OpenI-Octopus: How to Avoid Resource Preemption in Kubernetes Clusters
This article was firstly released at
Container Cubeon September 30th, 2020, refer to鹏城实验室启智章鱼教你彻底摆脱Kubernetes集群资源抢占难题
Introduction to OpenI-Octopus
OpenI-Octopus is a cluster management and resource scheduling system developed and maintained by Peng Cheng Laboratory, Peking University, and University of Science and Technology of China.
-
This system is completely open-source, complying with the Open-Intelligence license.
-
It deploys, manages, and schedules jobs using Kubernetes.
-
AI jobs can be run in clusters. Hardware such as GPUs, NPUs, FPGAs, Huawei Ascend chips, and Cambricon MLUs are supported.
-
It provides high-performance networks for AI and supports InfiniBand networks.
-
Monitoring and analysis tools for networks, platforms, and AI jobs are available.
-
Mainstream deep learning frameworks are supported.
-
A microservice-based architecture is used.
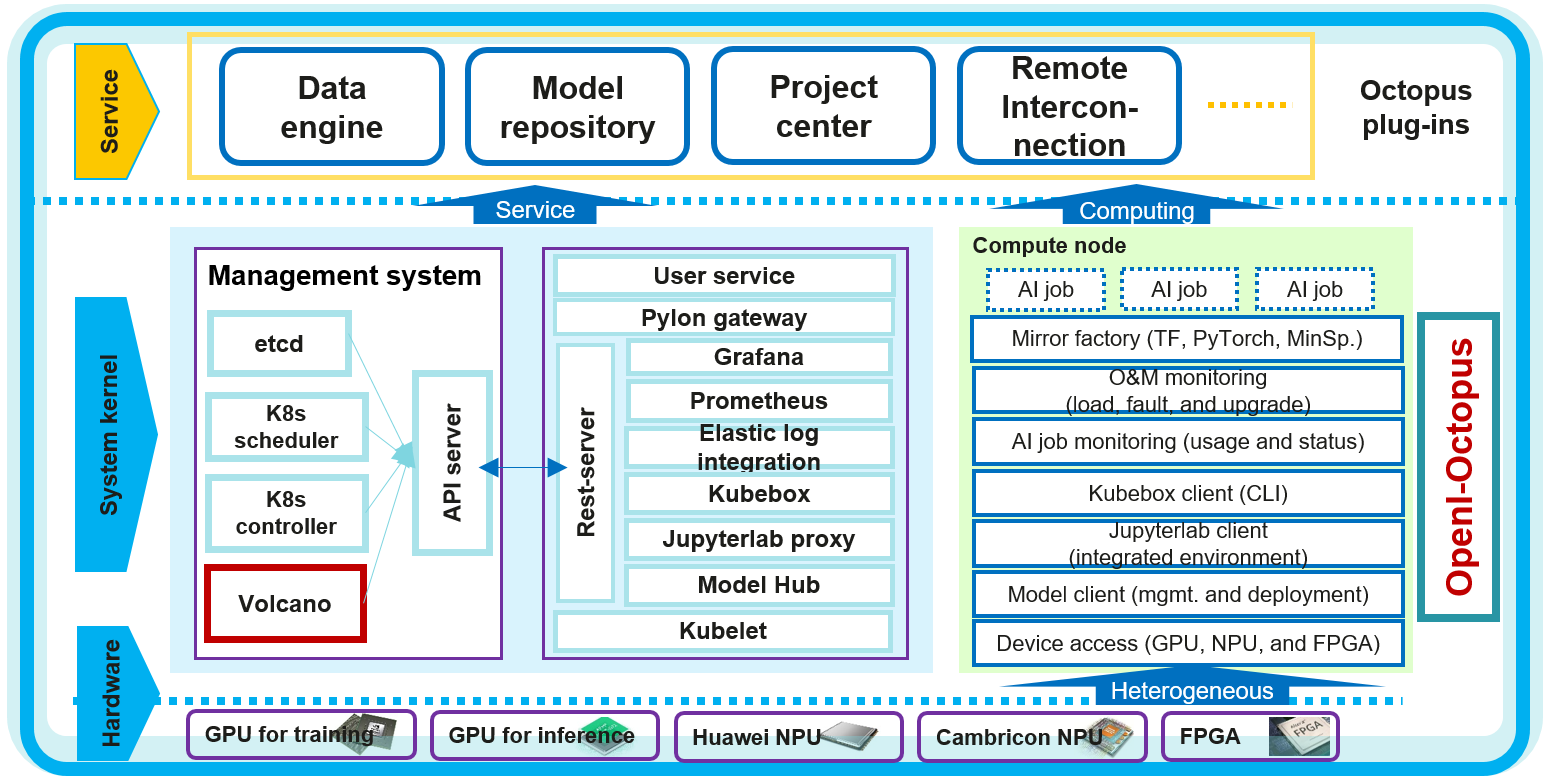
The service architecture of OpenI-Octopus is illustrated above. The bottom layer is hardware. OpenI-Octopus supports various types of heterogeneous hardware, including CPUs, GPUs, NPUs, and FPGAs. Different hardware types are adapted so that the upper-layer Kubernetes services can identify and manage them.
The second layer is the platform layer. The blue panels on the left cover the node management functions. OpenI-Octopus employs native Kubernetes functions, including orchestration planning and controllers, and enhances scheduling by integrating Volcano.
Management components communicate with integrated development services through the API server.
