如何在大规模场景下调优 Volcano 性能
本文源自中国科学院主办的“开源软件供应链点亮计划”(OSPP)中的“Volcano 大规模性能测试与调优”项目。所有的实验数据与分析均已发布在作者的系列博客文章中(@Freshwlnd)。
1. 引言
1.1 背景与目标
Volcano 是一款主流的云原生批处理系统,广泛应用于 AI、大数据及 HPC(高性能计算)等场景中。本项目旨在通过大规模性能测试,系统性地复现并识别 Volcano 在承载数万个 Pod 负载时的性能瓶颈;最终产出一份实用的性能调优指南,并为未来的架构优化方向提供建议。
1.2 总体结论摘要
通过一系列系统性的实验,我们得出了以下核心结论:
- 性能高度依赖于应用场景:Volcano 的性能表现与具体的调度场景高度相关。当启用“Gang Scheduling”(协同调度)功能时,其性能表现远超其他调度器,充分彰显了其在批处理及 AI 场景下的核心优势。而在未启用 Gang Scheduling 的通用场景下,由于其专为复杂场景设计的 Job 管理功能引入了额外的开销,其性能仍存在一定的优化空间。
- Webhook 是主要性能瓶颈:在资源受限的大规模集群环境中,默认的 Webhook 配置(10 秒超时)是导致大规模 Pod 创建失败的直接诱因。此外,Webhook 验证链本身所引入的额外开销,也是影响整体性能的一个重要因素。
- Controller 工作线程(Worker Threads)的最佳取值:参数
--worker-threads并非“越大越好”。配置不当可能因耗尽计算资源或加剧 API-Server 资源争用而导致性能下降,呈现出一种典型的“V 型”性能曲线特征。 - CREATE/SCHEDULE 操作间的 API-Server 资源争用:在高并发场景下,Controller(负责 Pod 创建/CREATE)与 Scheduler(负责 Pod 调度/SCHEDULE)对 K8s API-Server/ETCD 的并发写操作会导致请求排队及重试;宏观表现为一种“阶梯式停顿”现象,即两类操作呈现出交替执行的表象。与此同时,盲目提高
CREATE(创建)速率,实际上可能会延长整体的调度耗时。
2. 测试与监控环境描述
