How Does Volcano Empower a Content Recommendation Engine in Xiaohongshu
This article was firstly released at
Container Cubeon May 27th, 2021, refer to 小红书基于Volcano的大规模离线与在线推荐模型训练实践
Introduction to Xiaohongshu
Xiaohongshu is a leading life-sharing community in China. Popular among female users and joined by more and more trendy boys, now Xiaohongshu has more than 100 million monthly active users. This UGC community has hundreds of thousands of notes submitted every day and nearly 10 billion views/hits per day.
The recommendation on the homepage is in the charge of our recommendation team and is one of the core service scenarios of Xiaohongshu. In the first years when Xiaohongshu was established, all of the recommended notes were manually selected without assistance of any machine learning models. As a result, we recommended the same content to almost every user.
Since 2016, we started to explore personalized recommendation for different users. In 2018, the first recommendation machine learning model based on SparkML and GBDT was introduced. It had only tens of thousands of parameters. Since the end of 2018, we accelerated the model iteration. By the second half of 2020, our model scale reached hundreds of billions of parameters. We also introduced online learning, and the model could be updated in hours. From April this year, the model is updated every few minutes, which means the model can capture users' behavior within one or two minutes to get users' short-term interests and generate recommendations that are more appealing for users.
Big Data Architecture in Xiaohongshu Search, Recommendation, and Ad Scenarios
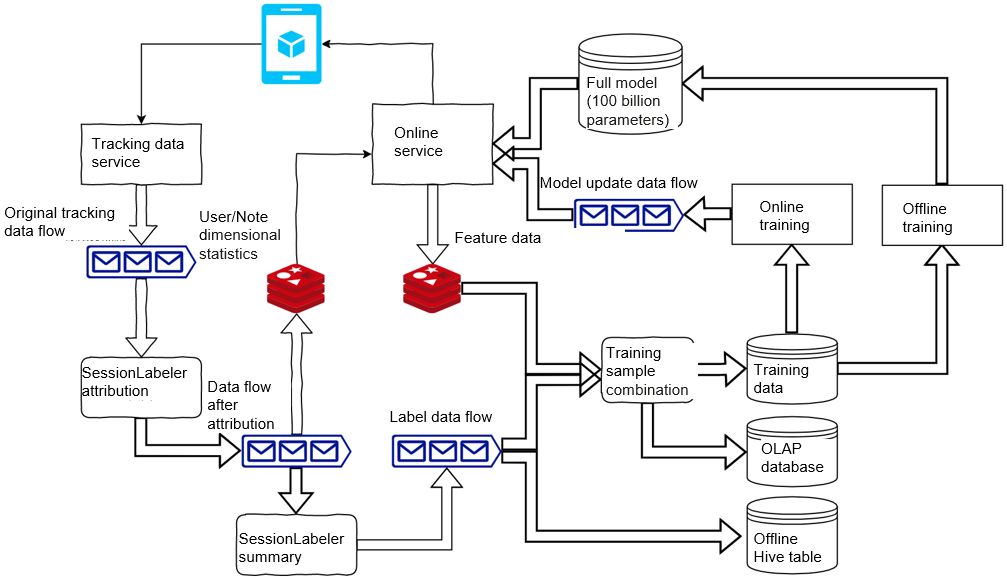
The architecture consists of four parts. The upper left corner shows the interaction between the client and the real-time service/tracking data service. After being started, the Xiaohongshu app requests an online service for recommendation. The online service caches the recommended notes and requested features, and returns the recommendation results to the client. When the user browses the notes recommended to him/her, a series of interaction behaviors are generated. The interaction behaviors become data flows that pass through the tracking data service and go to the original tracking data flow.
In the lower left corner, there are attribution and summary tasks used to clean and process user behavior data in real time to generate the label data flow. The label data flow and feature data flow are combined to generate the training samples, and the three major products of Xiaohongshu big data: training data, OLAP database, and offline Hive table.
The upper right corner shows online and offline training. Online training trains the data in real time to generate the updated data of the model. Offline training generates a full model and uploads it to the online service.
