HPC on Volcano: How Containers Support HPC Applications in the Meteorological Industry
This article was firstly released at
Container Cubeon October 27th, 2020, refer to HPC on Volcano:容器在气象行业HPC高性能计算场景的应用
Kubernetes has become the de facto standard for cloud native application orchestration and management. An increasing number of applications are being reconstructed or built to employ Kubernetes. High performance computing (HPC) is a popular distributed computing mode and is widely used in many fields. For users who have deployed HPC applications and are eager to containerize and manage their applications using Kubernetes, Volcano, CNCF's first distributed scheduling system for batch computing, is a good choice. Volcano supports multiple types of computing frameworks, such as Spark, TensorFlow, and Message Passing Interface (MPI). This article uses a traditional HPC application, the Weather Research and Forecasting (WRF) model, as an example to describe how Volcano works for HPC applications.
About HPC
HPC and HPCC are two common terms in the area of computing jobs. HPCC is short for high performance computer cluster, which integrates a large amount of computer software and hardware to conduct parallel computing on large computing jobs. HPC is widely used in CAE simulation, animation rendering, physics, chemistry, oil exploration, and life, meteorological, and environmental science.
An HPCC consists of three parts:

-
Portable Batch System (PBS): A resource manager that manages all node resources in a cluster. Other common resource management systems include Slurm and Platform Load Sharing Facility (or simply LSF).
-
Maui: A third-party job scheduler that supports multiple priority-based scheduling policies, resource reservations, and preemption mechanisms. Maui provides more advanced scheduling services than the default schedulers embedded in most resource managers.
-
Open MPI: An upper-layer communication environment that provides a communication library and compilation functions and starts distributed tasks.
PBS and Maui are imperceptible to users. Users only need to submit jobs in the mode defined by PBS and do not need to understand internal implementation details. However, users are required to learn how to use Open MPI to compile parallel computing applications.
The following uses mpirun -np 4 ./mpi_hello_world as an example to illustrate how an MPI job runs.
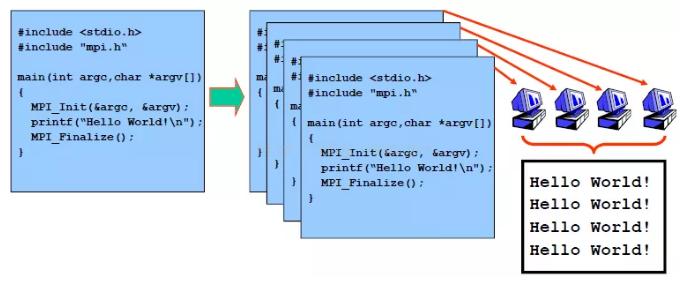
-
Invoke Open MPI or other MPI libraries to compile the source code. In this example, Hello World! is printed.
-
Use a compiler that supports MPI to compile the executable program mpi_hello_world.
-
Distribute mpi_hello_world to each node. You can also make mpi_hello_world accessible by sharing the file system.
-
Run mpirun to execute mpi_hello_world in parallel.
About WRF
The Weather Research and Forecasting (WRF) model is a common HPC application. WRF is a mesoscale numerical weather prediction (NWP) system designed for both atmospheric research and forecasting. It allows researchers to produce simulations based on real or hypothetical atmospheric conditions.
WRF consists of multiple modules with different processing flows. The following illustrates a WRF process.
