,发展很快
上文提到的插件机制,方便自定义新的调度策略
Volcano支持任务队列的机制,这对我们很重要。我们基于任务队列,能够将集群进行逻辑分组,方便对用户进行项目制管理。一方面能够对不同项目配置不同限额的计算资源,另一方面能将不同类型的作业分到不同的任务队列中进行管理。对作业和计算资源的管理更加精细化。
可以使用Volcano的binpack等插件组成多种多样的调度策略,以binpack插件为例,其使用的装箱算法能够解决资源碎片的问题,能够很好的提高集群的整体使用率。
基于Volcano的二次开发
Volcano虽然功能很强大,但为了能够进一步应对复杂的业务场景,我们也做了二次开发,新增了一些新的能力。
我们做的第一个二次开发是资源状态的统计与管理功能。这里的资源不单指集群计算资源,也指用户提交作业后,k8s服务中生成的Job、Task、Pod等资源。
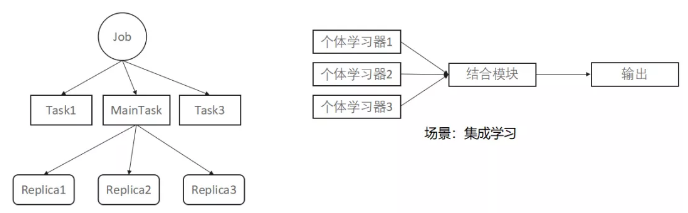
我们需要对整个资源的状态信息,状态转换都有很好的掌握,并且可以自定义资源状态转换的条件与回调事件,可以在业务逻辑层订阅自定义的Event与相对应的Policy.
考虑以下的一种业务场景。有一种使用集成学习算法的训练任务,一般可以使用分布式的训练方式。它有一个结合模块,还有若干个体学习器,每个个体学习器使用一种算法来训练任务,结合模块结合各个个体学习器的结果,来输出最终结果。如果结合模块算出了最终的结果,整个训练任务就可以结束。在基于k8s的实现中,使用集成学习的训练作业整体是一个Job,结合模块和各个个体学习器都是这个Job下面的一个Task,Task下面可以再创建一个或者多个副本Pod。我们的场景需求是只要结合模块这个Task运行成功,就让整个Job退出,而不必等到所有的Task都成功再退出。那我们就需要针对这种场景,可以在调度器自定义一种Job退出的策略,并且可以在业务层面去使用。集成学习这个场景需要一种特定的策略,其他场景也需要相应的策略。这就要求我们去二次开发volcano调度器。
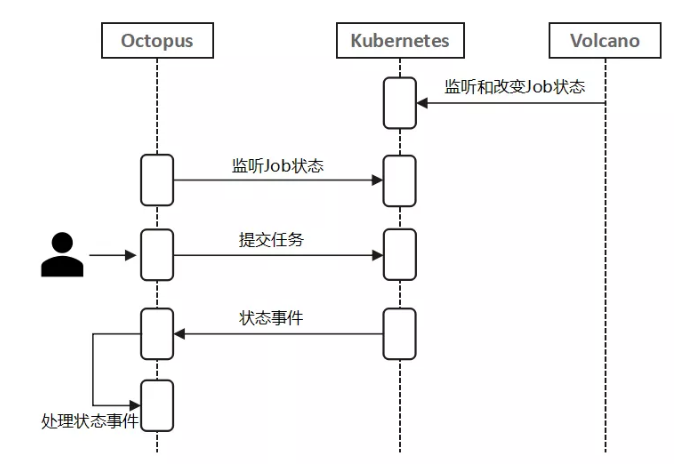
上图的交互图显示了启智章鱼,k8s,volcano之间关于作业状态的信息传递。
首先,volcano和启智章鱼都会一直监听k8s所有作业的状态;然后,用户提交了作业到k8s之后,volcano会根据监听到的k8s作业启动的pod状态去更新Job的状态;最后,启智章鱼监听到这些Job的状态改变,会去处理这些状态改变事件。
基于这个交互图,我们发现 问题的关键在于volcano如何去更新Job在k8s中的状态。
我们做了以下几点二次开发来实现目标:
1)实现Job,Task,Replica的三级别状态机
资源状态统计与回显更加详细
更加细粒度的Job生命周期管理
2)实现自定义Event和Policy,能够解决类似集成学习应用场景的问题,自定义一个Event叫做MainTaskEvent, 在确定的Task运行结束时在调度器发布这个事件来结束整个Job
