网络拓扑感知调度用户指南
1 背景
在 AI 大模型训练场景下,模型并行(Model Parallelism)将模型拆分到多个节点上,训练过程中这些节点之间需要频繁、大量地交换数据。此时,节点间的网络传输性能往往成为训练瓶颈,显著影响训练效率。数据中心网络类型多样(如 IB、RoCE、NVSwitch 等),网络拓扑复杂,通常涉及多层交换机。两个节点之间的交换机越少,通信延迟越低、吞吐量越高。因此,用户希望将工作负载调度到吞吐量最高、延迟最低的最佳性能域,尽量减少跨交换机通信,以加速数据交换并提升训练效率。
为此,Volcano 提出了网络拓扑感知调度(Network Topology Aware Scheduling)策略,通过统一的网络拓扑 API 与智能调度策略,解决大规模数据中心 AI 训练任务中的网络通信性能问题。
2 功能
2.1 统一网络拓扑 API:准确表达网络拓扑
为屏蔽数据中心网络类型的差异,Volcano 定义了新的 CRD HyperNode 来表示网络拓扑,并提供标准化的 API 接口。相比传统用节点标签表示网络拓扑的方式,HyperNode 具有以下优势:
- 统一语义:HyperNode 以标准化方式描述网络拓扑,避免标签方式带来的语义不一致问题。
- 层次结构:HyperNode 支持树形层次结构,能更精确地表示实际网络拓扑。
- 易于管理:集群管理员可手动创建 HyperNode,或使用网络拓扑自动发现工具维护 HyperNode。
一个 HyperNode 表示一个网络拓扑性能域,通常映射到交换机或 ToR。多个 HyperNode 按层次连接形成树形结构。例如,下图展示了由多个 HyperNode 组成的网络拓扑:
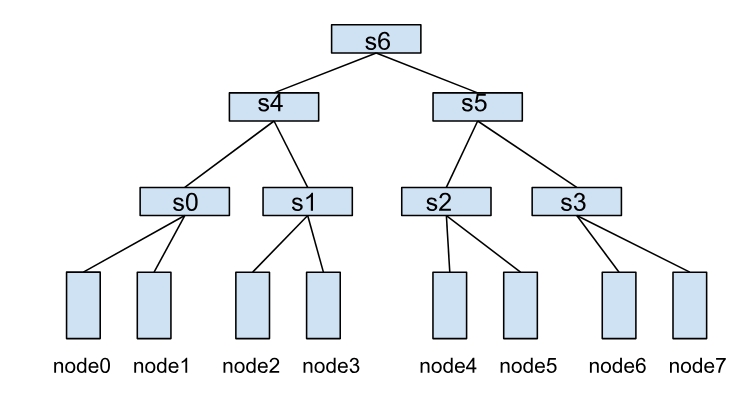
在该结构中,节点间的通信效率取决于彼此跨越的 HyperNode 层级。例如:
- node0 与 node1 同属 s0,通信效率最高。
- node1 与 node2 需跨越两层 HyperNode(s0→s4→s1),通信效率较低。
- node0 与 node4 需跨越三层 HyperNode(s0→s4→s6),通信效率最低。
2.2 HyperNode 自动发现:简化网络拓扑管理
为进一步降低网络拓扑信息的管理负担,Volcano 提供 HyperNode 自动发现功能。该功能自动发现集群内的网络拓扑结构,并根据发现结果创建、更新或删除相应的 HyperNode 自定义资源(CR)。
自动发现功能的主要优势包括:
- 自动化管理:从 UFM、RoCE、节点标签等多种数据源自动发现并维护 HyperNode 信息,无需人工维护。
- 实时更新:定期同步网络拓扑变化,确保 HyperNode 信息与实际网络状态一致。
- 可扩展架构:支持可插拔的 Discoverer 组件,用户可针对自有网络管理工具开发自定义发现逻辑。
借助该自动发现机制,用户可专注于作业调度配置,无需关心 HyperNode 创建与维护的复杂性,从而显著简化网络拓扑感知调度的部署与管理。
2.3 网络拓扑约束:提升网络通信效率
在 Volcano Job 中,可配置 NetworkTopology 字段,用于描述作业部署时的网络拓扑约束。具体约束配置如下:
mode:支持hard与soft模式。hard:硬约束,作业内任务必须部署在同一 HyperNode 内。soft:软约束,任务尽可能部署在同一 HyperNode 内。
highestTierAllowed:与hard模式配合使用,表示允许作业部署的最高 HyperNode 层级;mode为soft时无需配置该字段。
