Using Volcano in Large-Scale, Distributed Offline Computing
This article was firstly released at
Container Cubeon December 24th, 2020, refer to锐天投资基于Volcano的大规模分布式离线计算平台的应用实践
Service Scenarios and Solution Selection
Service Scenarios
-
VMs for research and development for policy personnel
-
AI training and inference
-
Data ETL
-
General-purposed, distributed batch processing jobs
Why Use Kubernetes?
A distributed batch processing platform can be used to manage compute and storage resources. In this use case, Ruitian decided to use Kubernetes to manage compute resources due to the following reasons:
-
Containers streamline development for users in different environments. Ruitian has four to five groups of users who use different development environments and policies. Environment isolation posed a great challenge to resource management and development efficiency. Now with containers, environments are encapsulated in containers that can be scheduled using Kubernetes.
-
Heterogeneous devices such as GPUs can be supported through Device Plugins.
-
Data storage can be centralized by using etcd.
-
Kubernetes has a robust technology ecosystem.
-
The Go language complies with the technology stack in Ruitian.
Why Use CephFS
CephFS is a type of distributed file storage interface provided by Ceph. Ceph provides three types of storage interfaces: S3, block storage, and CephFS. The reasons for using CephFS are as follows:
-
Posix Filesystem permission and interface: Local file systems are widely used in our businesses and CephFS provides stable file system mounting. In multi-tenant scenarios, each user has a UID, and the data of each user can be accessed only by themselves. Posix Filesystem provides a permission mechanism that allows users to seamlessly migrate their file permissions to SAP.
-
Strong consistency: A file written to node A can be directly read on node B.
-
Small file access at scale and high-bandwidth I/O
-
Hierarchical hardware support
-
Kubernetes ReadWriteMany PV
Why Volcano
Why not default-scheduler
Ruitian did not choose the default-scheduler, because it cannot provide queue scheduling, fair scheduling, multi-tenant isolation, and advanced scheduling policies such as gang scheduling. Fair scheduling and advanced scheduling policies are the most important factors. Fair scheduling decides which job to run first when there are too many jobs in a queue or when the cluster has available resources. To achieve this, each queue must be mapped to a team, and each namespace must correspond to a user. The default-scheduler cannot meet the preceding requirements.
Another option was kube-batch, a batch processing scheduler of the community. However, it is only a scheduler and does not provide any solution other than scheduling. What Ruitian needed was a batch processing solution that takes care of scheduling and processing for the environment and CRDs.
Why is Volcano
-
Supports fair scheduling.
-
Supports advanced scheduling policies, such as gang scheduling and binpack.
-
Supports mutual access between pods through SSH plug-ins.
-
Supports injecting job dependencies to pods via ENV plug-ins and supports Tensorflow Worker Sharding.
-
Provides services externally via SVC plug-ins.
Such a scheduling platform can satisfy Ruitian.
