本文2021年6月15日首发于容器魔方微信公众号,原文链接锐天投资基于Volcano的大规模分布式离线计算平台的应用实践
业务场景与技术选型
业务场景
为策略人员提供研究以及开发的虚拟机
AI训练与推理
数据ETL
通用的分布式批处理任务
Why Use Kubernetes?
分布式批处理任务平台用于管理计算资源和存储资源。对计算资源而言,我们最终选用了Kubernetes来进行管理,主要原因有以下几点:
通过 Container 隔离用户环境:我们公司大概有4~5组不同的用户,其使用的开发环境、开发策略都是不同的,这对于整体集群环境管理而言是非常大的挑战,使用Container后,所有的环境可以封装在Container,直接通过k8进行调度,来解决环境隔离问题。
通过 Device Plugin 支持 GPU 等异构设备
ETCD 的中心式数据存储机制
活跃健全的技术生态
Go 语言符合公司技术栈
Why Use CephFS
存储部分我们使用的是CephFS,它是ceph提供的分布式文件存储的一种接口形式,ceph本身提供三种存储接口:S3、快存储以及CephFS。我们使用CephFS主要有以下几点原因:
Posix Filesystem 权限与接口:对于我们所有人而言,最熟悉最自然的文件存储及获取方式是本地文件系统,而CephFS可提供稳定文件系统挂载。并且对我们这个行业而言,所有的用户多租户的情况下,每个用户他有自己的一个uid,每个用户他自己的数据都只能自己来访问。那么Posix Filesystem的一个权限机制,可以让用户无缝的把自己的文件权限迁移到sap上。
强一致性:在 a节点写入一个文件,在b节点可直接读取。
同时支持大规模小文件存取与大带宽 IO
层级化硬件支持
Kubernetes ReadWriteMany PV
Why Volcano
Why not default-scheduler