The rest-server module developed by OpenI-Octopus carries the core functions of the system and integrates monitoring tools such as Grafana and Prometheus, Elasticsearch, Jupyterlab proxy, and model repository.
The panel on the right covers the capabilities of compute nodes, including image factory, O&M, job monitoring, kubebox client, and Jupyterlab client for users to log in to containers.
The top layer is the services provided by the system, such as data engine, model repository, and project center. With remote interconnection, remote users can also enjoy cluster services.
Business Scenarios and Challenges
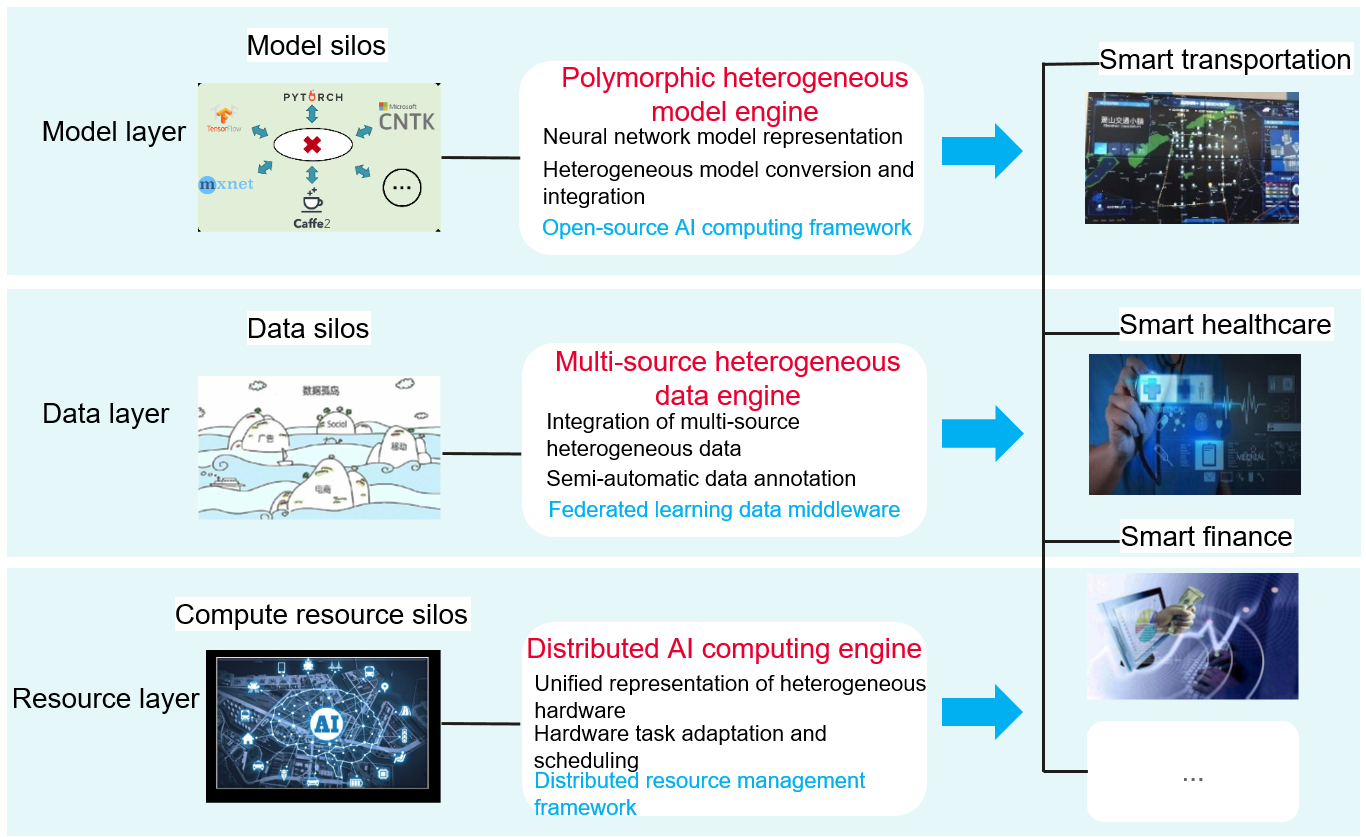
OpenI-Octopus is built for research teams and laboratories. They develop and train models in fields such as transportation, healthcare, and finance, model training, and perform model inference. These models are used for vehicle tracking, medical image recognition, auxiliary diagnosis, financial quantization, and many other applications. Some deep learning algorithms are used in these courses, which require strong compute resources.
OpenI-Octopus aims to break the model, data, and compute resource silos on the traditional platforms, and provide computing power through a single platform.
-
At the model layer, OpenI-Octopus provides a multi-architecture, heterogeneous model engine, which supports common open-source computing frameworks and provides model conversion for them.
-
At the data layer, OpenI-Octopus provides a multi-source, heterogeneous data engine, which supports heterogeneous data convergence and semi-automatic data labeling.
-
At the resource layer, OpenI-Octopus provides a distributed AI computing engine for job scheduling and the unified representation of heterogeneous hardware.