Behavior Attributions and Labels
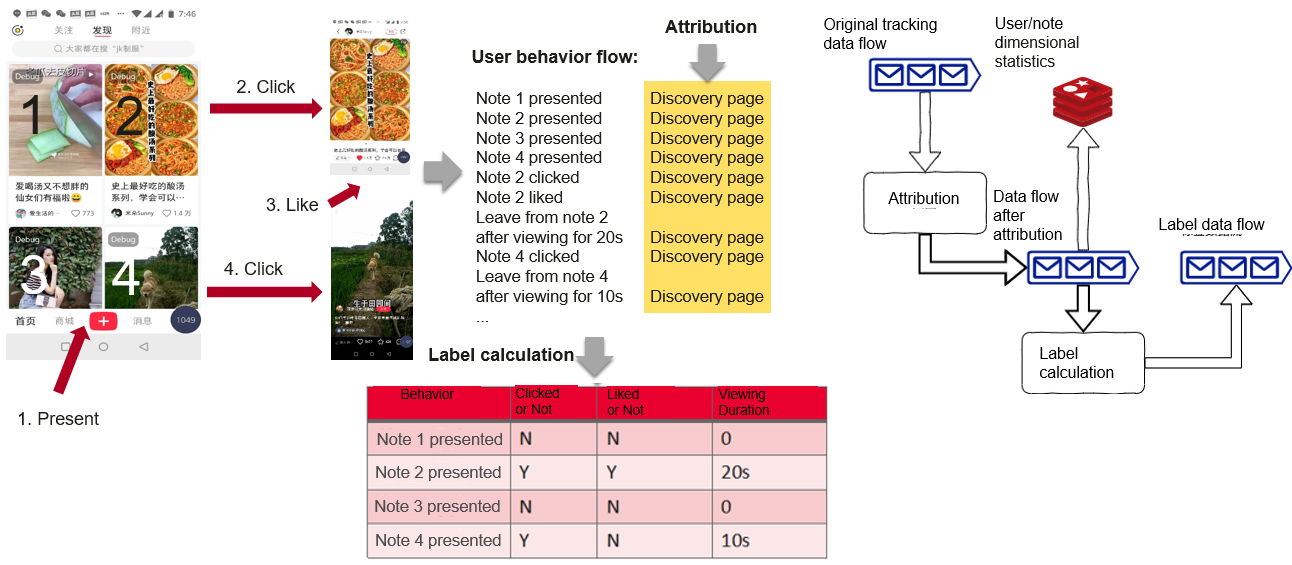
This task for user behaviors can be divided into two parts: attribution and label. Attribution is to associate each behavior captured in data tracking with the past behaviors of the user. For example, you browse 4 notes in the app, one found on the Discovery page, one on the search results page, and two on a blogger's homepage. You click Like for the final piece. Your browsing and clicking Like are tracked. The tracking data does not tell us what happened before the like is given.
We can determine the cause of the like behavior based on the user behavior flow and user's historical browsing records prior to the like. This process is called attribution. Through the attribution task, we can also add labels about why a user follows a blogger, and which of the blogger's notes the user has viewed before following the blogger.
Opposite to attribution, label calculation summarizes the actions performed by a user after a certain behavior. If the user browsed four notes on the Discovery page, for each note Xiaohongshu makes several labels about whether the user liked the notes after browsing, or whether the user tapped to enter the note details page and how long the user stayed on this page. This label data is important for subsequent model training and the generation of daily user reports.
Real-Time Big Data Products for Search, Recommendation, and Ad

After the label data is generated, the above three big data products are provided for the service.
The model training data is used to train models in real time, and provide more accurate and real-time information about users' latest interests.
Both the ad hoc data analysis and offline warehouse perform analysis based on the label data. The ad hoc data analysis is real-time. For example, if there is any change in the system and policy, effects should be observed immediately from a multi-dimensional segmentation perspective. In contrast, the offline data warehouse provides daily or weekly reports, or shows the changes have been made to certain metrics in the past six months.