Default-scheduler无法满足我们需求的原因有4点:缺少队列调度、缺少公平调度、缺少多租户隔离、缺少高级调度策略,如Gang-Scheduling。最重要的是公平调度和高级调度策略。所谓的公平角度,是指当有很多人提交了非常多的任务排队正在等待时,应该来运行谁的任务?当集群空出来或有资源时,到底应该运行谁的任务?要完成这一点,每个队列映射于一个团队,基于队列的公平角度,每一个namespace对应一个用户,基于用户的公平调度,这两点都是必不可少的。所以在这两点上,default-scheduler完全没有办法满足我们的需求。
因此我们求助了社区。kube-batch是社区下面的批处理调度器,它只是一个调度器,不提供除调度以外的任何解决方案,这也是我们没有使用kube-batch的最主要原因。要做一个批处理方案,不只需要调度器的功能,还需要对于环境及其他任务 CRD做一系列处理。没有及时处理的话很难作为平台来使用。
Why is Volcano
支持公平调度
支持丰富的高级调度策略,如 Gang-Scheduling、Binpack 等
支持通过 SSH plugin 方式实现 Pod 互访
支持通过 ENV plugin 方式向 Pod 注入任务依赖,天然支持 Tensorflow Worker Sharding
支持 SVC plugin 方式对外提供服务
有了这样一个调度平台,基本可以满足我们的整体需求。
系统架构
服务架构
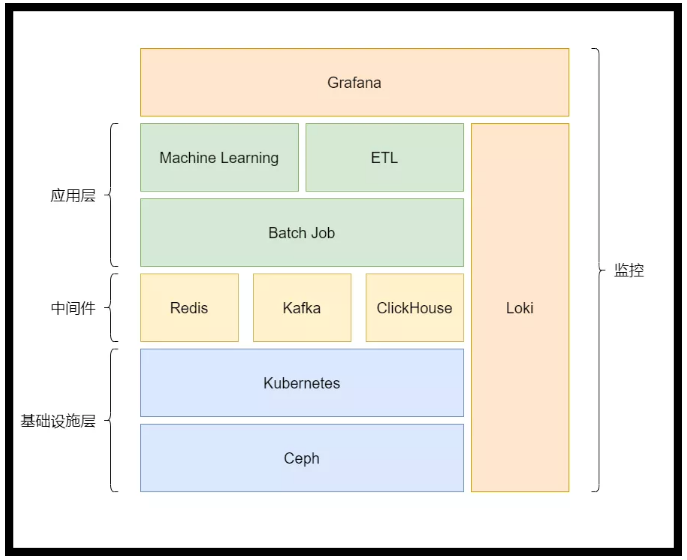
基于 Ceph 提供高性能存储
基于 Kubernetes 管理多种异构硬件
通过 Loki + Grafana 同时作为用户面板与监控面板
中间件与应用层混部,充分使用集群资源
基于 Batch Job 形式,扩展多种业务场景
多租户
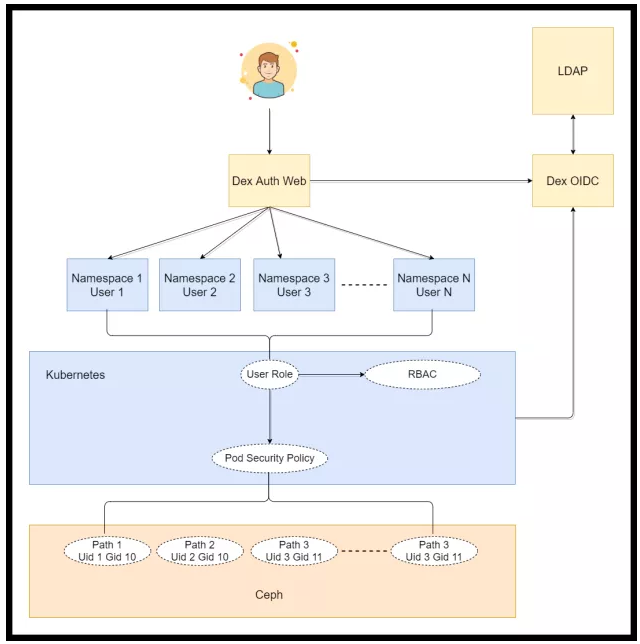