System Architecture
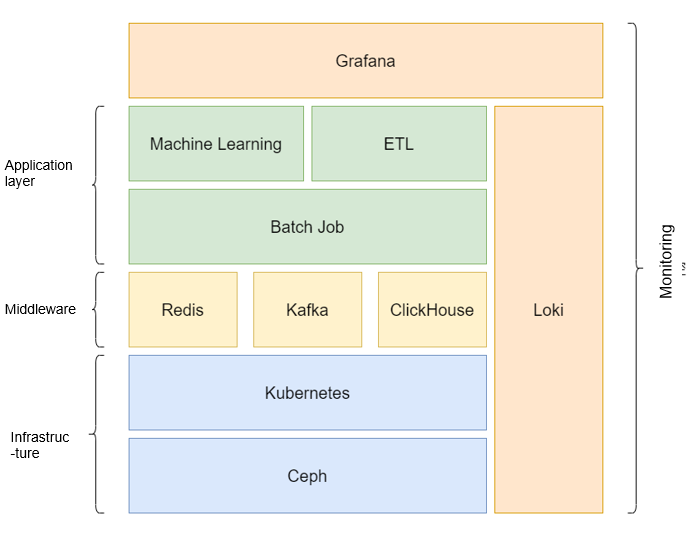
Service Architecture
-
Ceph-based high-performance storage
-
Kubernetes-based heterogeneous hardware management
-
Loki + Grafana for user and monitoring panel
-
Hybrid deployment of middleware and application layer, making full use of cluster resources
-
Extended service scenarios with Batch Jobs
Multi-tenancy
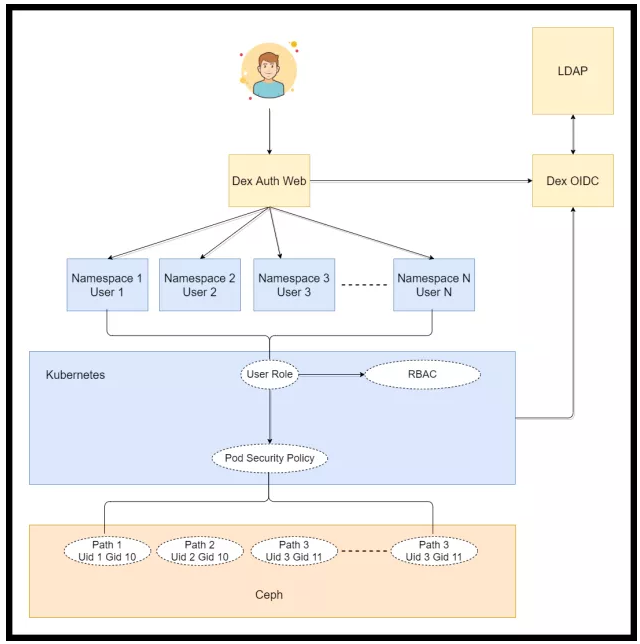
When a user submits a job, multi-tenancy can be a problem. For example, when a user adds a pod to a cluster, the cluster needs to know the running user and the UID. By default, the UID of a running user is that of the image builder, which means the UIDs of the pods submitted by all users can be the same. This is not allowed because the data obtained and generated by a user should not be accessible to other users.
In this case, Ruitian uses Kubernetes namespaces to isolate all resources. One namespace corresponds to one user. Namespaces interconnect with the development information through the existing LDAP service and OIDC to authenticate users and authorize them through RBAC to use pod security policies (PSPs). A PSP requires users to specify UID and GID in SecurityContext when submitting a pod to a cluster. The entire runtime environment of the user is subject to these settings.
With PSPs, users can be isolated when accessing data, which is all stored in Ceph. Multi-tenancy is thereby easily managed.
Workflows
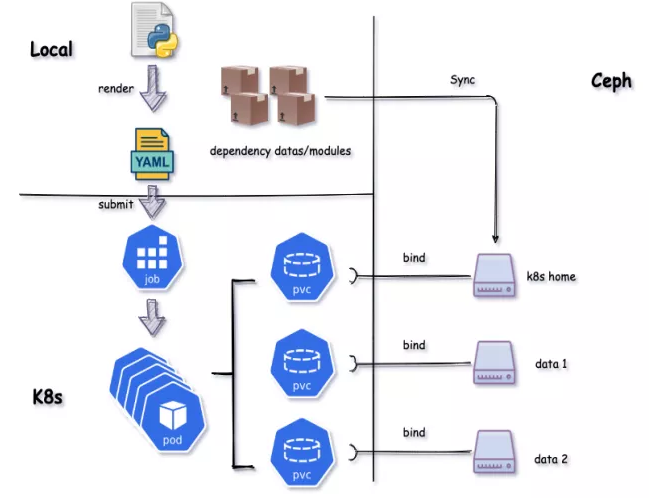
What comes next is basic workflows. The local configurations are rendered into a job YAML and then submitted. All dependency data of the user is synchronized to CephFS, and the pod is mounted with a PVC. Each user has the PVC permissions of their own directory in their own namespace. The permissions are managed and controlled through IBS. In this way, jobs are submitted to the cluster to run.