Online and Offline Model Training
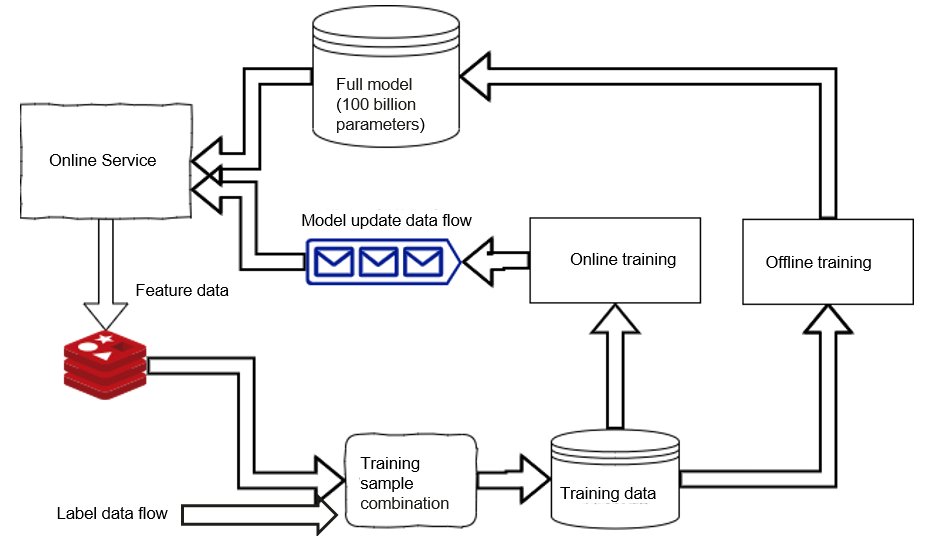
Training data generated after the combination of label data and feature data is used for both offline and online training.
Though the same data source is used, there are differences between online and offline training. For online training, the data source is provided to Kafka for online consumption. After that, a model update data flow is output, which actually means that the last batch of model changes is released online in real time. Offline training is performed on a batch and daily basis. A full migration parameter model is released, and data is migrated back to the online service.
Evolution from Offline Batch Computing to Online Stream Computing
Offline Batch Only
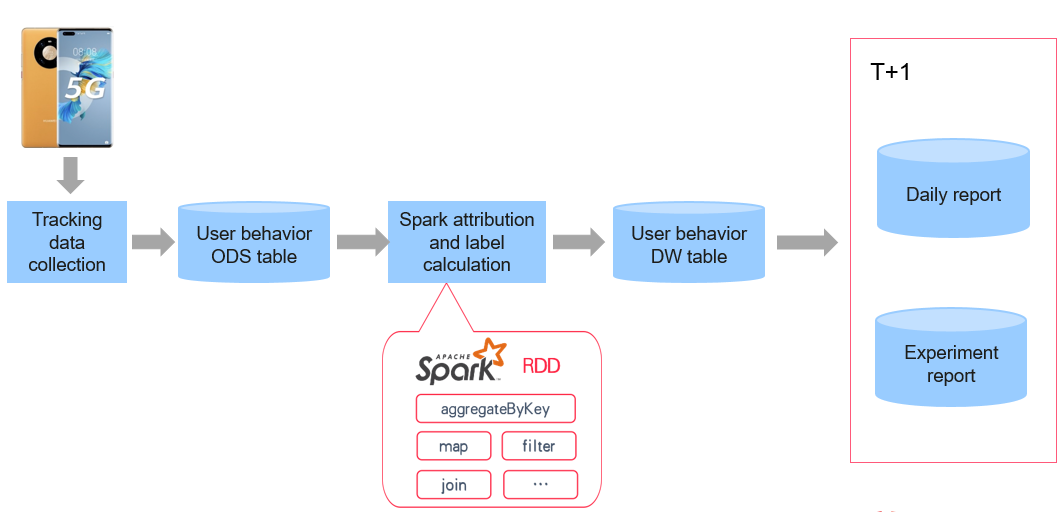
The preceding figure shows the earliest offline batch label calculation process. Click behaviors of users are collected and recorded in the ODS table, that is, the original log table. The attribution and label calculation are performed by the Spark task, which is an offline batch task. The processed data forms a data warehouse table to generate daily reports and experiment reports as big data products. In the batch environment, the report is generated on a T+1 cycle. Generally, we cannot obtain the complete reports until the second or third day after each experiment.