用户提交任务还会遇到多租户的问题。例如用户提交一个pod到集群,这个pod运行用户与Uid是什么?默认情况下,它的运行用户Uid是image制造者的Uid,相当于所有用户提交的pod的Uid变成同一个人,这是不行的,因为他们获取的数据和生成的数据互相之间是不能看的。
在这种情况下,我们的解决方案是通过K8s Namespace做整个用户所有资源的隔离,namespace对应于一个用户,通过已有的LDAP服务和OIDC与开发信息对接,给用户一个认证,通过RBAC进行用户资源的授权,授权用户使用以下的一个Pod Security Policy,Pod Security Policy是直接限制用户提交时,必须采用SecurityContext写上其uid与gid是什么?用户运行时整个的环境全部以此为准。
有了Pod Security Policy后,用户提交的pod必须以其uid和gid进行体现。但访问的数据都在Ceph上,也就是其gid和uid所能够访问的数据。以此来解决多租户的问题。
工作流
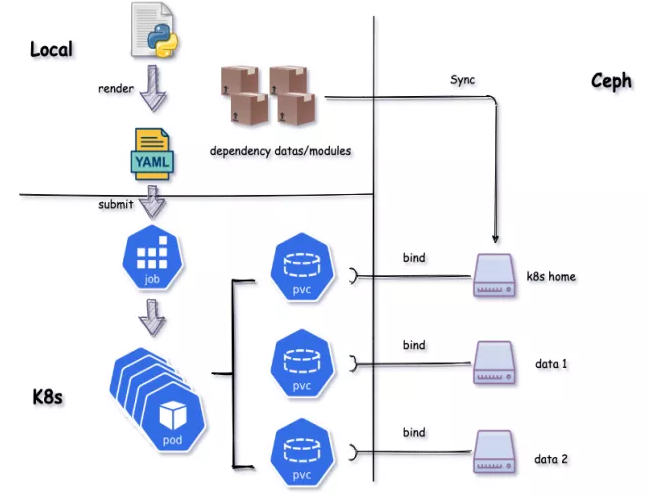
解决刚才所有的问题后,基础的工作流就出现了。本地渲染 Job Yaml 进行提交,用户所有的依赖数据同步 CephFS,并通过 PVC挂载 Pod,每个用户 Namespace 下,拥有自己目录的 PVC 权限,全部是通过IBS进行权限管控,以此来提交任务到整个集群运行。
Volcano 的深度定制
基础的提交框架平台我们选择了直接给用户提供库的形式,自研提交工具Jobctl,其开发完成后,自动支持两种使用方式,一种是命令行里面直接使用,另外一种是作为Python列表input到用户本身的notebook进行使用或直接体现到自己的Python脚本。Jobctl同时支持两种提交状态形式,一种是异步的,也就是说不停的向整个集群提交任务,任务提交完成后可直接退出;另一种是同步,job control提交完一个任务后,并且watch这个任务,当任务全部结束后,才返回给用户,这是返回给用户的工作流。