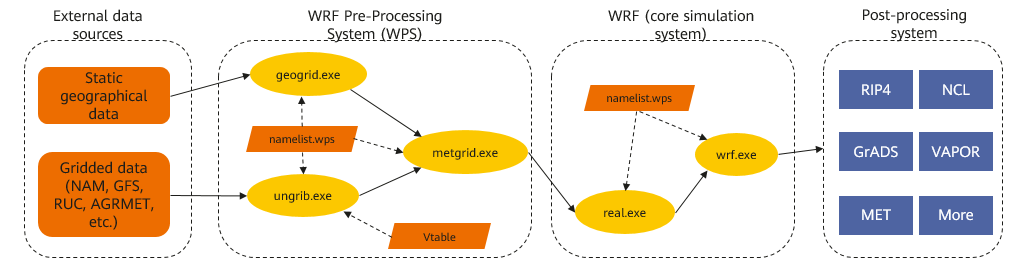
As shown in the figure above, this WRF process has four parts:
-
External data sources
-
WRF Pre-Processing System (WPS)
-
WRF, which is the core simulation system
-
Post-processing system
External Data Sources
The WRF model data includes static geographical data and gridded data. Geographical data refers to geographical information in a domain, such as mountains, rivers, lakes, and forests. Gridded data refers to the meteorological environment data in a domain, such as temperature, wind speed, wind direction, air humidity, and rainfall.
WPS
——WPS,WRF Pre-processing System)
WPS loads geographical and meteorological data, interpolates meteorological data to grids, and finally provides data input for the WRF. It consists of three main programs:
-
geogrid.exe: defines model projections, domain range, and nesting relationships, interpolates terrestrial parameters, and processes terrain and gridded data.
-
ungrib.exe: extracts required meteorological parameters from the GRIB data.
-
metgrid.exe: interpolates meteorological parameters to simulation domains.
The three programs work together to generate data used for meteorological simulation. Currently, the three programs do not support MPI parallel computing.
WRF
As the core module of the WRF model, WRF performs simulation and prediction based on the meteorological information generated by WPS. WRF consists of two main programs:
-
real.exe: initializes the actual meteorological data.
-
wrf.exe: simulates and predicts results.
real.exe and wrf.exe can run as MPI parallel jobs to improve the computing speed.
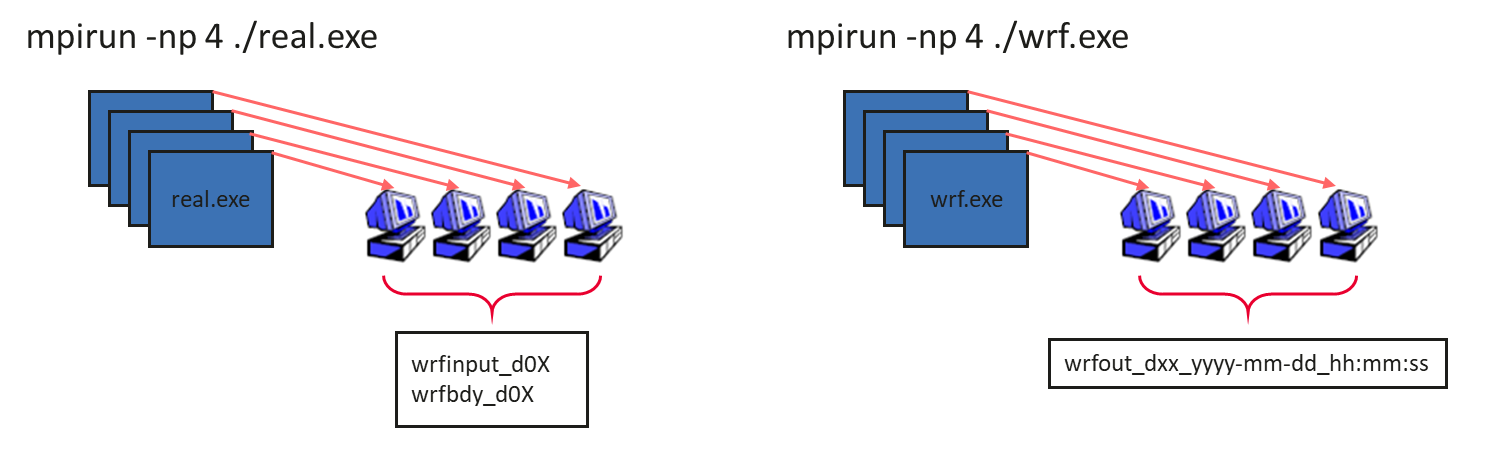
As shown in the preceding figure, wrfinput_d0X and wrfbdy_d0X are the calculation results generated by real.exe. wrf.exe performs meteorological simulation based on these results to generate the final result wrfout_dxx_yyyy-mm-dd_hh:mm:ss, which is verified and displayed by the post-processing system.