Offline Batch + Online Streaming
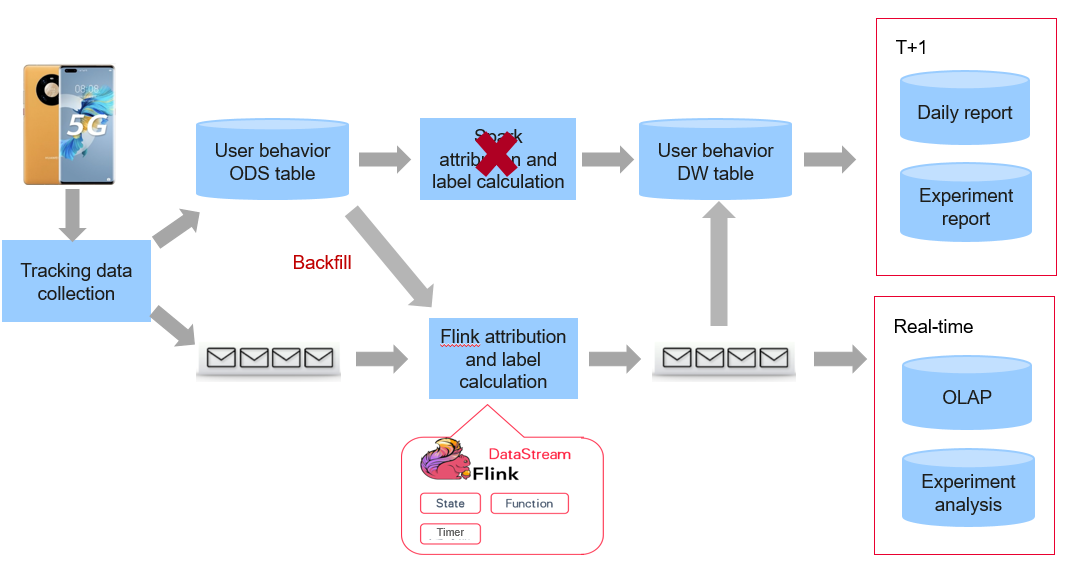
Increase in the number of developers poses higher requirements on service implementation. Therefore, we introduced the real-time link, which is completely based on the Flink framework. The real-time link inputs data through streaming Kafka, outputs the data to Kafka, and sends the data to the OLAP database and real-time experiment analysis. However, the challenge is that Spark and Flink are two different programming frameworks. For example, the logic for determining whether a click on an ad is valid is complex, because an interaction behavior or a stay of at least three seconds after the click is required before the click can be called a valid click.
If there are two data flows, the logic is implemented both in the offline service and the Flink framework. Many problems may occur when the same logic is implemented twice. One problem is that development needs to be repeated in both the Spark and Flink frameworks. A bigger problem is that the logic may be changed after being developed in both of the frameworks.
For some complex scenarios, the change may cause inconsistency between reports and requests. In some other scenarios, when the data warehouse makes a request offline, and the logic is implemented only in the Spark task, but not implemented offline, if we want to view the task, we need to implement the logic again, which will cause extra workload.
After the upgrade we made, all new labels are calculated in real time, not in Spark. However, interruption may occur in the real time mode. After the interruption, calculation may start from the latest data, and the earlier data may have changed. This problem is simple to solve in the offline mode, as we can re-run data of each hour to form the complete data.
We actually need to solve a technical problem: How to convert the real-time Flink training task from an offline data warehouse table to a real-time flow table, use the same computing logic to generate new data and then backfill the new data to the real-time flow table? In this way, the core logic of the real time and offline modes only needs to be implemented in real time, which solves the problem of inconsistent logics between the two developments.