有了Jobctl后,还可以对用户隔离整个K8s复杂性,同时支持命令行提交和 Python Lib 集成,并且提供最基础的按 replicas 并行与按天并行。
OOM Auto Scale Up
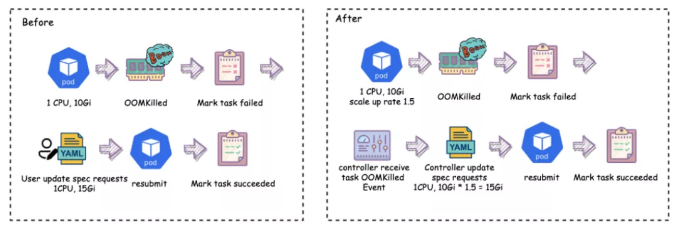
首先做的第一个定制是OOM的时候对整个任务进行资源Scale Up,因为用户不能很好预估内存,OOM 后需要重复提交验证,因此我们通过直接定制 OOMKill Auto Scale Up ,通过修改Volcano Controller自动把OOMKill的pod所申请的资源按比例进行放大,放大后自动重复提交,并且提交完成后通知用户。按照这个功能让用户的整个任务在他自己不参与的情况下自动重复提交,得到合理内存申请值,这里其实使用了上文提到的Volcano policy event机制。
MinSuccess
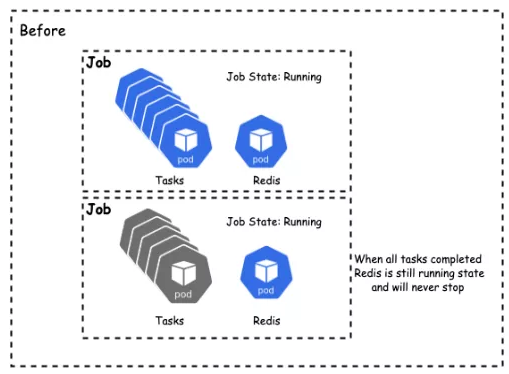
minAvailable 个 Pod 结束,则任务结束
非 Gang 的任务难以灵活调度
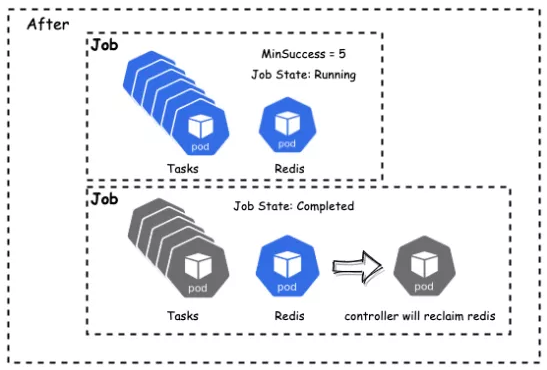
minSuccess 个 Pod 结束,则任务结束
解耦 Gang 所需 Task 数量和完成 Job 所需任务数量
NodeZone
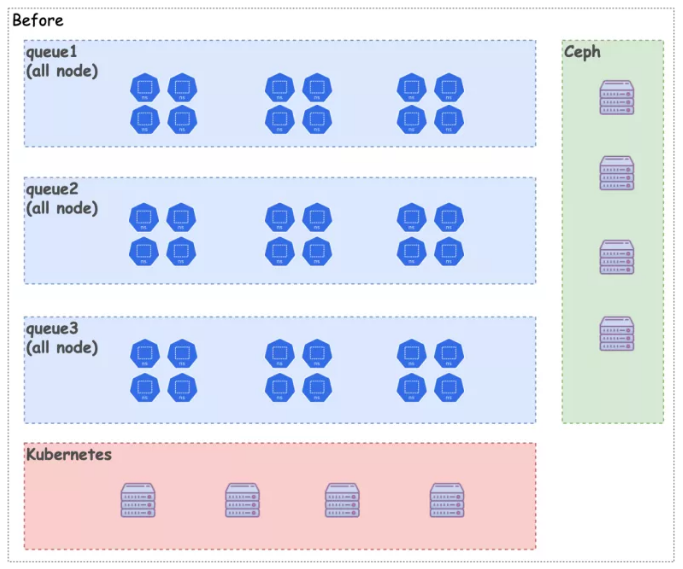
一个 Volcano 实例管理所有节点
无法解决 Noisy Neighbor
无法做紧急资源预留
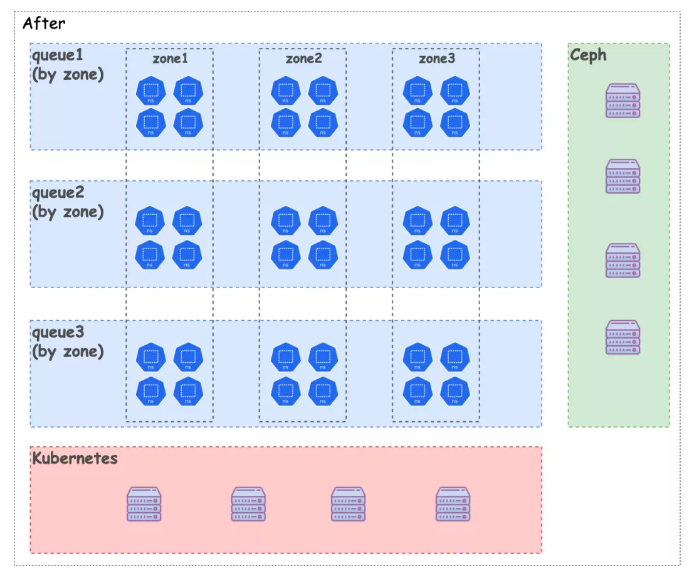
多个 Volcano 实例,分别管理多个Zone
对某些任务做物理隔离
Volcano Namespace Quota