3)实现生命周期回调钩子,可以在三个级别的状态机的任一状态转移事件中都加入回调钩子,以此支撑多样化的业务场景需求。例如我们的计费功能实现,就是基于Job的开始事件和结束事件来统计Job的运行时长。
Privilege Action
问题
任务队列资源饿死现象,大作业一直等待
紧急作业、关键作业需要优先调度
用户作业可能在线开发,不可随意终止
Volcano已有能力
同队列中不同优先级Job的抢占,无法区分Job所来自的租户身份
以Pod为单位进行驱逐
立即抢占
需求
同队列中作业来自不同租户,不同租户拥有不同优先级和抢占权限
以Job为单位进行驱逐
延时抢占
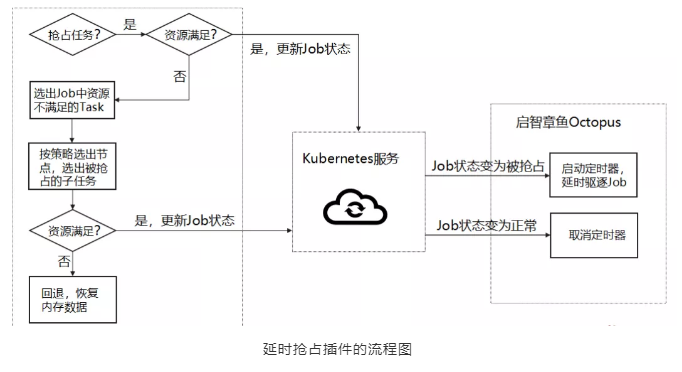
上图为延时抢占插件的流程图。最左边是插件在调度器的运行逻辑。中间是k8s服务,最右边是启智章鱼的核心模块。
具体的实现是在volcano中去找出具体需要被抢占的作业,这些作业所占用的计算资源要足够满足当前等待的优先作业。然后更新k8s中这些作业的状态,启智章鱼的核心模块一监听到这些状态改变,就会启动定时器来准备驱逐这些任务。如果定期器倒计时还没结束,抢占任务被取消或者抢占任务已经因为其他作业释放资源,满足了运行条件而不需要继续抢占,这个定时器也会被取消。
具体看下我们做了什么开发:
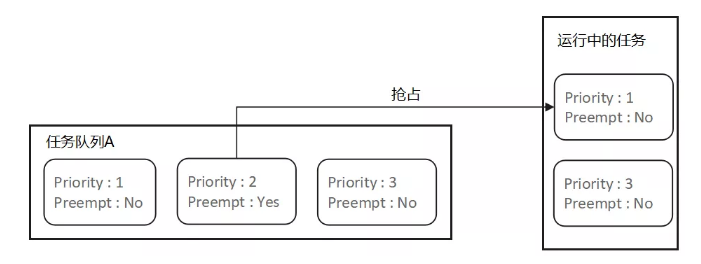
1)为每个作业增加了一个布尔属性,叫Preemt,表示这个作业是否为一个抢占作业。
- 队列内抢占作业只能抢占同个队列中优先级较低的作业。
2)以Job为单位进行驱逐,而不是以Pod为单位驱逐。
驱逐待选的Pod按照所属JobID排序,可减少受影响的Job数量
由调度器通知启智章鱼,在业务层对Job进行停止
3)延时抢占
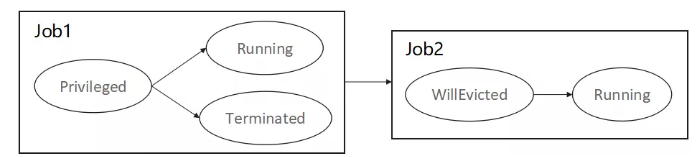
为Job状态机增加Privileged和WillEvicted状态
进入Privileged和WillEvicted状态的Job不可被其他Job抢占
如果抢占或被抢占的Job状态发生变化,另一方的状态也要相应改变
收益
能力增强
满足分布式大规模训练任务的需求
支持多种AI计算框架
插件化调度器,支持自定义开发,适应复杂业务场景
多队列调度,实现硬件资源的分组与组间动态资源分配
性能优化
硬件资源利用率大幅提高,达到90%以上
作业平均调度时延大幅降低,由使用Yarn调度器的平均任务等待时间60秒降到现在的10秒
系统稳定增强,集群节点资源利用率平衡度好,减少了节点间因资源使用差异度引起的运维工作
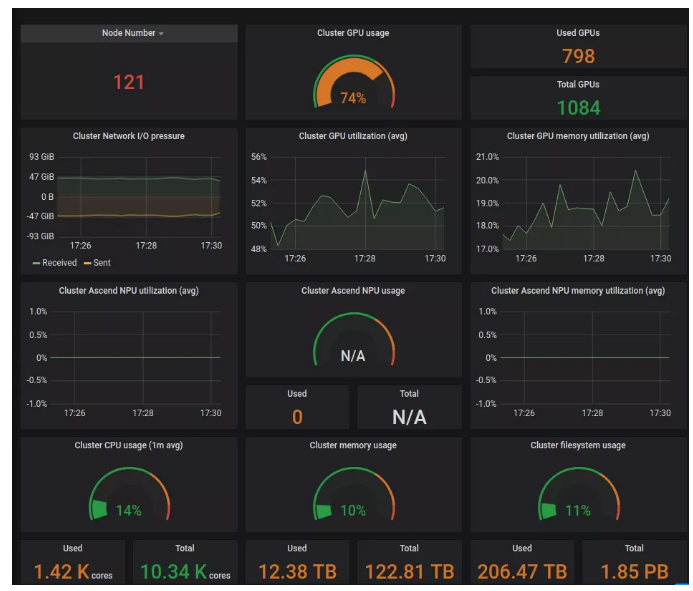
上图为系统在Grafana显示情况:
管理120+个节点,总GPU卡数为1.1K张,GPU在超负荷情况下使用率可达90%以上
各节点间资源利用率平衡性较好,差异度低于20%
2019年上线以来,运行作业数为12w+