Service Requirements:
-
Excellent performance in scientific research and applications of AI, including algorithm training and inference in fields such as smart transportation, healthcare, and finance
-
High-end heterogeneous hardware resources, clusters with 150P+ computing, and 10 PB-level high-speed storage
-
Rapid and flexible deployment. The system runs reliably and stably for external teams to use.
Challenges:
-
No high-performance computing platform to meet service requirements in complex scenarios
-
Heterogeneous hardware resources need to be efficiently used and flexible scheduling policies must be supported. Resource preemption problems need to be resolved to avoid starvation of key task resources.
-
The system architecture must be scalable and services must be highly available.
Why Volcano?
At the beginning, OpenI-Octopus looked into several existing open source projects in the community. These projects can basically satisfy the service requirements and reduce the development workload. The OpenI-Octopus team narrowed down their choices to four resource schedulers. The first one was the default Kubernetes scheduler, which is not friendly to batch scheduling. The second choice was Yarn scheduler, which is based on Hadoop. However, the current architecture has been transformed to Kubernetes-based. Yarn does not fit. The last two were kube-batch and Volcano. Volcano is developed from kube-batch, and better supports deep learning and common computing frameworks. Volcano implements scheduling policies through plugins that can be easily customized to develop scenario-specific scheduling policies. That's why OpenI-Octopus chose to integrate Volcano.