In-depth Customization on Volcano
In the basic submission framework, Ruitian provides libraries for users and is developing a submission tool, Jobctl. This tool can be used as a command line tool or as the Python list that is input to the notebook or directly to the Python script of the user. Jobctl supports asynchronous and synchronous submissions. In the asynchronous mode, jobs are continuously submitted to the entire cluster. After the jobs are submitted, Jobctl exits directly. In the synchronous mode, Jobctl submits and watches jobs, and returns the execution results to the user only after the jobs are complete.
With Jobctl, Kubernetes complexities can be shielded for users. In addition, command line submission and Python Lib integration are supported, and the most basic parallel execution by replicas and by day is provided.
OOM Auto Scale Up
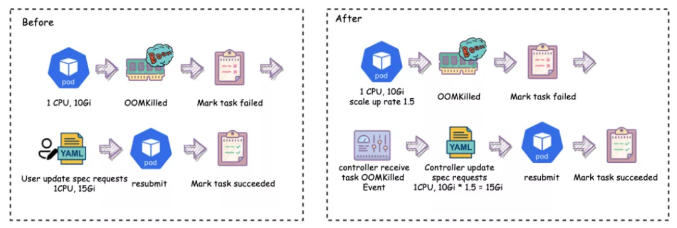
The first customization is to scale up resources of the entire job during OOM. Users may not be able to configure the exact memory required, and need to submit the job again for verification after the OOM. Therefore, Ruitian customized OOMKill Auto Scale-Up to modify the Volcano Controller to automatically scale up the resources requested by the OOMKill pods. After the scale-up, the jobs are automatically submitted again. The user will be informed upon the successful submission. This function guarantees reasonable memory requests without manual intervention, combining the Volcano policy event mechanism mentioned above.
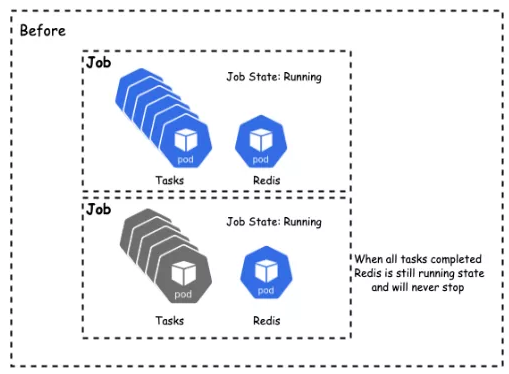
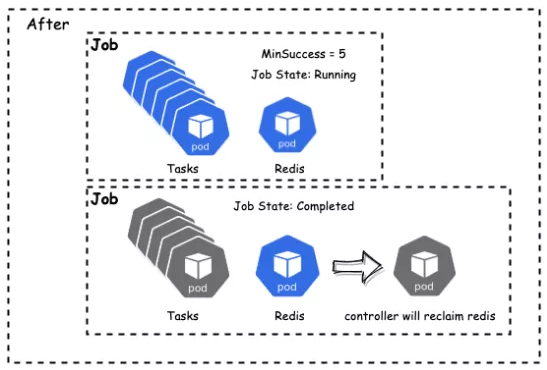
MinSuccess
-
If the number of pods that run to completion reaches minAvailable, the job is complete.
-
Non-Gang jobs cannot be flexibly scheduled.
-
If the number of pods that run to completion reaches minSuccess, the job is complete.
-
Decouple the number of jobs required by Gang and the number of jobs required for completing Jobs.
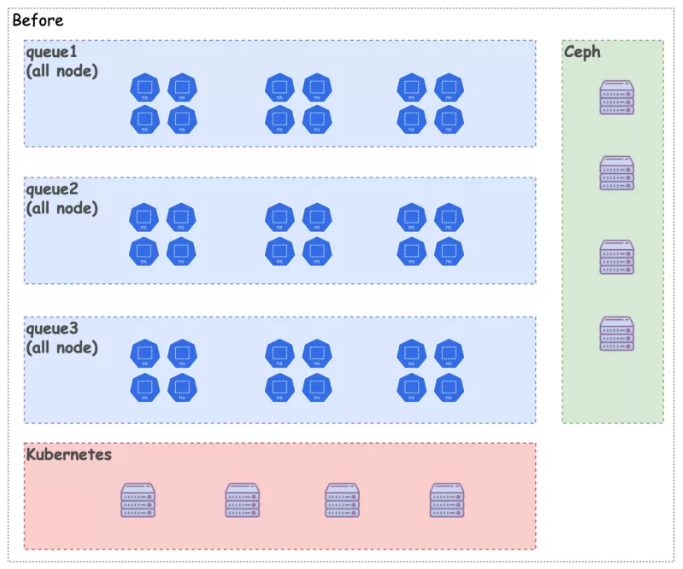
NodeZone
-
One Volcano instance manages all nodes.