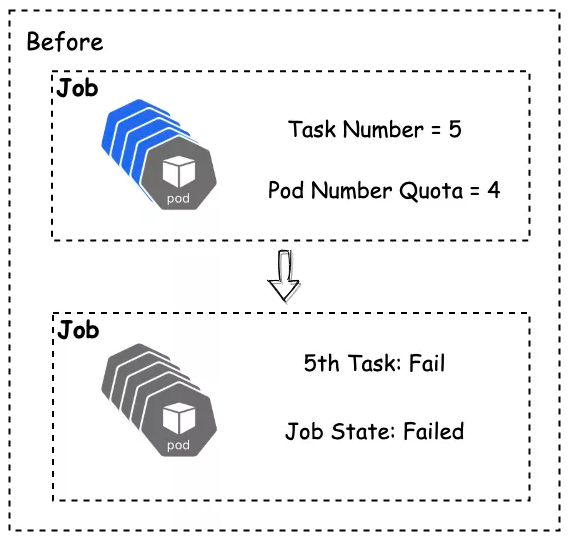
默认的k8s Quota并不能满足我们的需求,因为触发原生 Namespace Quota 时,Pod 直接 Fail,因此我们在Volcano级别做了Quota。
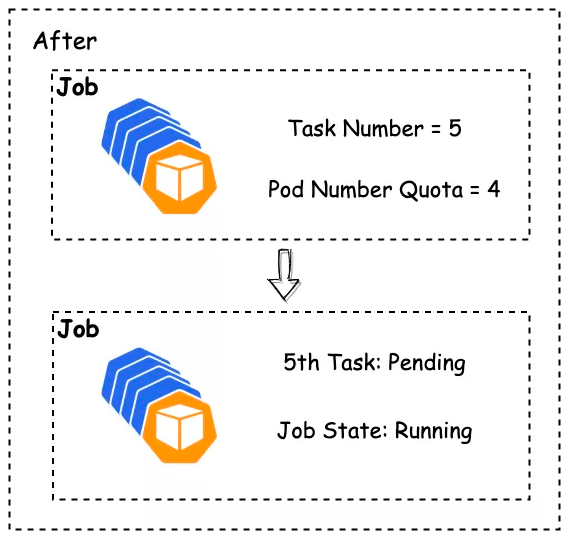
- 触发 Volcano Namespace Quota 时,Pod 排队延迟创建
Volcano 监控与报警
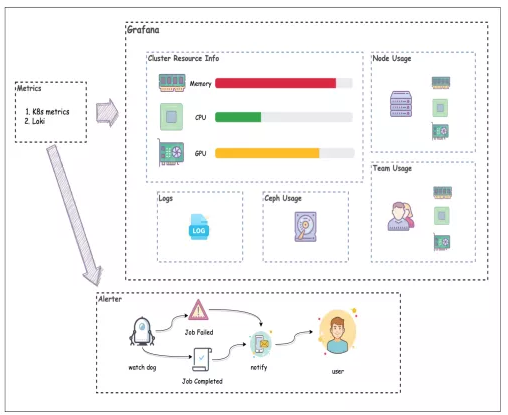
Volcano Exporter
输出 Task 的队列标签
输出队列 Capability
输出 Job 的开始完成时间
WatchDog 组件
注册 Informer,并收集 Metrics
负责任务失败与使用率报警
自动更新队列的 Capability
任务状态面板
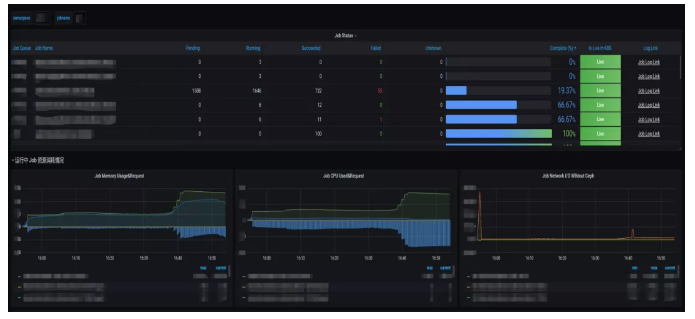
上层来承载所有job的信息,并且会有一个状态表来表示任务完成情况,以此来大致判断任务的形式。下面的三点是CPU、memory和networks的资源使用情况。除了正坐标轴外,副坐标轴的一些竖线是指它浪费的集群资源。这些浪费的集群资源帮助用户实时判断任务运行状态的节点发生的浪费情况。所以我们需要通过这样的时间序列状态表,来提醒用户。
集群资源面板
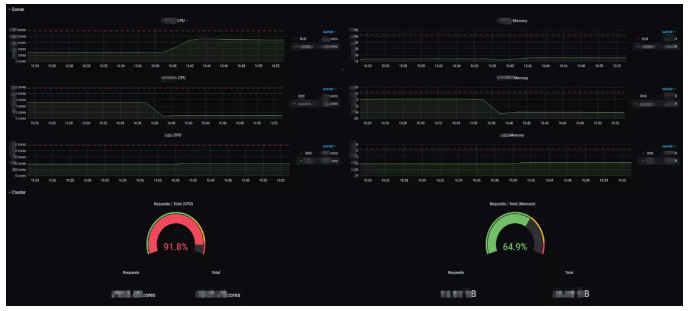
通过graph的话,对整体队列资源、 CPU、memory以及所有队列资源的使用,用户需要看到所有节点的资源使用情况,因为有些非常大的消耗任务,比如一个任务有可能需要申请300或500的内存,但并不是所有的信息都支持单个节点内存使用的,所以只有总体的内存使用率是不够的,还需要有每个节点内存使用率。
高并发场景下的挑战与解决方案