例如,以下配置表示作业只能部署在第 2 层及以下的 HyperNode 内(如 s4、s5 及其子节点 s0、s1、s2、s3),否则作业将保持 Pending 状态:
spec:
networkTopology:
mode: hard
highestTierAllowed: 2
通过配置该调度约束,用户可精确控制作业的网络拓扑要求,确保作业在满足条件的最佳性能域中运行,从而显著提升训练效率。
2.4 子组亲和策略:细粒度控制分布式作业的调度约束
在大模型训练场景中,完整训练任务所需资源巨大,通常无法部署在单一网络性能域内。需要将训练任务拆分为流水线并行(PP)或数据并行(DP),使各并行任务可跨网络性能域部署。
为此,Volcano 提供子组亲和策略(SubGroup Affinity Policy)。在 Volcano Job 中,可配置 partitionPolicy 字段对 Job 内 Pod 进行分区,并为每个分区配置网络拓扑约束。
调度时,每个分区遵循各自的网络拓扑约束,从而满足各并行任务分区的网络通信性能要求。
此外,每个分区还须满足 Gang 调度约束:仅当分区内所有 Pod 均满足调度条件时,该分区才允许被调度。
例如,以下配置表示:整个作业只能调度到第 2 层及以下的 HyperNode;Job 内 8 个 Pod 分为 2 个分区,每个分区只能调度到第 1 层 HyperNode。
spec:
networkTopology:
mode: hard
highestTierAllowed: 2
tasks:
- name: "task1"
replica: 8
partitionPolicy:
totalPartitions: 2
partitionSize: 4
networkTopology:
mode: hard
highestTierAllowed: 1
template:
# pod template
2.5 HyperNode 级装箱:提升网络拓扑性能域的资源利用率
调度带网络拓扑约束的工作负载时,调度器会优先将其调度到当前资源利用率较高的 HyperNode,以提升网络性能域内的资源利用率。
如下图所示,假设集群中有两个第 1 层 HyperNode,其中 HyperNode0 已有部分资源被其他任务占用。用户提交一个 Volcano Job,将其分为两个分区,每个分区配置 highestTierAllowed=1。
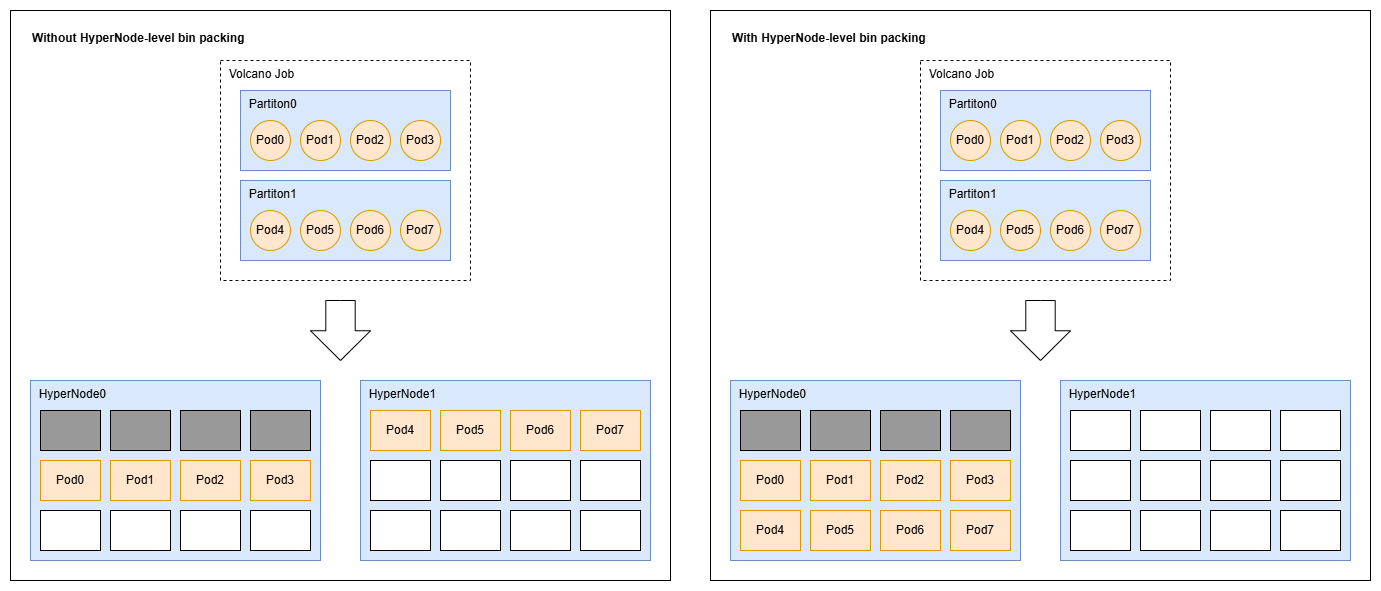
- 未启用 HyperNode 级装箱时,调度结果可能是:分区 0 调度到 HyperNode0,分区 1 调度到 HyperNode1。
- 启用 HyperNode 级装箱后,分区 0 和 1 都会优先调度到 HyperNode0。此时 HyperNode1 可作为完全空闲的 HyperNode 供其他任务使用。
此外,对于未配置网络拓扑约束的工作负载,调度器会优先将其调度到 HyperNode 级资源利用率更高的节点(会考虑各层 HyperNode),以减少 HyperNode 级资源碎片。
例如,如下图所示,集群由 8 个节点和 7 个 HyperNode 组成。当前 node0、node2、node4 的资源已被现有任务占用,其余节点空闲。此时用户向该集群提交包含两个独立 Pod 的 Volcano Job。
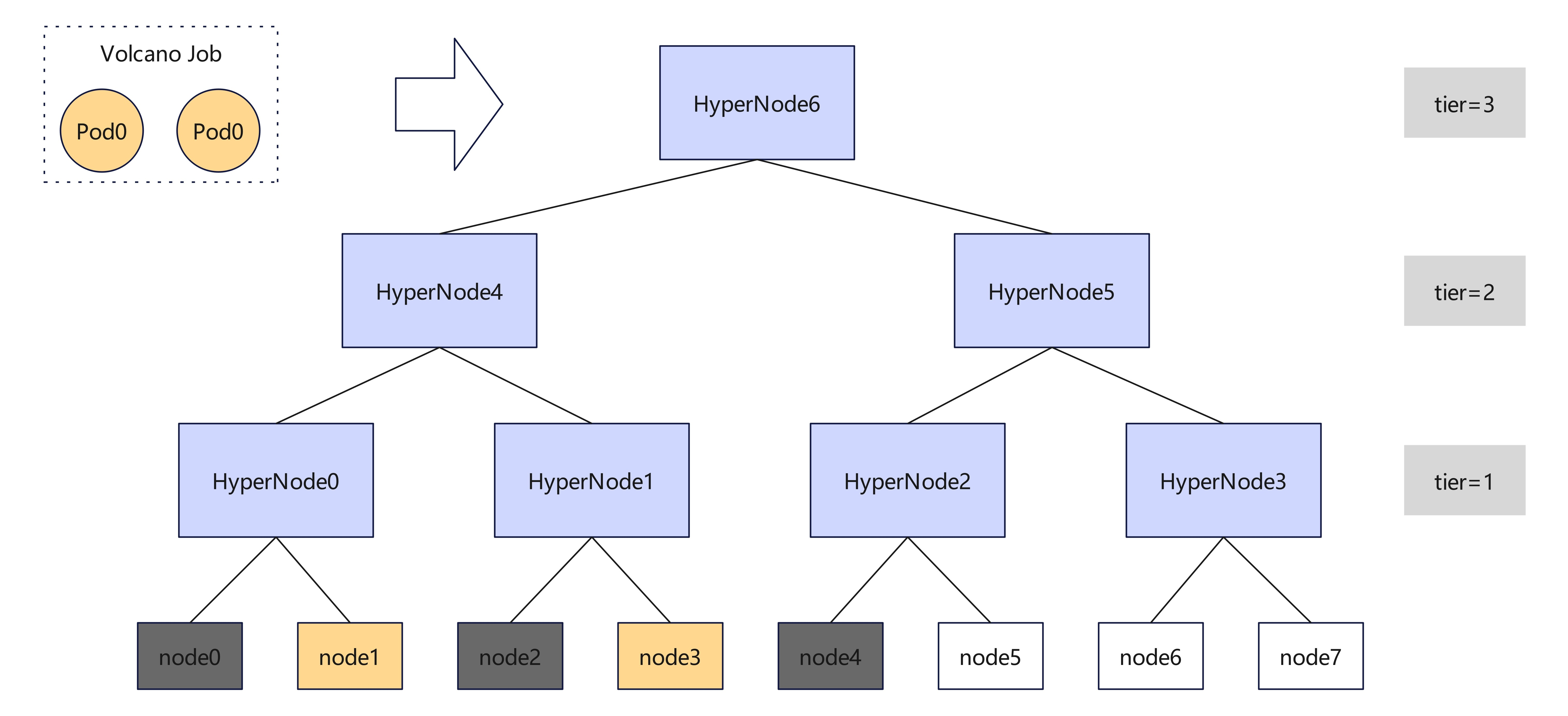
- 未启用 HyperNode 级装箱时,调度器可能将这两个 Pod 分配到 node1 与 node6,或 node3 与 node7,使 HyperNode 级资源碎片更加严重。