本次测试的核心在于扩展开源项目 kube-scheduling-perf 框架,以在本地 Kind 集群中模拟大规模 Pod 调度场景。我们对该测试框架的源代码进行了详尽分析,并撰写了一系列博文,题为《云原生批量调度实战:Volcano 监控与性能测试》,现已发布于作者的博客(@Freshwlnd)上。
- 测试框架:
wzshiming/kube-scheduling-perf项目利用 Makefile 进行自动化编排,实现了集群的一键搭建、多场景基准测试的执行、监控数据的采集以及测试结果的归档。 - 数据采集:该框架通过
audit-exporter工具,从kube-apiserver的审计日志(audit.log)中精准捕获Pod Creation(Pod 创建)和Pod Schedule(Pod 调度)事件的时间戳。 - 核心指标:
- X 轴:测试运行时间(秒)。
- Y 轴:已完成
CREATE或SCHEDULE阶段的 Pod 累计数量。 - 曲线斜率:代表瞬时吞吐量(单位:Pods/秒),这是一项关键的性能指标。
- 图示示例:
3. 性能现象
3.1 核心性能现象
综上所述,我们在测试过程中观察到了以下性能特征:
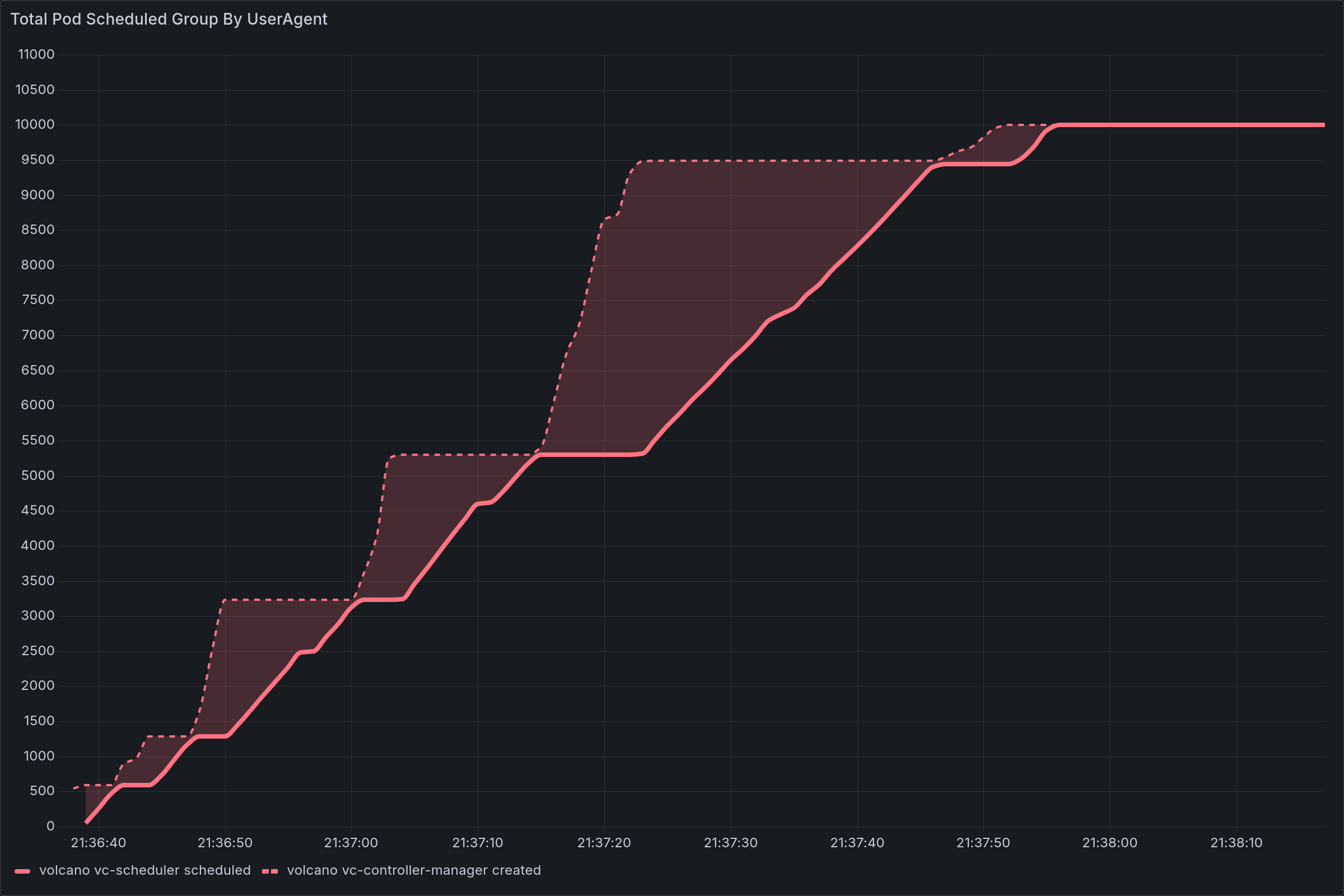
- 当未启用“Gang Scheduling”(成组调度)功能时,我们在 Volcano 中观察到了独特的性能特征:
-
吞吐量与“阶梯式”停滞:
CREATED(已创建)和SCHEDULED(已调度)这两条曲线呈现出明显的“阶梯式”形态,表现为“爆发式增长”与“停滞不前”两种状态交替出现。 -
大规模 Pod 创建失败:在某些测试场景下,当单个 Job(作业)包含的 Pod 数量极其庞大时(例如:20 个 Job × 500 个 Pod),在默认配置下,成功创建的 Pod 数量甚至不足 2000 个。
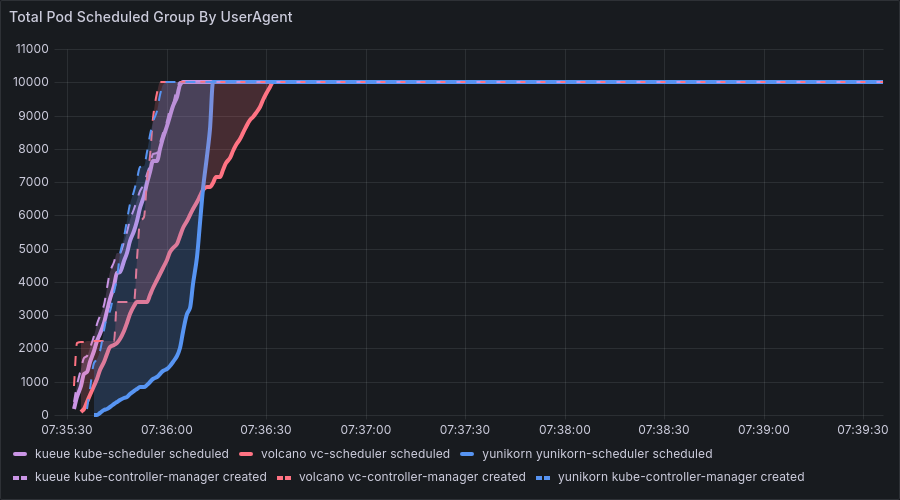
- 启用“成组调度”(Gang Scheduling)是 Volcano 的核心应用场景。在此场景下:
- 卓越的性能:得益于其高效的 PodGroup 管理机制及成组调度算法,Volcano 在性能上显著优于其他调度器。
- 必要的开销:尽管由于涉及更为复杂的计算,所有调度器在启用成组调度时都会导致总运行时间有所延长,但 Volcano 凭借其架构设计,依然保持着最高的运行效率。这充分印证了其作业管理功能的必要性与精巧性。因此,提供充足的资源是至关重要的。