Offline Training
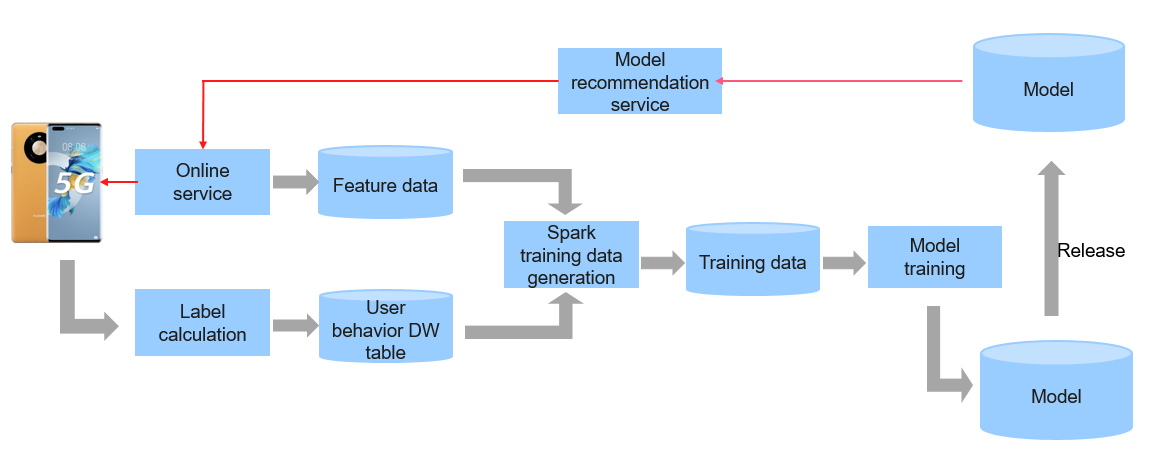
The preceding figure shows the training process of the machine learning model. At the earliest, there was only one batch data calculation task. Feature data and user behavior data are stored in offline tables. The Spark task is used to combine the data to generate a training task, and then release the learning model. The entire process may be performed once a day.
Online + Offline Training
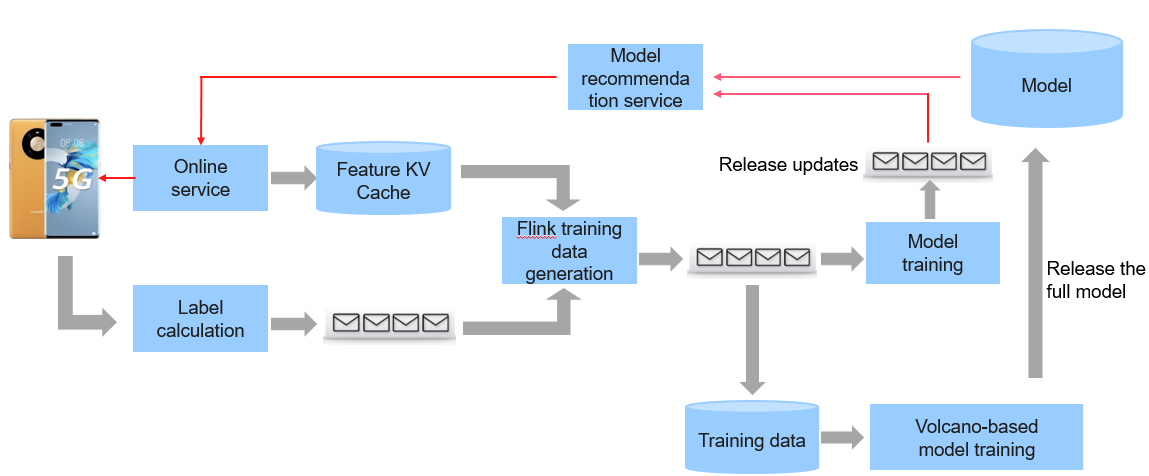
To capture users' real-time interests and make judgment on newly released notes more quickly, more real-time update is required for our models. Therefore, Flink is used for real-time model training. After Flink generates data, the Volcano scheduling system is used to update models in real time and in batches.