-
Noisy Neighbor cannot be resolved.
-
Resources cannot be reserved for emergency.
-
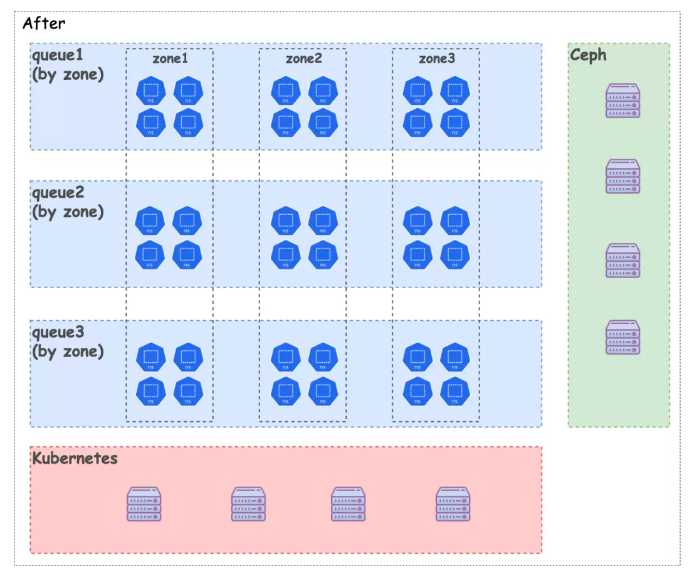
Multiple Volcano instances manage multiple zones.
-
Certain jobs are physically isolated.
Volcano Namespace Quota
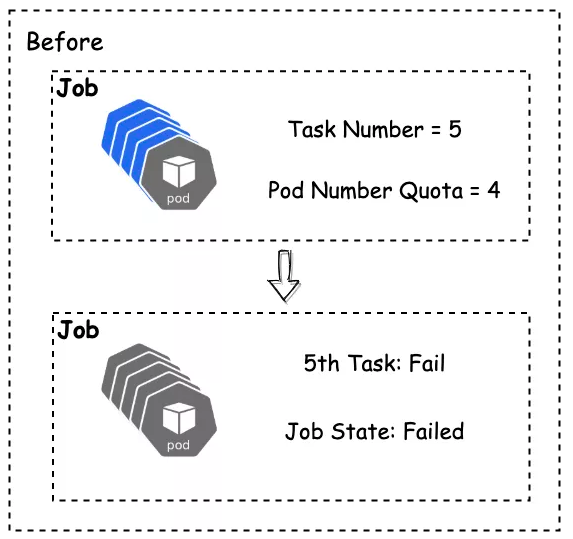
The default Kubernetes quotas cannot satisfy Ruitian's system. When the native namespace quota is triggered, pods directly fail. Therefore, Ruitian re-designed the quota in Volcano.
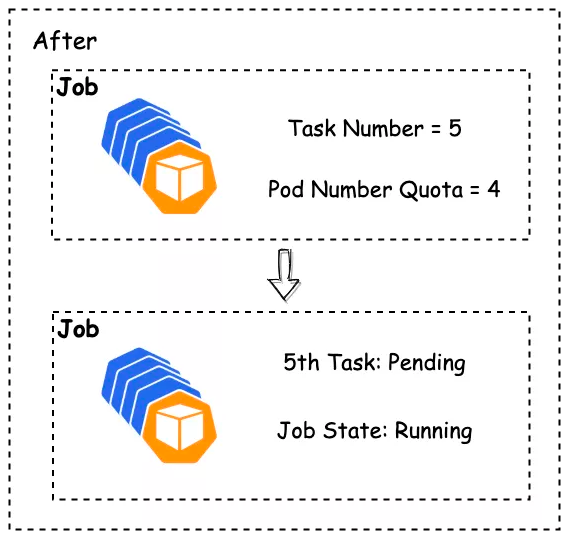
- When the Volcano namespace quota is triggered, pod creation in a queue will be suspended.