Volcano brings the following benefits:
-
Complete architecture and ecosystem; timely feedback from the fast growing community
-
Customizable plugins for scenario-specific scheduling policies. Take the binpack plug-in as an example. Its packing algorithm can reduce resource fragments, allowing your cluster resources to be fully used.
-
Job queue mechanism. Job queues allow clusters to be logically grouped. Users can configure compute resource quotas for different projects, and allocate different types of jobs to different queues for management. In this way, job and compute resource management can be finer-grained.
Secondary Development Based on Volcano - Resource Status Statistics and Management
OpenI-Octopus performed secondary development on Volcano and added some new capabilities.
The first capability is to collect statistics on resources and manage resource status. These resources include both cluster compute resources and resources such as jobs, tasks, and pods generated by Kubernetes after a user submits a job.
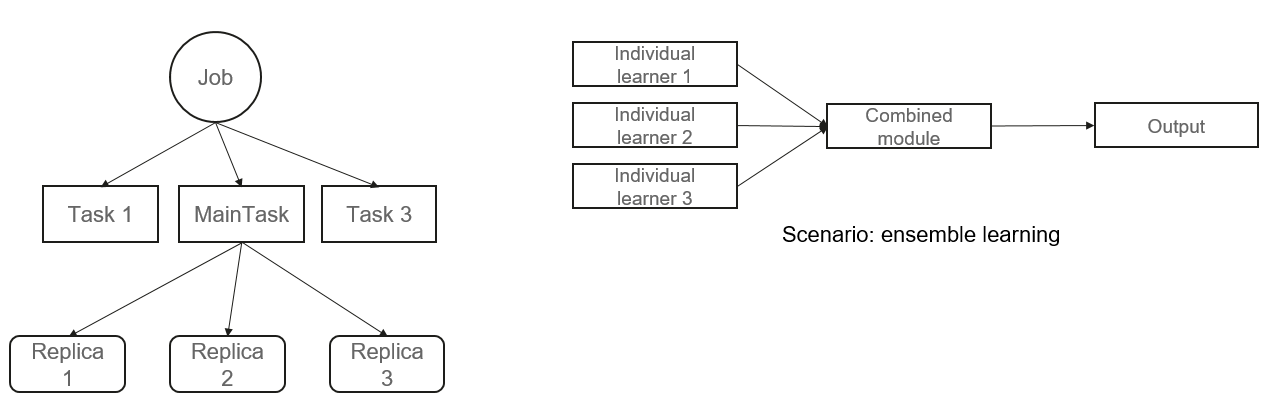
OpenI-Octopus manages to do so. It also allows users to customize the conditions and callback events of resource status transition and subscribe to the customized events and corresponding policies at the service logic layer.
Assume that there is a training job that uses an ensemble learning algorithm. Generally, a distributed training manner is used. It has a combination module and several individual learners, all of which can be regarded as tasks. Each individual learner is trained using one type of algorithm, and the combination module combines the results of each individual learner to output the final result. Once the final result is obtained, the entire training job is complete. In this job-task implementation based on Kubernetes, user can create one or more pods for a task. If you want the entire job to exit as long as the combination module runs to completion, instead of waiting until all tasks are successfully executed, You can customize a job exit policy in the scheduler and use the policy at the service layer. Different scenarios may require different policies, and that's why secondary development is needed.