随着场景变多和平台用户的增加,我们发现了一些问题,集群规模单集群计算节点数量200 、存储总量1.5PB,读写带宽15GB/s、同时承载长时间任务(1week)与短时间任务(1min)、Pod 每日增长量10W ~ 30W,这是一个非常恐怖的规模。
问题1:单个Job对象过大

问题:
在有大量 Pod 时超过 ETCD Max Request Size (1.5MB)
直接调整 Max Request Size,大量的 Object对 ETCD 造成冲击
解决:
通过单个 Task 多 Replica 的形式提交任务
Pod 内部通过 ENV plugin 插件提供的信息,以 Sharding 的形式读取参数
问题二:Out Of Cpu/Memory
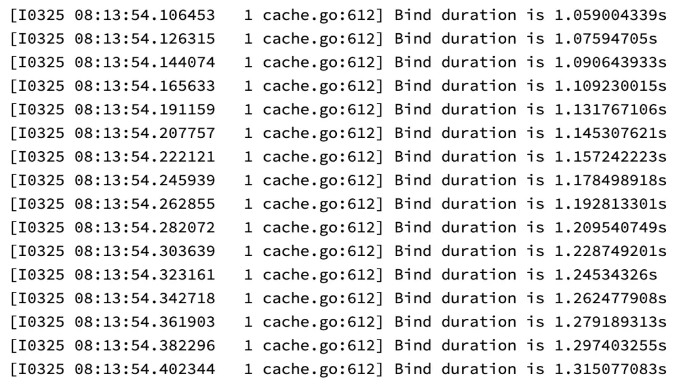
问题:
节点数少 + 大量短时任务不停调度
Kubelet PLEG 压力大,Pod Binding 时间过长
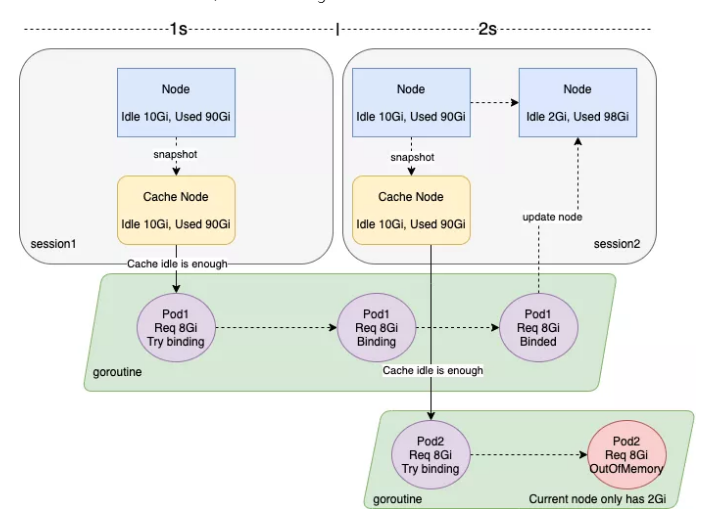
问题:
节点数少 + 大量短时任务不停调度
Kubelet PLEG 压力大,Pod Binding 时间过长
Volcano 默认 session 间隔时间为 1s,造成 Cache Snapshot不一致
Out of CPU + Out of Memory
解决:
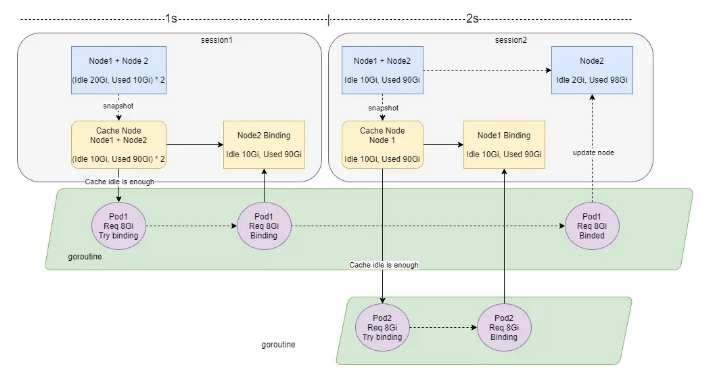
增加 Node Binding Task Number
在 Session 开始创建 Snapshot 时,跳过 Binding Task Number > 0 的 Node
上文提到各种各样的深度定制,包括bug fix和修改,我们都已提交给了社区,并且我们有一位成员已经成为 Volcano 社区 Approver。非常荣幸能够参与社区共同的改进,也希望更多的开发者能够加入Volcano社区。