- 启用 HyperNode 级装箱后,调度器会优先将它们分配到 node1 与 node3,将 node5、node6、node7 一并留给其他更大的、带网络拓扑约束的工作负载。
3 用户指南
3.1 安装 Volcano
请参考安装指南安装 Volcano。
安装完成后,更新调度器配置:
kubectl edit cm -n volcano-system volcano-scheduler-configmap
kind: ConfigMap
apiVersion: v1
metadata:
name: volcano-scheduler-configmap
namespace: volcano-system
data:
volcano-scheduler.conf: |
actions: "enqueue, allocate, backfill"
tiers:
- plugins:
- name: priority
- name: gang
- name: conformance
- plugins:
- name: drf
- name: predicates
- name: proportion
- name: nodeorder
- name: binpack
- name: network-topology-aware # Add it to enable network-topology-aware plugin
arguments:
weight: 10
hypernode.binpack.cpu: 5 # HyperNode-level bin packing weight for CPU
hypernode.binpack.memory: 1 # HyperNode-Level bin packing weight for memory
hypernode.binpack.resources: nvidia.com/gpu, example.com/foo # Custom resource names to be considered by the bin packing strategy
hypernode.binpack.resources.nvidia.com/gpu: 2 # HyperNode-Level bin packing weight for "nvidia.com/gpu" resources
hypernode.binpack.resources.example.com/foo: 3 # HyperNode-Level bin packing weight for "example.com/foo" resources
hypernode.binpack.normal-pod.enable: true # Whether or not to enable HyperNode-level bin packing for normal pods
hypernode.binpack.normal-pod.fading: 0.8 # Parameter to control the weights of hypernodes of different tiers, i.e., the weights of hypernodes of tier `i` are math.Pow(fading, i-1)
3.2 构建网络拓扑
3.2.1 通过 HyperNode 自动发现构建(推荐)
3.2.2 手动构建
可通过手动创建 HyperNode CR 构建网络拓扑。更多细节请参阅 CRD hypernodes.topology.volcano.sh 的定义。