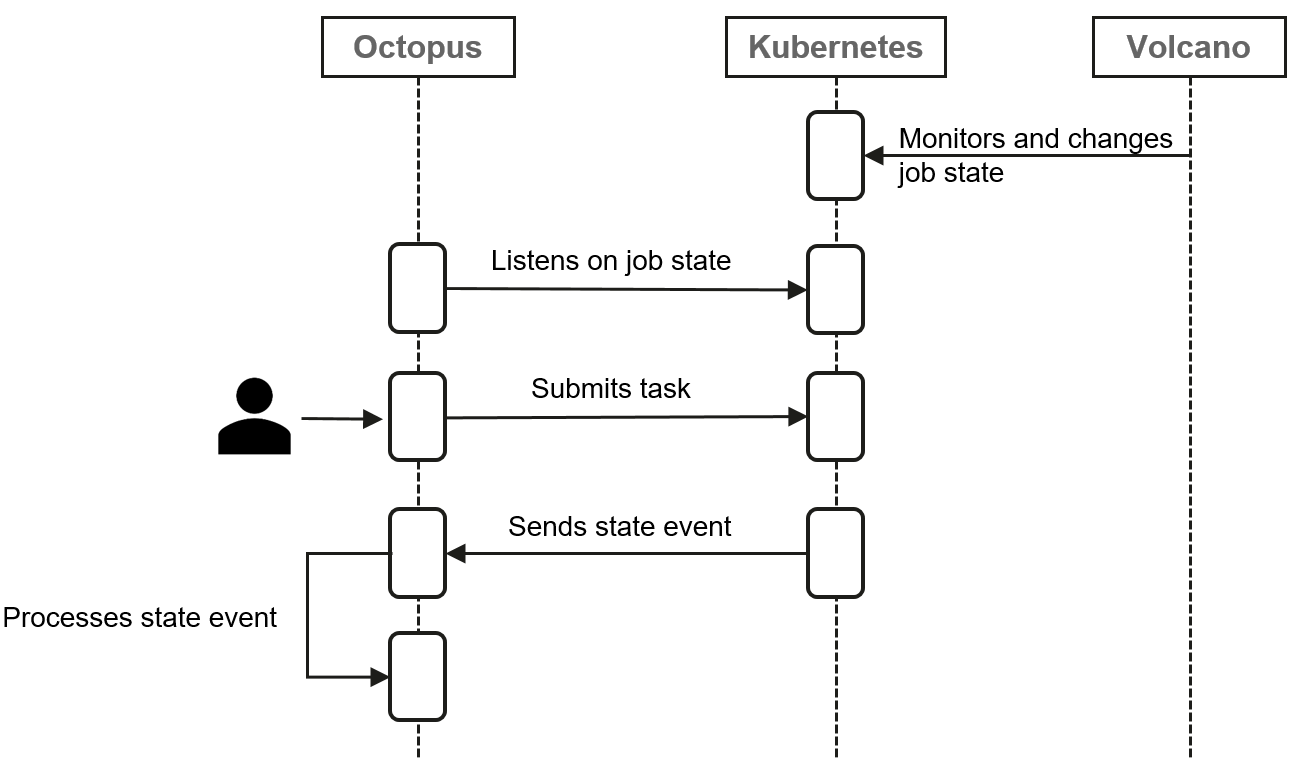
This flowchart shows job state information is transferred among OpenI-Octopus, Kubernetes, and Volcano.
First, both Volcano and OpenI-Octopus listen on all Kubernetes jobs. After the user submits a job to Kubernetes, Volcano updates the job state based on the monitored state of the pod started by the job.OpenI-Octopus will handle the job state changes.The key is how Volcano updates the job states to Kubernetes.
OpenI-Octopus worked out its solution:
1)Develop state machines for Jobs, Tasks, and Replicas.
-
More detailed resource state statistics and command output
-
Finer-grained job lifecycle management
2)Customize events and policies. Back to the ensemble learning example. The entire job can run to completion upon the customized event (e.g. MainTaskEvent) released by the scheduler that the specific task is successfully executed.
3)Implement lifecycle callback hooks, which can be added to any state transition event in any state machine. For example, the billing function collects statistics on the running duration of a job based on the start event and end event of the job.
Volcano-based Secondary Development - Privilege Action
Issues:
-
Resources are starved, and a large number of jobs in the queue keep waiting.
-
Urgent and key jobs need to be preferentially scheduled.
-
Users' jobs may be developed online and cannot be terminated unless allowed.
Existing Capabilities of Volcano:
-
Jobs with different priorities in the same queue can be preempted.
-
Pod-based eviction
-
Immediate preemption
Requirements:
-
When jobs in the same queue are from different tenants, different tenants should have different priorities and preemption permissions.