Optimization and Multi-cloud Management of Offline Training
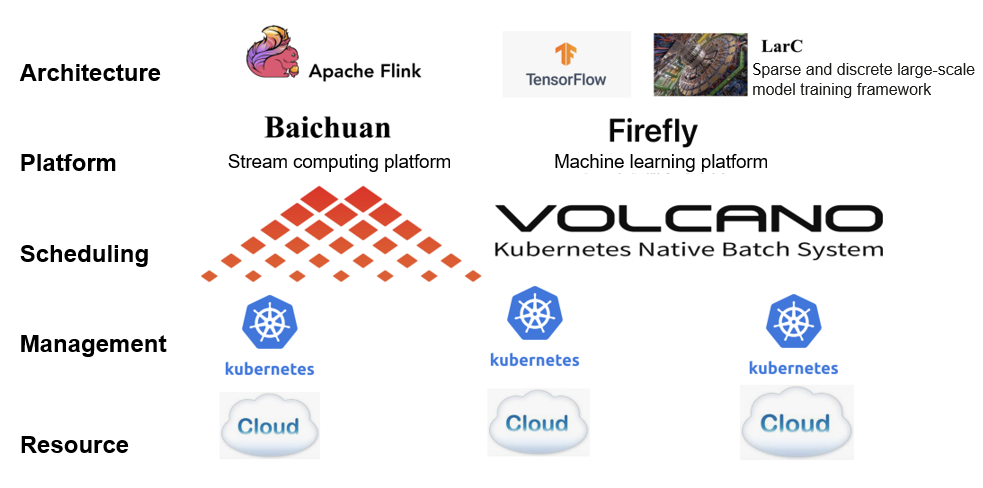
The preceding figure shows the technology stack of Xiaohongshu in machine learning and big data. Xiaohongshu is a relatively new company without on-premises equipment rooms. All of our services are deployed on clouds provided by cloud vendors, and most of the services are managed through Kubernetes.
We have two important platforms. One is the stream computing platform called Baichuan, which is used to manage the Flink tasks of real-time label computing and online learning mentioned above. The other is the task management platform for machine learning, which is called Firefly. Our model training is based on TensorFlow and runs on the machine learning platform. For sparse and discrete large-scale model training of recommendation, search and advertisement, we also developed a TensorFlow-based training framework, LarC. The framework models of TensorFlow and LarC run on the machine learning platform through Firefly.
The key point between these two platforms is how to schedule tasks to the Kubernetes clusters. In fact, the native Kubernetes has a big problem in this scenario, because it performs scheduling based on individual pods.
However, the stream computing and machine learning tasks are not single-pod tasks. They are tasks performed on a group of pods. Therefore, we have encountered a big challenge at the beginning. Assume that there are two jobs, each job contains 10 pods, and each pod requires one core of CPU. That is, 20 cores are required for the two jobs to run simultaneously. If the current cluster has only 15 available cores and we are using the native Kubernetes scheduler, the scheduler may schedule 7 cores to one job and 8 cores to another, so that both jobs can obtain some resources to run. However, neither of them can be completed properly because the numbers of cores allocated to them do not meet the requirements. As a result, deadlocks occur. This is caused by the limits of the native Kubernetes scheduling.
To solve this, we need to first schedule 10 cores to one job to ensure that it can be properly completed and exited. After that, the 10 cores are released and allocated to another job so that both jobs can be properly completed.
Based on these, we researched products and found Volcano. Its predecessor is Kubernetes batch and can completely meet our requirements. Therefore, we participate in the Kubernetes batch community and become a loyal user of Volcano.