3.3 使用网络拓扑感知调度部署工作负载
基于以下网络拓扑,本章演示如何使用网络拓扑感知调度部署工作负载。
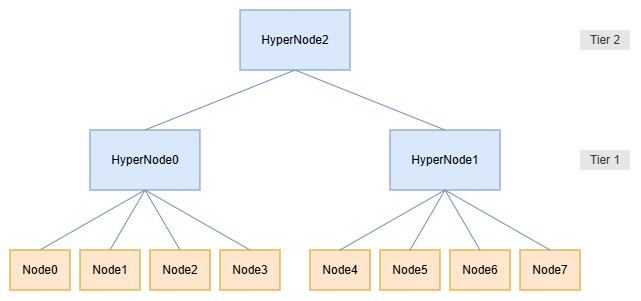
3.3.1 部署配置了网络拓扑约束的 Volcano Job
- 创建一个 Volcano Job,其中每个 Pod 请求单个节点的全部 CPU 资源。示例如下:
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: network-topology-job
namespace: default
spec:
schedulerName: volcano
minAvailable: 4
networkTopology:
mode: hard
highestTierAllowed: 1
tasks:
- name: t0
replicas: 8
template:
spec:
containers:
- name: c0
image: nginx:latest
resources:
requests:
cpu: "4"
limits:
cpu: "4" - 调度结果如下:
本例中,Job 内 Pod 不能跨第 1 层 HyperNode 调度。Job 被调度到 HyperNode1,该 HyperNode 仅有 4 个节点(Node4~Node7),因此只有 4 个 Pod 处于 Running 状态。
$ kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE
network-topology-job-t0-0 1/1 Running 0 5s 192.168.0.10 node4
network-topology-job-t0-1 1/1 Running 0 5s 192.168.0.11 node5
network-topology-job-t0-2 1/1 Running 0 5s 192.168.0.12 node6
network-topology-job-t0-3 1/1 Running 0 5s 192.168.0.13 node7
network-topology-job-t0-4 0/1 Pending 0 5s <none> <none>
network-topology-job-t0-5 0/1 Pending 0 5s <none> <none>
network-topology-job-t0-6 0/1 Pending 0 5s <none> <none>
network-topology-job-t0-7 0/1 Pending 0 5s <none> <none>
3.3.2 部署配置了网络拓扑约束与子组亲和策略的 Volcano Job
- 创建一个 Volcano Job,其中每个 Pod 请求单个节点的全部 CPU 资源;并配置子组亲和策略,将 Job 内 8 个 Pod 划分为 2 个分区。示例如下:
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: network-topology-job
namespace: default
spec:
schedulerName: volcano
minAvailable: 4
networkTopology:
mode: hard
highestTierAllowed: 2
tasks:
- name: t0
replicas: 8
partitionPolicy:
totalPartitions: 2
partitionSize: 4
networkTopology:
mode: hard
highestTierAllowed: 1
template:
spec:
containers:
- name: c0
image: nginx:latest
resources:
requests:
cpu: "4"
limits:
cpu: "4" - 调度结果如下:
本例中,整个 Job 被调度到 HyperNode2(Node0
$ kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE
network-topology-job-t0-0 1/1 Running 0 5s 192.168.0.10 node2
network-topology-job-t0-1 1/1 Running 0 5s 192.168.0.11 node3
network-topology-job-t0-2 1/1 Running 0 5s 192.168.0.12 node1
network-topology-job-t0-3 1/1 Running 0 5s 192.168.0.13 node0
network-topology-job-t0-4 1/1 Running 0 5s 192.168.0.14 node4
network-topology-job-t0-5 1/1 Running 0 5s 192.168.0.15 node5
network-topology-job-t0-6 1/1 Running 0 5s 192.168.0.16 node6
network-topology-job-t0-7 1/1 Running 0 5s 192.168.0.17 node7Node7)。第一个分区(Pod0Pod3)调度到 HyperNode0(Node0Node3),第二个分区(Pod4Pod7)调度到 HyperNode1(Node4~Node7),各分区均满足各自的网络拓扑约束。
3.3.3 部署未配置网络拓扑约束的 Volcano Job
- 创建一个包含两个独立 Pod 的 Volcano Job,其中每个 Pod 请求单个节点的全部 CPU 资源。示例如下:
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: network-topology-job
namespace: default
spec:
schedulerName: volcano
minAvailable: 2
tasks:
- name: t0
replicas: 2
template:
spec:
containers:
- name: c0
image: nginx:latest
resources:
requests:
cpu: "4"
limits:
cpu: "4" - 调度结果如下:
由于资源均处于空闲状态,第一个 Pod(network-topology-job-t0-0)可调度到任意节点;本例中为 node0。随后第二个 Pod(network-topology-job-t0-1)必须调度到 node1、node2 或 node3;本例中为 node1。这是因为当前 HyperNode0 的资源利用率高于 HyperNode1。
$ kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE
network-topology-job-t0-0 1/1 Running 0 5s 192.168.0.10 node0
network-topology-job-t0-1 1/1 Running 0 5s 192.168.0.11 node1