-
Job-based eviction
-
Delayed preemption
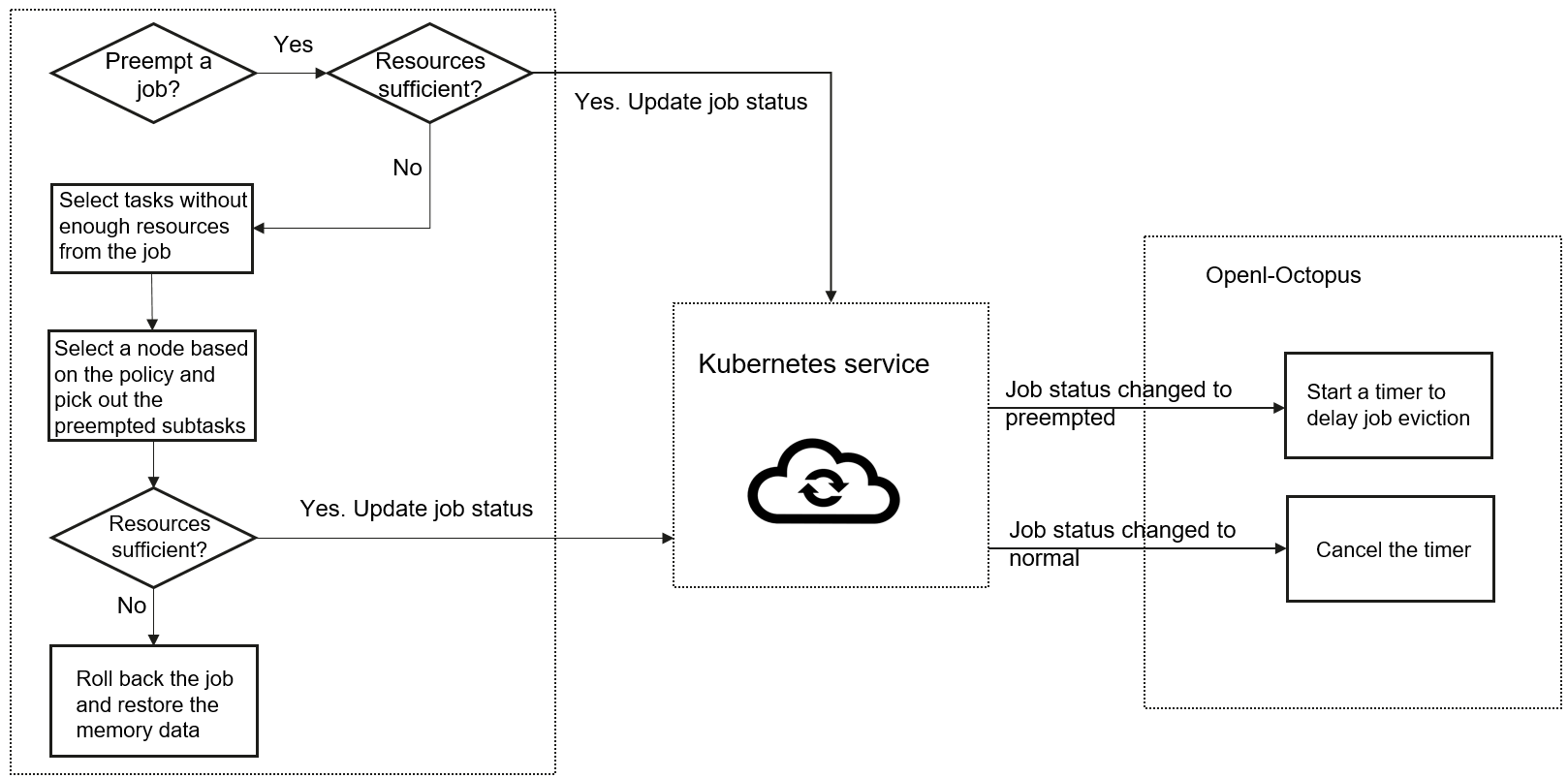
This flowchart shows how the delayed preemption plugin works. On the left is the running logic of the plugin in the scheduler. Kubernetes services lie in the middle, and the right part is the core OpenI-Octopus modules.