Volcano Monitoring and Alarming
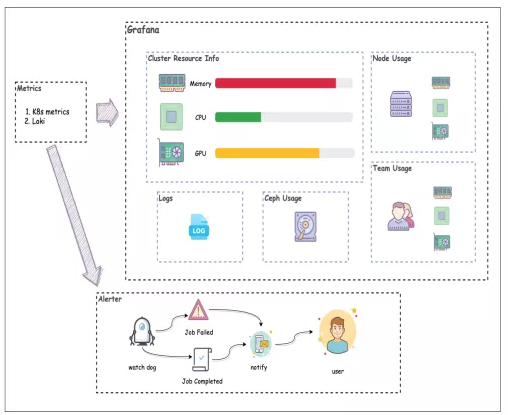
Volcano Exporter
-
Outputs the queue label of the job.
-
Outputs the queue capability.
-
Outputs the job start time and end time.
WatchDog
-
Registers the Informer and collects metrics.
-
Reports job failure and usage alarms.
-
Automatically updates the queue capability.
Job dashboard
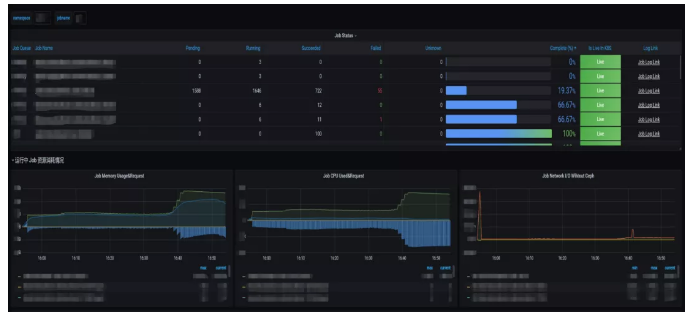
The upper panel covers the information about all jobs and provides a state table to display the job completion status. The panels below display the CPU, memory, and network resource usage. The negative axes refer to wasted cluster resources, which are allocated to pods (jobs) but not actually used during job running. These time series tables can provide resource insights to users in real time.
Cluster resource dashboard
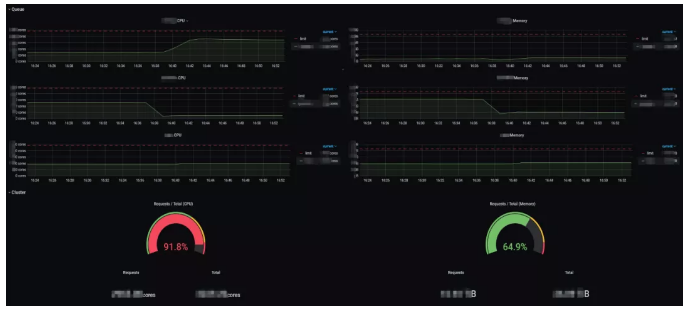
Graphs show the usage of overall queue resources, including CPU and memory. For jobs that consume a large amount of resources, for example, 300 or 500 GiB of memory, users need to know whether there is any node that can run such jobs. Therefore, we need to display the resource usage of each node available.