Enhanced Volcano Scheduling: binpack -> task-topology
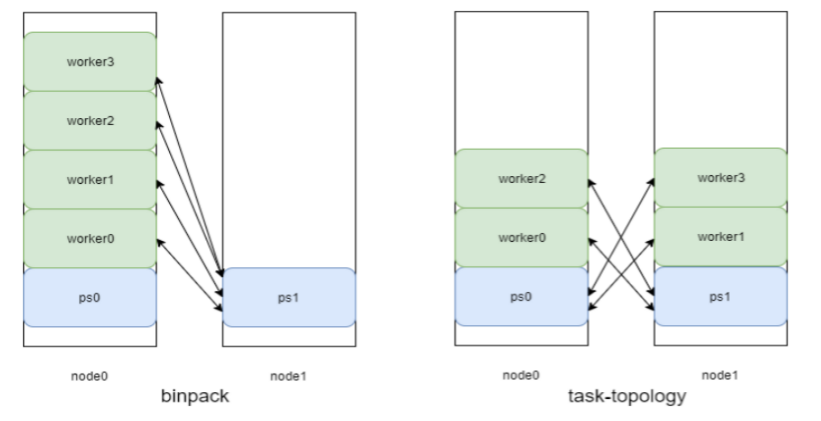
The scheduling algorithm supported by the native Volcano is binpack. Machine learning training tasks are classified into two types: worker for performing forward and reverse computing, which is a computing task; ps with the main task of storing parameters, which is a memory-type service. If the native open-source Volcano is used, its default scheduling algorithm optimizes the resources to reduce fragments. Therefore, it will schedule as many tasks as possible to the same node, and then schedule all worker and ps tasks of those tasks to the same node. When that node does not have capacity for one of the ps tasks (taking ps1 as an example here), it can only be put on another node.
In this scenario, workers and ps0 are on the same node. The I/O between them does not cross nodes, leading to fast I/O and large storage capacity. But the running speed is slow because ps1 is on another node.
With task-topology algorithm, tasks are scheduled to nodes in a balanced manner, the speed is balanced, and the overall storage capacity is greatly improved. The optimization from binpack to task-topology can increase the throughput of task training by 10% to 20%.
Data Transfer Between Multiple Clouds
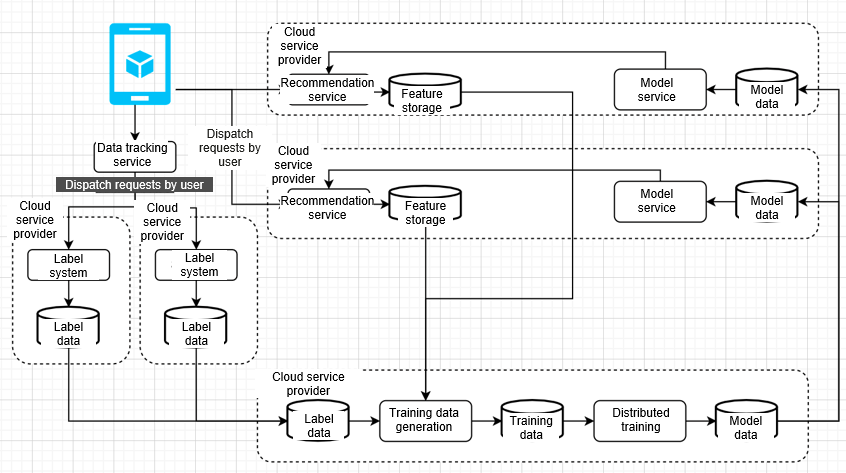
In the online mode, users are distributed to different AZs. The feature cache of the recommendation service is stored in the local AZ. After user data tracking, users are distributed to different clusters based on their requests, and the label system performs computing for each user. Finally, all label system computing is transferred to the cloud vendors that provide offline training and services for us to combine and generate data training, and perform distributed model training. The trained models are distributed to different AZs for online services.
How to implement transfer learning under this architecture Xiaohongshu users consume traffic on the homepage, which is a scenario where a large amount of data is generated and accumulated, and a model involving hundreds of billions of parameters will be trained. How do we use this large model built on recommendations for the search and advertisement scenarios? After the recommendation model is trained, it is synchronized to the search training cluster. The search training uses the search data to discover the recommendation model, and release the final search model online. In this way, the small-scale data training can obtain features of the large recommendation model training, so that the large recommendation model can be utilized by the search scenario.