Specifically, the plugin finds the jobs that need to be preempted in Volcano. The compute resources occupied by these jobs must be sufficient for the high-priority jobs that are waiting. Then, the plugin updates the states of these jobs in Kubernetes. As soon as the core OpenI-Octopus modules detect the state changes, they start a timer to prepare for eviction of these jobs. If the job preemption is canceled while the timer countdown does not end or because the required resources have been released, the timer is also canceled.
The following chart shows the service logic.

- A Boolean attribute called Preempt is added to each job, indicating whether the job is a preempted job.
- Only jobs with lower priorities in the same queue can be preempted.
- The eviction is performed by job instead of by pod.
-
Pods are evicted based on the ID of the jobs to which the pods belong to reduce the number of affected jobs.
-
The scheduler notifies Openl-Octopus to stop the jobs at the service layer.
- Delayed preemption
-
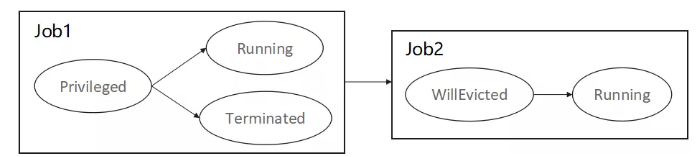
The Privileged and WillEvicted states are added for the job state machine.
-
Jobs in Privileged or WillEvicted state cannot be preempted by other jobs.
-
If the state of a preempting or preempted job changes, the state of the other party changes accordingly.
Benefits
Enhanced capabilities
-
Large-scale distributed training jobs can run efficiently.
-
Multiple AI computing frameworks are supported.
-
Plugin-based scheduler supports customized development to satisfy scenario-specific requirements.
-
Multi-queue scheduling makes possible hardware resource grouping and dynamic resource allocation between groups.
Performance tuning
-
Hardware resource utilization is greatly improved to 90% or higher.
-
The average job scheduling latency is greatly reduced. The average job waiting time is reduced from 60 seconds (using the Yarn scheduler) to 10 seconds (using Volcano).
-
System stability is enhanced, cluster node resources are used in balance, and O&M workloads are reduced.
-
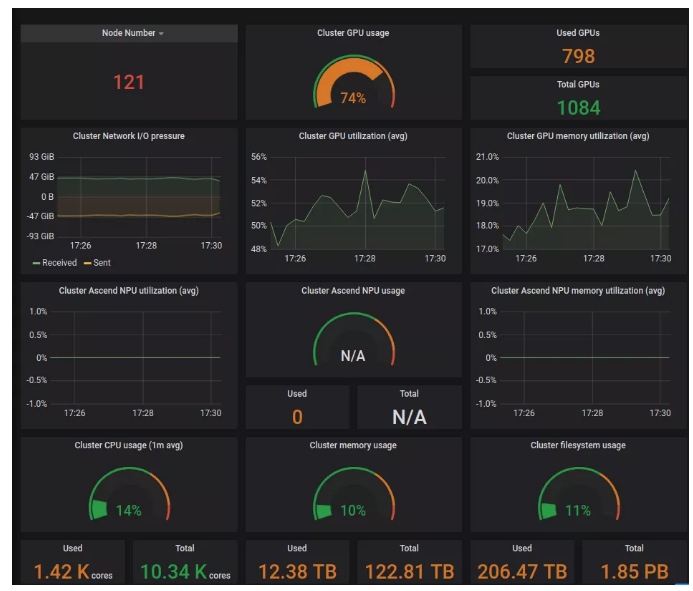
With 120+ nodes managed and 1100+ GPU cards in total, the GPU utilization can reach 90% or higher when the system is overloaded.
-
The resource usage of each node is balanced, and the difference is less than 20%.
-
Since the rollout in 2019, more than 120,000 jobs have been run.