Post-Processing System
The post-processing system verifies and displays the calculation results generated by WRF. It consists of various third-party images and verification tools. The following figure shows the simulation and prediction results of the relative humidity in each area in CONUS 2.5km case.
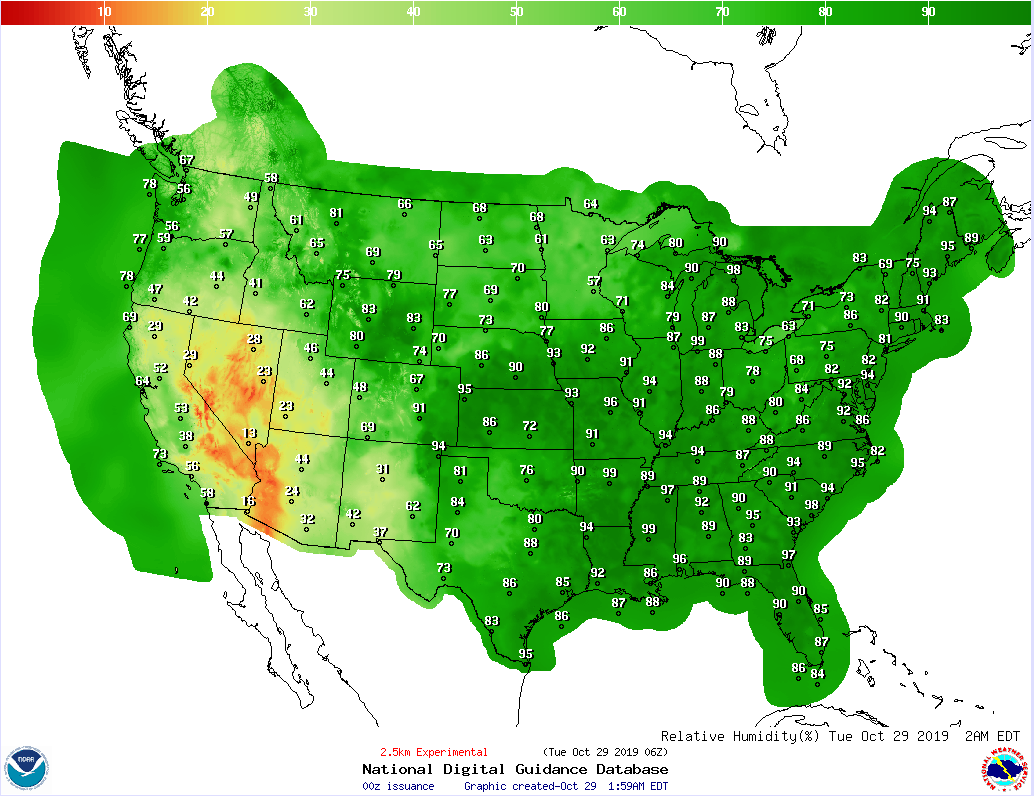
CONUS 2.5km refers to the 2.5 km resolution case covering the Continental U.S. (CONUS) domain. (In this case, the entire domain is divided into multiple cubes of 2.5 km x 2.5 km x 2.5 km. The meteorological information in each cube is considered consistent.)
HPC on Volcano

As mentioned above, an HPCC consists of a resource manager, scheduler, and MPI parallel computing library. In the container context, Kubernetes functions as the resource manager and Volcano functions as the scheduler.
To run HPC applications in the Kubernetes+Volcano environment is to run HPC jobs in containers, as shown in the following figure.