Challenges and Solutions in High-Concurrency Scenarios
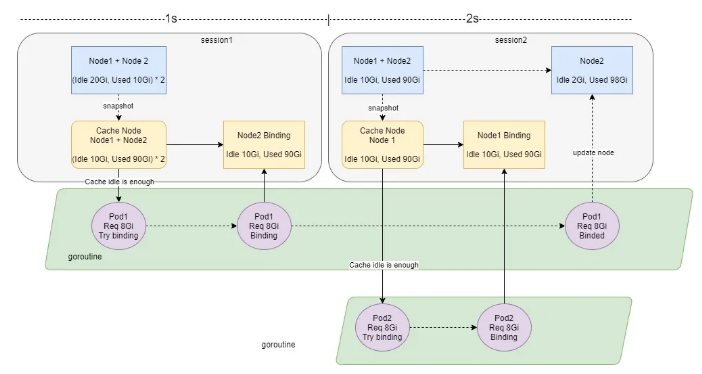
In Ruitian, the number of compute nodes in a single cluster has reached 200 and long-time jobs (1 week) and short-time jobs (1 minute) co-exist. The total storage capacity is 1.5 PB, the read/write bandwidth is 15 GB/s, and the number of pods increases by 100,000 to 300,000 every day. These brought challenges.
Challenge 1: Too Large Jobs

Issues:
-
The CPU usage exceeds Max Request Size (1.5 MB) of etcd when there are a large number of pods.
-
Adjusting Max Request Size will impact etcd due to a large number of objects.
Solution:
- Submit a job in the form of multiple replicas for a single task.
- The information provided by ENV plug-ins in a pod is read in Sharding mode.
Challenge 2: Out of CPU/Memory
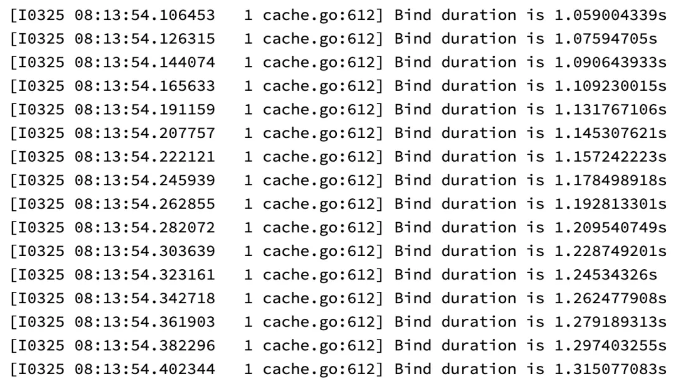
Issues:
-
There are a limited number of nodes, and a large number of short-term jobs keep being scheduled.
-
Kubelet PLEG is under great pressure, and the pod binding takes too long.
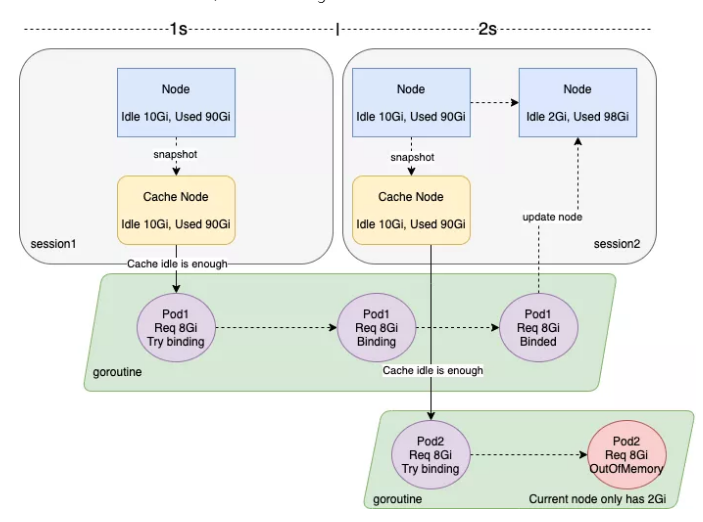
Issues:
-
There are a limited number of nodes, and a large number of short-term jobs keep being scheduled.
-
Kubelet PLEG is under great pressure, and the pod binding takes too long.
-
The default session interval of Volcano is 1s. As a result, cache snapshots are inconsistent.
-
Out of CPU + Out of Memory
Solution:
-
Add binding task numbers for nodes.
-
When a snapshot is being created for a session, the nodes whose binding task number is smaller than 0 are skipped.