Two types of containers are involved: master and worker. The master container starts the mpirun and mpiexec commands, and the worker containers run computing jobs.
To support MPI jobs, Volcano has been enhanced to provide the following functions:
- Multiple pod charts, which are used to define master and worker pods at the same time
- Gang scheduling, which ensures that all pods in a job are simultaneously started
- Mapping of host IP addresses of the master and worker pods
- SSH password-free login between the master and worker pods
- Job lifecycle management
The following is an example of running an MPI job on Volcano.
- Define a Volcano MPI job by the mpi_sample.yaml file.
apiVersion: batch.Volcano.sh/v1alpha1
kind: Job
metadata:
name: mpi-job
labels:
# Set the job type based on service requirements.
"Volcano.sh/job-type": "MPI"
spec:
# Set the minimum number of required pods (less than the total number of replicas).
# For this example, set it to the total number of mpimaster and mpiworker replicas.
minAvailable: 3
# Specify Volcano as the scheduler.
schedulerName: Volcano
plugins:
# Configure SSH password-free authentication.
ssh: []
# Configure the network information, such as hosts file and headless Service, required for running the job.
svc: []
# Define a policy in which the entire MPI job will be restarted when a pod is evicted.
policies:
- event: PodEvicted
action: RestartJob
tasks:
- replicas: 1
name: mpimaster
# Define another policy in which the entire MPI job will be considered as complete when mpiexec execution completes.
policies:
- event: TaskCompleted
action: CompleteJob
template:
spec:
# The Volcano-related information will be stored in the /etc/Volcano directory.
containers:
# The master container will perform the following operations:
# 1. Start the sshd service.
# 2. Obtain the mpiworker container list from /etc/Volcano/mpiworker.host.
# 3. Run mpirun/mpiexec.
- command:
- /bin/sh
- -c
- |
MPI_HOST=`cat /etc/Volcano/mpiworker.host | tr "\n" ","`;
mkdir -p /var/run/sshd; /usr/sbin/sshd;
mpiexec --allow-run-as-root --host $`{MPI_HOST}` -np 2 mpi_hello_world;
image: Volcanosh/example-mpi:0.0.1
imagePullPolicy: IfNotPresent
name: mpimaster
ports:
- containerPort: 22
name: mpijob-port
workingDir: /home
resources:
requests:
cpu: "100m"
memory: "1024Mi"
limits:
cpu: "100m"
memory: "1024Mi"
restartPolicy: OnFailure
imagePullSecrets:
- name: default-secret
- replicas: 2
name: mpiworker
template:
spec:
containers:
# The worker containers will only start the sshd service.
- command:
- /bin/sh
- -c
- |
mkdir -p /var/run/sshd; /usr/sbin/sshd -D;
image: Volcanosh/example-mpi:0.0.1
imagePullPolicy: IfNotPresent
name: mpiworker
ports:
- containerPort: 22
name: mpijob-port
workingDir: /home
resources:
requests:
cpu: "100m"
memory: "2048Mi"
limits:
cpu: "100m"
memory: "2048Mi"
restartPolicy: OnFailure
imagePullSecrets:
- name: default-secret
- Commit the Volcano MPI job.

The job is executed.
- Check the execution result of the master pod.

The preceding execution result shows that Volcano clears only the worker pods and retains the master pod after the job completes. In this way, you can run the kubectl command to obtain the execution result.
Note that there may be latency in the container network. When a job starts, the master pod may fail to connect to the worker pods. If this happens, Volcano will automatically restart the master pod to make the job run properly.
If you intend to use Volcano to run a WRF job, you need to replace mpi_hello_world with real.exe and wrf.exe and perform the following operations:
-
Build Docker images, which must include a complete WRF running environment.
-
Mount the data (original or intermediate data) required for calculation to the corresponding container.
In this way, you can run meteorological simulation jobs in the Kubernetes+Volcano environment.